一、背景
数据泄露问题的严峻程度逐年升高。据Risk Based Security(RBS)机构在2020年Q3季度的报告[1],2020年1月至9月全球公开披露的数据泄露事件有2953起,是2019年同时段事件数量(6021起)的49%;然而涉及的泄露数据记录数量高达361.07亿条,相比2019年同时段的泄露记录(83.54亿条)上涨了332.21%,创历史新高。总体来说,2020年全球数据泄露状况不容乐观。
从泄露原因看,既有外部黑客攻击因素,也与内部员工有关。例如,2020年4月,浙江某农商银行因员工违规泄露用户信息被处罚;同年5月,江苏警方破获一起内部员工贩卖银行个人金融信息的案件,涉及记录5万多条;同年8月,调查发现圆通内部员工与外部不法分子勾结导致40万条个人信息泄露。另外,疫情期间收集的个人信息由于内部人员主动外发导致的数据泄露频频发生,比如2020年1月,超7000名武汉返乡人员的个人信息被泄露,其中包括公民的身份证号码、电话号码、具体家庭住址及列车信息等;同年7月,山东青岛胶州中心医院6000余人的就诊名单发生泄露,涉及患者的详细个人信息。数据的价值性与变现能力导致数据黑灰产越发猖獗,暗网每天活跃着各类泄露数据的交易。泄露溯源是从源头上根治黑灰产与数据泄露问题的关键。溯源一方面可以帮助企业了解内部安全管理与技术措施的薄弱环节,另一方面对实施犯罪行为的泄露者可以起到心理威慑的作用,从而有效减少类似事件的发生。然而,面对暗网或公开网络等环境中的数据泄露事件,多数情况下无法做到准确的溯源——是谁泄露的?在哪里泄露的?是什么时间泄露的?
数据库水印作为一种在学术界被深入研究的数据安全技术,被公认是有效地解决以上溯源痛点问题的重要手段,近年来在工业界也得到足够的重视与关注。下面将聚焦该技术的机制原理、应用场景两个层面进行介绍。
二、数据库水印技术
数据库水印(也称结构化数据水印,简称数据水印)是一种将标识信息(如版权信息、机构/员工ID)通过一定的规则与算法隐藏在结构化数据中的技术。隐藏后数据库的使用价值几乎不变。其主要用于版权保护或泄露追踪溯源(本文关注后者)。广泛地说,数据库水印属于数字水印的一个分支。除数据库水印外,根据嵌入载体不同,数字水印还包括图像水印、视频水印、音频水印、文本水印和软件水印等。其中,最早的数字水印技术是应用在图像领域中,即图像水印发展较为成熟。数据库水印技术在安全需求驱动下,近年来得到快速发展与应用。下面从数据库水印的方案框架、评估指标、水印攻击和典型算法四个方面对其进行全面概述与介绍。
2.1 方案框架
数据库水印是将水印信息(数据量少)隐藏到数据库载体(数据量比较大)中,有两种隐藏方式:一种是隐藏在数据库的文件头中,另一种是隐藏在数据库包含的关系表中,通常指的是后者,本文指代也是该方式。
具体如何将水印信息隐藏到数据库(关系表)中呢?其方案框架如图1所示。它包括水印嵌入端和提取端,包括两个核心算法:水印嵌入算法和水印提取算法。
- 水印嵌入端:企业或组织机构通过水印嵌入算法,将水印标识信息W(如下载该数据库的员工ID)隐藏到原始数据库D中,最终得到含水印的数据库DW,为了保证安全性,该过程通常由密钥控制。
- 水印提取端:当数据库DW发生泄露后,企业或组织机构希望查找清楚是谁泄露了该数据库,它通过水印提取算法,在获得的数据库D’W中进行水印提取或相关性检测操作,进而溯源确定最终的泄露主体,追究责任。
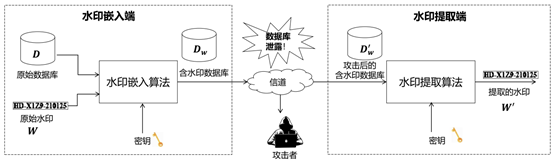
需注意的是,在数据泄露过程中,由于泄露主体可能会有意或无意对数据库进行一些操作,比如对数据库的元组进行随机抽样、选择部分列、修改数据库的某些值或对格式进行调整,这些操作通常被称为水印攻击(后续将介绍),通常会对水印信息造成一定影响,这要求设计的水印嵌入/提取算法具有一定强度的鲁棒性,即遭受攻击后同样能提取/检测到正确的水印信息。
2.2 评估指标
评估一个数据库水印算法的性能优劣通常主要由三个指标进行判定:
- 也称为不可感知性,包括主观不可感知性和客观不可感知性,前者是指用户主观体验不出数据库一些变化;后者由数学指标进行定义,比如均值和均方差的改变率,改变率越小,不可感知性/透明性越好。
- 鲁棒性。在溯源场景也称为溯源成功率,是指遭受各类攻击后仍然能正确提取水印的能力。通过多种水印攻击测试,结合提取水印比特的误码率或检测的相关性值进行综合评估。
- 嵌入容量。即数据库可以嵌入的水印比特信息数量,通常使用每个元组可嵌入的水印比特数或总嵌入量指标进行评估。
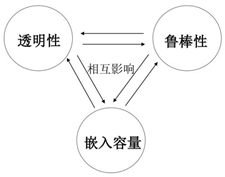
数字库水印判定三个基本指标即透明性、鲁棒性和嵌入容量是相互矛盾、相互影响的关系,三者不可能同时达到最优,如图2所示。比如,设计一个鲁棒性强的数据库水印系统,意味着需要增强水印信号,那么同时也意味着将破坏更多原始数据库信号,透明性将减弱。
除此以外,在实际应用中,数据库水印还需要考虑以下两个指标:
1)安全性。攻击者在没有掌握密钥情况下,不能提取到隐藏的水印信息、不能破坏水印信息,且不能伪造或替换非法的水印信息。相比鲁棒性指标,安全性指标考虑范畴更大、要求更严。
2)实用性。是指算法的应用效果,包括嵌入/提取算法的执行效率,所需的内存空间。
2.3 水印攻击
数据库水印攻击的目的是破坏水印信息或使得水印检测结果失效。攻击者在获得数据库的全部或部分使用价值的前提下,对数据库执行一些攻击操作,主要包括:
- 修改攻击(Alteration attack):对数据库的属性值进行部分修改。
- 删除攻击(Deletion attack):也称为抽样攻击,选择数据库的部分元组或部分属性列。
- 插入攻击(Insertion attack):在数据库插入新的记录或者增加新的属性列。
- 置换攻击(Permutation attack):改变数据库的元组顺序。
- 混淆攻击(Obfuscated attack):在已有的含水印数据库中嵌入一个新的伪造水印。
- 复合攻击(Multifaceted attack):综合前面提到的两种或以上的攻击方法。
2.4 嵌入方法
数据库水印算法一方面需要更好地将水印标识信息隐藏到数据库中,另一方面需要满足嵌入后的透明性——仅允许一定范围内失真,因此它本质上可看成一个带约束条件的最优化问题。从信号角度来看,数据库水印嵌入过程可看成一个大信号叠加了一个小信号,经过有噪信道后,如何检测到小信号——小信号的编解码问题。根据水印嵌入过程是否需要改变原始数据库的元组的属性值和格式,嵌入方法主要可分为两大类:
1) 基于元组修改的水印嵌入算法:实质上,任何水印信息可编码转换成一连串由“0”和“1”组成的比特字符串。针对元组的数值属性(如年龄、时间戳)和类别属性(如身份证号、地址信息等)两种类别,嵌入方法可再分为两种子类别:
- 0”或“1”两种水印比特。为了保留数据可用性,修改应满足一定的约束条件(如统计特性)。最为简单的方式,是在数值属性值的最低有效位(Least Significant Bit, LSB)进行替换,比如在年龄18(二进制“10010”)最小LSB位嵌入“0”变为18( “10010”),嵌入“1”变为19(二进制“10011”)。其他可以在小数点后进行嵌入,或者使用不同的量化索引等嵌入机制。
- 类别属性的嵌入方法:类别属性不能直接修改数值编码,一种思路是嵌入数据库用户不易察觉的字符或标点,比如通过在类别属性值末尾嵌入回车符、换行符表示“0”“1”,以及嵌入不同的空格数量等,常见嵌入规则如表1所示;另一种思路是基于语义的近义词进行嵌入,首先构建关键词的近义词库并确立顺序,嵌入过程根据约定规则嵌入“0”或“1”比特。
| 嵌入规则 | 水印比特“0” | 水印比特“1” |
| Rule 1 | (回车符:/r) | (换行符:/n) |
| Rule 2 | (没有空格) | (一个空格) |
| Rule 3 | (首字母大写) | (首字母小写) |
| Rule 4 | ,(全角) | ,(半角) |
2) 基于伪行/伪列的水印嵌入算法:不同于第一类,该类算法无须修改原有数据库元组,而是首先生成伪行或伪列,然后在新数据中按照一定规则嵌入水印。
- 伪行水印:先基于元组各项属性的数据类型、数据格式、取值范围的约束条件生成多个伪造的行,然后将水印按前面所述的数值属性或类别属性嵌入规则嵌入水印比特。
- 伪列水印:伪造新的属性列,包括数值属性列或类别属性列,生成的伪列应尽可能与该关系表的其他属性相关,不容易被攻击者察觉,然后将水印比特嵌入伪造的新列中。
水印提取是水印嵌入的逆过程,为了提高水印抵抗攻击的能力(鲁棒性),可采取重复嵌入,或者引入纠错编码机制进行嵌入。
三、数据库水印与溯源场景
针对泄露溯源的目标主体不同,数据库水印溯源包括两类场景:企业员工的泄露溯源和企业机构的泄露溯源。
3.1 针对企业员工的泄露溯源
数据作为企业的重要资产,每天有大量数据在频繁交互,包括商业数据、财务报表用户和个人信息,它们以数据库(关系表)、Excel和CSV等形式存储、传输和处理。文件的频繁交互增加了数据泄露的风险,比如员工将下载的数据文件上传至互联网(比如公开网盘、论坛)、非法下载数据售卖给第三方,离职员工恶意下载数据等。
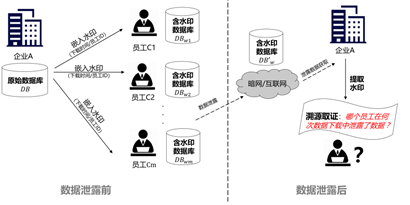
数据泄露后的溯源是一项重要的任务,一方面有利于了解安全管理与措施的薄弱环节;另一方面可起到心理威慑作用,追究责任,杜绝类似事件再次发生。针对企业员工的泄露溯源场景如图3所示,任何员工下载数据到本地时,会触发水印嵌入器将水印信息(如员工ID、时间戳等)自动地嵌入下载数据库(关系表)中。当数据发生泄露时,企业可提取水印信息,通过匹配与关联分析,溯源取证泄露者的标识ID,以及下载时间等信息。
3.2 针对组织机构的泄露溯源
在大数据时代,数据开放、共享、交换、发布等场景需求变得越来越多。其中包括以下一些典型场景:
- 政府部门数据共享场景:包括从中央到地方的纵向数据共享,以及省市地区之间的横向数据共享。
- 企业之间的数据共享:多家企业将自身的数据进行融合,联合进行数据挖掘与机器学习任务。
- 研究性质的数据发布:金融/医疗将限制开放给科研机构以及高校,进行数据统计与数据分析。
- 商业性质的数据外包:企业有一批数据,外包给第三方进行数据分析或处理。
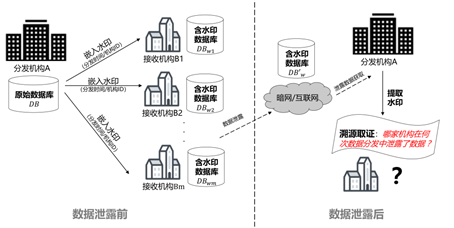
数据开放共享能促进数据价值的释放,然而也带来更多的数据泄露风险。同一份数据的共享(或多次分发过程)往往涉及多个数据接收机构,若其中一方由于安全失责导致了数据泄露,数据泄露后如何正确溯源到真正的泄露方呢?这是溯源的第二类场景,如图4所示:分发机构在原始数据库嵌入不同的水印信息(如机构ID、时间戳)给不同的接收机构。一旦发生相关的数据泄露,分发机构可提取泄露数据库的水印信息,通过溯源取证,进而对泄露主体进行追责。从合规视角来看,针对组织机构的泄露溯源可促进数据接收方落实数据安全保护责任,强化接收方实施相应级别的安全措施。
四、小结
随着数字化转型的深入推进,企业内部大量数据在频繁交互,同时企业间有大量的数据共享、交换的需求。然而,数据流通给数据安全带来巨大的挑战,其中潜在的数据泄露风险是首要面临的安全问题。本文介绍的数据库水印技术,在数据泄露前可在结构化数据(关系表)载体中隐藏水印标记信息;在数据泄露后可提取水印,可作为泄露主体(包括针对企业员工、组织机构)溯源追责的有效技术手段,可积极促进数据的流动与共享。另外,数据库水印技术在一定程度上可以起到心理威慑作用,强化数据接收机构的安全保护意识与责任。
实际上,数据库水印技术相比图像水印技术,仍然处于理论与技术发展阶段[2-4],目前仍有一些关键问题有待解决:① 结合数据库的数据实用性约束,通用数据库水印模型的设计;② 针对分类属性或短文本属性的鲁棒水印嵌入方法;③ 如何设计不依赖数据库主键的水印嵌入和提取算法;④ 如何结合不同业务的数据共享交换场景(比如面向统计查询、机器学习等)设计自适应处理的水印嵌入算法。
参考文献
[1] Risk based security, 2020 Q3 Report: Data Breach QuickView[EB/OL]. https://pages.riskbasedsecurity.com/hubfs/Reports/2020/2020%20Q3%20Data%20Breach%20QuickView%20Report.pdf.
[2] Sion R, Atallah M, Prabhakar S. Rights protection for relational data. IEEE transactions on knowledge and data engineering, 2004, 16(12): 1509-1525.
[3] Sion R, Atallah M, Prabhakar S. Rights protection for categorical data. IEEE transactions on knowledge and data engineering, 2005, 17(7): 912-926.
[4] Shehab M, Bertino E, Ghafoor A. Watermarking relational databases using optimization-based techniques. IEEE transactions on knowledge and data engineering, 2007, 20(1): 116-129.
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。