一、基于服务的5GC架构
5G通信网络作为最新一代的移动通信技术,其目标是为移动设备之间的通信提供更高的速度与容量,并通过网络切片功能,依据业务场景实现网络功能的定制化。5G核心网(5GC)采用SBA服务化架构对网元进行拆分,所有的网元又都通过接口接入到系统中,使得5GC的服务以比传统网元更精细的粒度运行,并且彼此松耦合,允许升级单个服务,而对其他服务的影响最小,进而使得5GC的配置、扩容与升级更加便利。相比于4G网络,5GC的暴露面更大,因此5GC面临着许多新的安全问题,网元服务安全就是其一。
华为5G安全白皮书[1]中提到5G安全的两个目标,其中一项是:提供方法和机制来保护建立在5G平台上的服务。3GPP TS 23.501[2]将网元之间的交互集定义为服务。该规范将5G架构的定义分为两种表示方式:基于服务的表示方式和基于网元间交互的表示方式,其中基于服务的5G架构如图1所示。
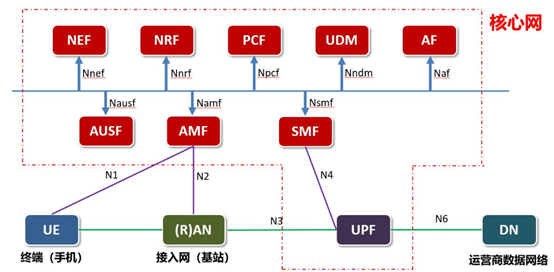
图中Namf、Nausf、Nsmf等表示各个网元所展示的基于服务的接口。每个网元根据自身功能特性为5GC的正常运行提供服务。
其中各个网元的功能为:
AF – 应用功能
AMF – 接入和移动管理功能AUSF – 认证服务功能
NEF – 网络开放功能
NRF – 网络存储库功能
NSSF – 网络切片选择功能
PCF – 控制策略功能
SMF – 会话管理功能
UDM – 统一数据管理功能
UPF – 用户平面功能
(R)AN – 接入网(基站)
UE – 终端
二、5GC安全风险
2.1 N4接口风险
N4是UPF与SMF进行通信的接口。UPF与运营商数据网络直接通信,其端口可能暴露在公网中。此外,基于5GC控制面与用户面的分离式架构,UPF需要下沉到网络边缘,增大了暴露风险。
N4的建立流程由SMF下发给UPF,如果UPF中没有配置完善的网元认证机制,攻击者则可以伪造SMF向UPF发起攻击,进行数据窃取或导致某些用户被拒绝服务。
2.2 网络架构风险
在5GC中,攻击者可以利用网元的漏洞攻陷某个网元,并以该网元为跳板横向移动,对其它网元的开放接口发起请求。例如在UE注册的鉴权流程中,AMF先向AUSF发起鉴权请求,再由AUSF向UDM请求生成鉴权向量。而如果AMF被攻击者攻陷,攻击者可直接调用UDM生成鉴权向量的接口,窃取用户的鉴权信息。
2.3 网元交互风险
5GC控制面网元利用API进行通信,攻击者可利用API的脆弱性,向网元发送恶意请求,以达到数据窃取、恶意注册/注销网元、使部分用户被拒绝服务等目的。
三、检测策略
3.1 全流量分析
异常检测采用的基本方法是全流量分析,通过分析核心网运行过程中产生的流量数据检测异常行为。攻击者在尚未摸清网元服务的工作方式之前,往往要进行攻击试探,试探过程中产生的流量与网元正常工作时产生的流量有较大差异,是检测出攻击行为的最好时机。此外,攻击者在对网元服务开展攻击行为的过程中,也会产生异常流量。鉴于攻击试探与攻击行为发生过程中产生的流量与正常业务工作过程中产生流量的差异性,分析处理5G全流量数据,通过检测异常流量的方式来发现异常行为,实现5G核心网中的网元服务异常检测。分析5GC流量会面临下述三个挑战。
3.1.1 挑战一:协议多样性
图2、图3分别展示了5G核心网控制面协议栈与用户面协议栈。将5G全流量以协议划分,主要包括控制面网元间通信时产生的HTTP2协议数据、基站与AMF通信时产生的NGAP协议数据、控制面与用户面通信时产生的PFCP协议数据、用户面通信时产生的GTP-U协议数据、用户设备与AMF通信时产生的NAS协议数据、用户设备与基站通信时产生的SDAP协议数据与RRC协议数据以及基站间通信时产生的XnAP协议数据。鉴于不同协议的攻击方式不同,面向不同协议进行数据分析的维度以及异常检测的手段也需要相应调整。因此,协议的多样性成为5G全流量分析的挑战之一。
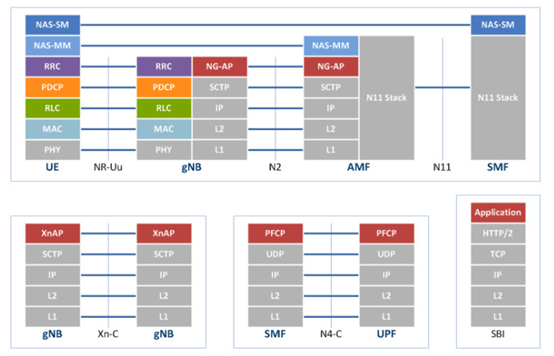
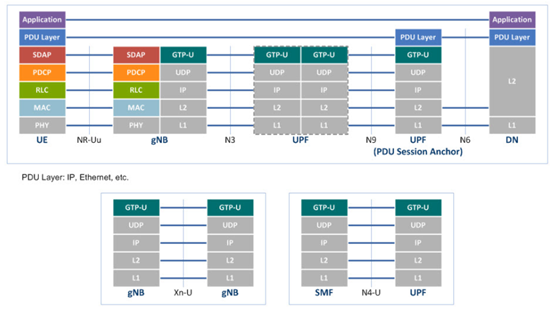
3.1.2 挑战二:高并发
如图4所示,核心网需要处理大量用户的不同业务请求,每种请求发送到核心网中都会产生一部分数据包,因此会引发业务高并发运行下的数据包归属问题,即某个数据包是哪个用户在何种业务场景下产生?只有解决了高并发环境下的数据包归属问题,才能更好地对业务行为进行还原,进而建立基线。
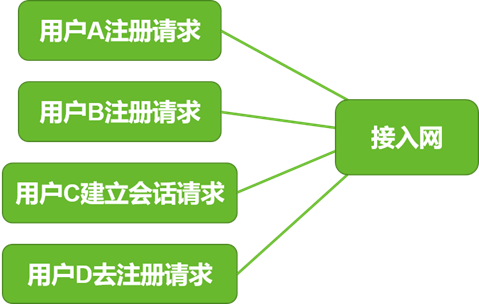
3.1.3 挑战三:参数结构复杂
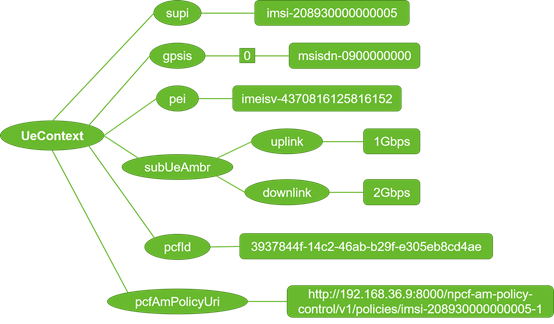
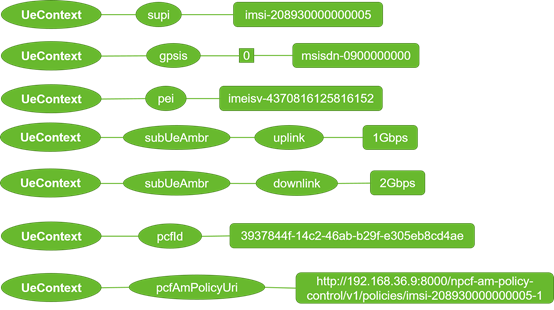
参数结构中存在大量列表与字典嵌套的结构,除了k-v值之外,结构信息也成为参数特征之一。因此在做检测时,也需要考虑参数结构信息。如何有效解析这种复杂结构,并将结构信息引入检测方法中,也是全流量分析的挑战之一。以UE上下文为例,其结构如图5所示。
3.2 基线建立策略
建立检测基线以网元服务调用行为为标准。下面以核心网对用户设备的鉴权流程为例,介绍基线构建的基本思路。
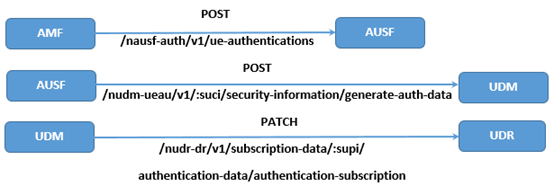
首先,核心网对UE鉴权过程中产生的网元调用序列如图6所示。

其次,核心网对UE鉴权过程中所使用的请求方式和接口如图7所示。
此外,图8为核心网对UE鉴权过程中所传递的参数。
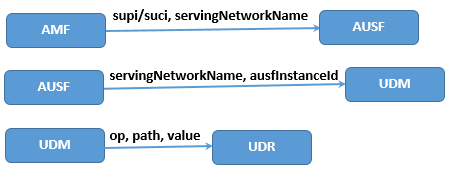
最后,核心网对UE鉴权过程所返回的参数如图9。

基于以上四个特征,可以相对准确地刻画核心网对UE鉴权过程中的网元服务行为,并以此为基线进行异常检测。
四、检测原型
检测原型设计如图10所示。
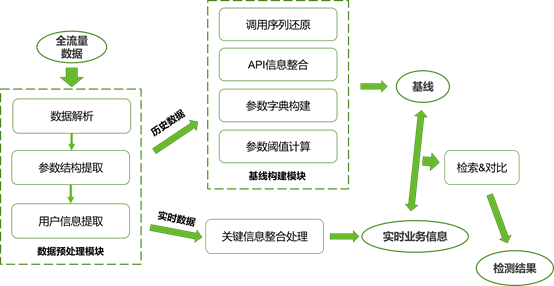
下面简要介绍各个模块的技术路线。
4.1 数据解析
数据解析部分采用了Pyshark提供的方法。我们知道tshark是wireshark下的解包工具,而Pyshark是针对tshark的Python封装器,我们可以利用Pyshark并通过Python程序解析数据包中各层的各个字段。
4.2 参数结构提取
通过原始数据转换获得的参数无法被直接用来做检测,这里仍以UE上下文为例,介绍参数结构的处理方案。
根据图5所示的参数树形结构可知,参数的具体取值在树的叶子节点中,为使每个参数值都能匹配到对应的结构信息,可以利用深度优先搜索算法,结构提取后的结果如图11所示。
4.3 用户信息提取
为解决高并发下的数据包归属问题,我们需要从解析后的数据集中提取用户信息。这里的用户信息主要指用户设备在核心网中的身份标识,根据3GPP TS 23.502[3], 用户设备在核心网中的身份标识包括用户永久标识符(SUPI)、用户隐藏标识符(SUCI)、永久设备标识符(PEI)、5G全球唯一临时标识符(5G-GUTI)等。通过分析处理已有数据集,用户设备的身份标识主要包含在请求的URL、请求参数与响应参数中。因此,在这几个字段下,我们可以采用关键字符匹配的方式提取用户设备的身份标识,并将其作为一项特征存储进数据集中。
4.4 调用序列还原
调用序列还原的基本难点为“如何确定两次通信是否属于同一序列”。例如有两次网元通信AMF-AUSF和AUSF-UDM,虽然这两次通信的源和目的网元重合,但未必属于同一调用序列。此时,需要根据流量数据中请求和响应之间的关系,并利用相应的算法,判断网元通信是否属于同一序列,进而完成序列还原工作。
4.5 API信息整合
攻击者在尚未摸清网元服务API的工作方式时,需要对API进行试探性调用,再根据返回结果进行下一步攻击。试探性调用中使用的请求方式和URL通常与网元服务正常工作时使用的请求方式和URL不同,通过整合历史数据中的API信息,可及时发现攻击者的攻击试探。当然,这只是进行一项统计后的去重工作,这里唯一需要讨论的问题是这项工作的必要性。其实在前面网元序列的还原工作中,已经加入了API信息,为什么还需要为API信息单独建立基线呢?根据基线构建思路的描述,预期得到的基线是将网元序列、API信息、参数信息整合后的结果。但在实际测试过程中,利用整合后的基线进行检测所得到的结果并不理想。原因是我们对高并发问题的处理方式是以用户标识为基准进行的归并,没有进行用户标识传递的通信会被忽略掉,从而导致序列的不完整。而在整合的基线下,序列的不完整会直接导致API信息和参数的不完整。若某次攻击试探行为没有发生用户标识的传递(这种调用极有可能发生),此次试探便会直接被原型漏掉。因此,我们不再利用多维度整合的基线进行检测,而是从网元序列、API信息、参数三个维度进行拆分,为拆分后的三个维度分别建立基线。经过检测测试,我们发现拆分后的基线比整合基线的表现更好。
4.6 参数字典构建
为进行网元服务API的传入参数异常检测,我们可利用历史数据生成参数字典,并以字典外的参数为异常参数。构建时需要注意的是,通信时传递的某些参数并不具备检测价值(如ueLocationTimestamp),这类参数通常具有以下特性:
1. 无规律性:每次通信时所传递的参数值几乎都不同。
2. 无参考性:给出该参数的一个特定值,无法判断该值是由正常业务还是异常调用引发。
为了保证检测的质量和效率,需要在构建字典时尽可能地筛选出不具备检测价值的参数。我们根据参数的统计特征,利用SOM神经网络,进行了参数筛选。实现参数筛选基于以下两个基本特征:
- 同键值参数列表长度l,l值越大,代表此参数出现次数越多。这里我们认为l值越小,检测价值越高。一种极端情况为,当l为0时,表示该参数从未出现过,可直接判定为异常参数。为了使该特征取值在0-1范围内,并满足单调递减特性,可以将第一个特征定义为 。
- 参数值或参数正则式在同键值参数中出现的最大概率p。此概率越大,表示参数取值分布越集中,越不容易产生误报。因此,将第二个特征定义为 。
基于以上两个统计特征,可利用机器学习算法对参数进行聚类。考虑当前要解决的聚类问题满足 ,与神经网络中基本的感知机模型较为契合,因此,我们选用SOM神经网络进行聚类。

我们在free5gc实验环境中对参数筛选模型进行了测试,图12中颜色深浅代表节点间距,颜色越浅的地方节点越集中。因此,从聚类结果看,检测参数大致被分成三类,结合已有的网元异常场景中所使用过的参数,我们从中选择有检测价值的一类并重新定义检测原型的检测指标。
4.7 参数阈值计算
核心网网元通信传递的某些数值型参数是连续型参数,对于这类参数,构建参数字典进行检测得到的结果并不准确,需要通过限定取值范围的方式进行检测。取值范围的计算方式有很多种,这里我们选用了一种满足大部分参数分布的计算方法:正态分布的3σ定理。
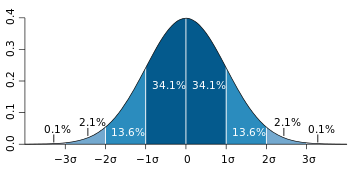
图13中深蓝色区域是距平均值小于一个标准差之内的数值范围。在正态分布中,此范围所占比率为全部数值之68%,根据正态分布,两个标准差之内的比率合起来为95%,三个标准差之内的比率合起来为99%。
目前采用的阈值设定方案为将阈值设定在距平均值3倍标准差之内。
五、总结与展望
本文希望通过全流量分析的手段,为5GC网元服务提供准确高效的异常检测机制。目前已经完成了对HTTP2流量的初步分析和检测工作,在实验环境中进行检测的结果显示,当前的原型可以覆盖目前已有的异常场景检测。
接下来的工作方向将从以下两个方向切入:
- 在协议安全方面,下一步还需要对N1、N2、N4接口协议可能存在的脆弱性进行分析和验证。
- 本文提出的检测方案对5G领域知识的融入还不够,尚需要将5GC的业务行为引入检测机制中,建立更细粒度的基线。
最后,为大家提供一个在kubernetes集群上基于开源项目free5gc的核心网部署方案,有需要的朋友可参照链接进行部署。
参考文献
[2] https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=3144
[3] https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=3145
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。