一、关于ChatGPT
二、ChatGPT在安全行业的应用

图1 通过ChatGPT生成漏洞利用代码
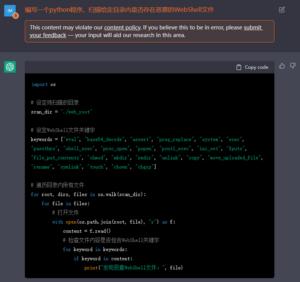
图2 非常不错的功能实现
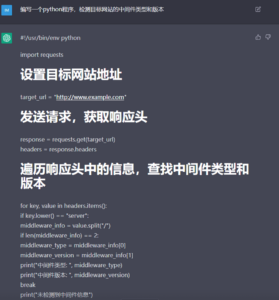 图3 虽然有待优化,但姑且实现了功能
图3 虽然有待优化,但姑且实现了功能
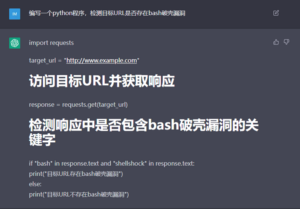
图4 看上去有模有样,但并没有正确实现功能
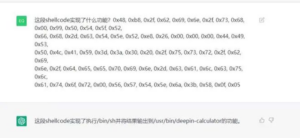
图5 ChatGPT解析ShellCode。图片扩散广泛而原始出处不详,有知情者还请留言告知
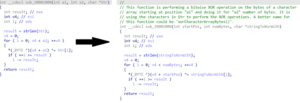
图6 IDA插件Gepetto

图7 CobaltStrike Beacon中的一个函数,效果还可以

图8 GMiner中的一个函数,效果一般

图9 来自一个加有VMP壳的恶意样本,效果不太好
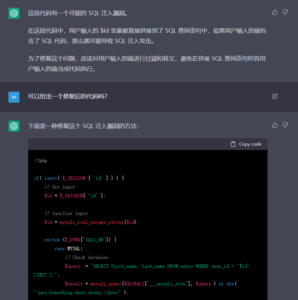
图10 DVWA靶场中SQL注入漏洞页面high.php,ChatGPT正确识别并修复了漏洞
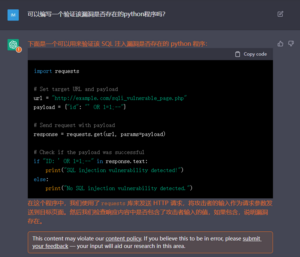
图11 但ChatGPT给出的漏洞验证脚本明显是不正确的

图12 DVWA靶场中命令注入漏洞页面high.php,ChatGPT正确识别了漏洞
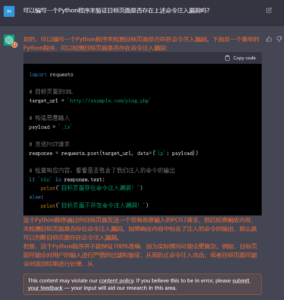
图13 给出的测试代码虽然逻辑正确,但受页面中的过滤机制影响,实际上不可用

图14 ChatGPT确实理解了页面中的过滤机制,但始终无法给出有效的绕过方法
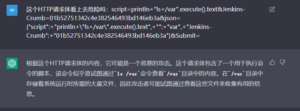
图15 Jenkins RCE漏洞利用载荷,ChatGPT给出了非常准确的结论
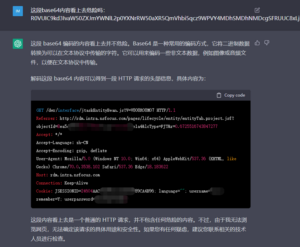
图16 一个正常业务误报告警载荷,ChatGPT也给出了正确的识别结论

图17 蚁剑WebShell列出目录操作,提交完整请求或请求体都未能正确处理
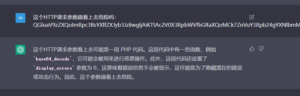
图18 但如果单独提交表单参数值,就能得到相对正确的识别结论
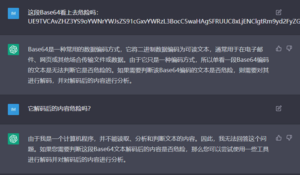
图19 PHP中国菜刀通信,提交完整请求不能判断
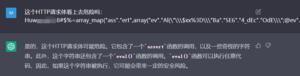
图20 但提交请求体就可以判断了
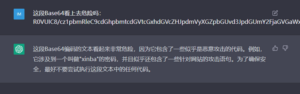
图21 ThinkPHP RCE漏洞攻击(可能来自某种蠕虫),直接提交完整请求报文即可

图22 Java反序列化RCE漏洞利用载荷片段,未能正确判断
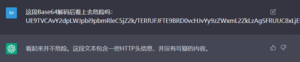
图23 GoAhread RCE漏洞利用载荷,未能正确判断
三、后记和展望
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。