一 . 海量攻击数据的拟合实践
1.1 传统拟合手段
这里我们先以防御 SQL 注入为例,来讲述目前 WEB 防护的几 种防护手段。因为 SQL 注入可以说是目前大家最为关注的 WEB 安 全防护功能之一,用作对比对象非常的适合。就目前防御 SQL 注入 攻击的算法,大致可以分类为正则表达式检测方法和语义分析检测 算法。
1.1.1 正则表达式检测方法
正则防护是传统检测引擎普遍使用的防护方法,通过使用正则 表达式来识别攻击语句,有着悠久的攻与防的历史。通过正则表达式, 安全防护设备能够迅速完成对规则的增删改,来响应突发问题。但 是这种检测方式有着先天性的几大问题。
第一个问题是维护成本高、用户体验差。正则检测是一种非常 考验正则编写者对于攻击理解的检测方式,所以它强依赖于编写者 的安全功底。如果编写者对于攻击内容以及相关的边界知识不甚理 解,那么编写的防御正则很有可能被多种方式绕过。而且正则检测 所积累的规则是一个线性增长的过程,这个过程是趋于无限的。那 么在这无限的规则中,很难保证规则之间不出现冲突。这就有可能 出现,一个防护规则由于与另一个新加入的规则冲突,从而导致失 效的尴尬境地。这样东补一下,西补一下的状态,最终将自己置于一 团乱麻当中,无法解脱。还有就是,客户在面对上百条的规则时应 该如何选择,怎么选择才能达到最优效果。
第二个问题就是易绕过。正则表达式的编写完全依赖于人的编 写,而人的认知都是主观且存在盲点的。即便编写者是一个高级安 全研究者,他也有一些未知的盲点,同时编写过程中也会受限于正则语法,很难比较完整的覆盖整个攻击结构,而且还需要考虑到误报 对正常业务的影响。
第三个问题是误报高。由于正则表达式检测方法基于多条 正则完成匹配攻击过程,很大程度上存在误报的问题。例如select the best students from this class as the student union representative,这句话几乎所有的正则引擎都会因为检测到 select、from 和 union 的组合而判定该语句为 SQL 注入。
1.1.2 语义分析检测方法
语义分析检测方法是最近比较热门的检测 SQL 注入方法,其主要思路就是在防护端模拟一个 SQL 解释器,将所有输入内容使 用解释器检测,判断是否存在非法的 SQL 语句。该方法在先天上 避免了很多正则检测方法的缺陷,所以笔者比较倾向于这种检测方 法更准确。但基于语义分析的检测方法的一个重要问题是机动性差。试想 在 SQL 注入一种攻击上就要实现一个 SQL 检测引擎,那么 XSS 呢?PHP 代码执行呢?JAVA 代码执行呢?即便它是一个非常轻量级的引 擎,但是要覆盖到目前市面上所有主流的攻击,笔者脑海中想象到 的那画面只有四个字— —疲于奔命。这种极强的单一性从侧面还反应出了另一个问题,就是性能。 在某一种攻击的检测上,这种方法可以做到比正则引擎快几十倍, 但是如果多种攻击类型叠加呢?
综上所述,这种攻击类型虽然很好的解决了准确的问题,但是他也同时面临机动性差和多种攻击类型叠加所导致性能线性下降的 问题。
1.2 吸星攻击检测引擎
吸星引擎是一种全新思路的攻击检测引擎,使用机器学习的方 法来识别攻击行为,能够更准确的识别攻击行为,解决传统攻击检 测引擎高误报、易绕过、难维护、性能差的尴尬问题。吸星的特点 总结起来就是三个字,快、准、稳,详细的特点介绍将在后面给出。
1.2.1 吸星检测原理
吸星攻击检测引擎采用基于朴素贝叶斯方法优化实现统计概率 模型,通过统计出的概率模型对攻击语句进行识别。下面我们以SQL 注入攻击为例,来讲解吸星的检测原理。
“-1 and union select password from admin —+”,这是一个 标准的 SQL 注入语句,我们以单词的形式拆分他们后变成 :-1、union、select、1、123、2、–、+。
通过朴素贝叶斯公式 :P(D|h+)=P(W1|h+)*P(W2|h+)*P(W3|h+)… 、P(D|h-)=P(W1|h- )*P(W2|h-)*P(W3|h-)… (其中 D 为整个文本,h+/h- 分别代表攻 击和非攻击,W1 代表 D 中的第一个单词,以此类推),我们可以 得到这样的计算式 :p(-1 union select 1,123,2 –+|h+) = p(-1|h+) · p(union|h+) · p(select|h+) · p(1|h+)…,类似可以得到 h- 时的概率, 比较两者大小,概率大的便是结果分类。p(select|h+) 这种单词的概 率值,我们可以通过使用收集到的攻击 payload 来统计出大概的概 率值。同理,h- 我们可以通过统计正常的访问请求内容来统计概率值。
1.2.2 吸星的特点
吸星引擎最大的设计亮点在于,使用更高纬度的规则——行为特征,来判断是否为攻击。用攻击行为来检测攻击,这就像用黄色 皮肤来判定黄种人一样。
在实际测试的案例当中(这里仍以 SQL 注入为案例),现有正则 引擎的 WAF 与吸星在常规 SQL 注入攻击语句检测方面没有太多的 差别,但是在未知的 bypass 方式检测中,吸星可以检测出绝大部分 的绕过语句,而常规的 WAF 却只能检测到极少部分的。我们测试 的结果带有复杂绕过方法的 SQL 语句,吸星的检测率是 90% 左右, 而传统 WAF 只有 40% 左右。这还是已经市场化的 WAF 拥有比较 完善的正则数目,而吸星则还是 demo 阶段只有一万三千条左右语 料的情况下达到的效果。下表为吸星与基于正则表达式的检测引擎 的误漏报效果和性能对比,其中漏报测试使用 7442 条攻击语句进 行测试,误报测试使用 1458625 条正常访问进行测试。
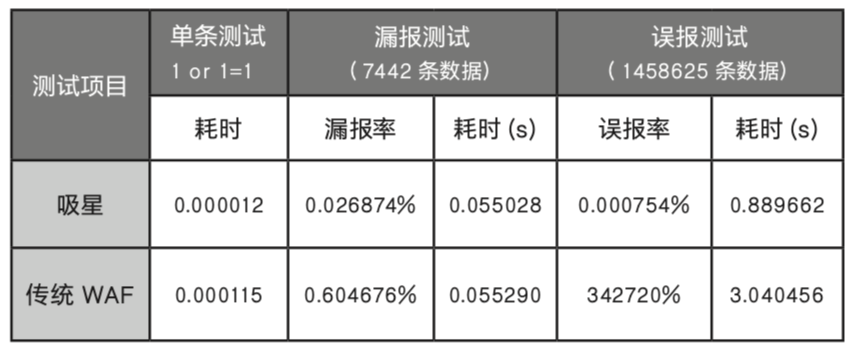
吸星与传统 WAF 的检测结果对比
在达到较高的检测率的同时,吸星的灵活性也是极为可观的。
对于不同种的攻击类型,只需要向吸星提供一定数量的该种攻击类型 的 payload 代码用于学习,吸星便可以检测此种攻击。这样的情况下, 我们只需要一些安全工程师用一些零散的时间收集相关的 payload, 就可以完成检测方案的提交。相比于原来需要高等级的安全工程师绞 尽脑汁写正则的过程来说,吸星的后期维护成本是极低的。
1.3 基于流量的 Webshell
检测Webshell 是攻击者经常使用的恶意脚本,攻击者常利用Webshell 对被攻击的主机实施一系列的恶意操作。一些中小型企业、 高校单位以及政府部门难免会遭受 Webshell 攻击,由于利益的诱惑 不少网站都遭受过 Webshell 的入侵。目前 Webshell 攻击的检测技 术很难做到准确的查杀,基于流量的 Webshell 检测技术是一种主 流的动态监测手段。当攻击者访问或者操作其后门 Webshell 的过程 中,会产生网络流量。通过对其流量数据进行分析来检测网络流量 是否来自于 Webshell 异常流量。
绿盟自主研发的基于流量的 Webshell 检测引擎,通过对正常流 量以及异常流量进行建模,即利用流量数据的属性(包括 URL,IP,payload 等)对具备 Webshell 特点的异常流量和正常流量进行分 类,异常流量的属性中往往包含 Webshell 的语义特征。基于文本分 类的技术,利用流量属性构建文本特征向量并通过收集正常流量和Webshell 异常流量构建训练数据,检测引擎基于 DNN 模型和 GBDT模型对训练数据进行训练,实现 Webshell 异常流量检测的目标。
利用 DNN 模型对 Webshell 实体信息的实体识别与特征抽取能力,确定流量信息中的 Webshell 语义信息深度表征 ;根据专家知识 对流量信息构建特征工程,利用 GBDT 模型对由特征工程生成的特 征向量进行学习。结合 DNN 模型与 GBDT 模型对流量语义信息从 不同维度和方式进行学习,采用模型融合的技术手段对多个模型的 结果做检测评估,最终得到 Webshell 流量的检测结果。
经过预处理后的流量数据,对其构建的特征主要包含以下几个 维度 :
●流量数据固有属性:例如payload长度,中文字符数目,英文 字符数目等。
● Webshell 流量特有属性 :例如由中国菜刀产生的 Webshell流量中包含关键字 Z0,Z1 以及 php 函数 base64_decode 等。
●具有 Webshell 语义的延伸特征 :payload 中大写字母长度、Webshell 流量模式特征(Webshell 攻击工具产生的 payload 蕴含 的模式特征)等。
用户可以通过 restful 接口调用 Webshell 检测引擎的服务,检 测引擎通过 docker 部署在云端,引擎的底层通过 tensorflow 开发 机器学习检测算法。目前该引擎已经投入到了威胁检测应用中,安 全人员通过该引擎检测到的 Webshell 攻击流量,深入挖掘攻击 者的攻击行为,分析潜在的威胁,提高网络安全能力。随着未来Webshell 攻击的发展,Webshell 检测技术也会增强对新型变种攻 击的检测能力。

绿盟自主研发的 Webshell 检测引擎框架图
二 . 总结
对攻击数据的拟合实践,目的是通过系统的数据科学手段去有效梳理攻击者的行为逻辑和动作特征,核心效果是提升安全研究员 的全局感知力和延展对攻击的分析视角,最终扩大安全厂商所拥有 的安全知识库。现有数据科学技术大多都是基于统计学的拓展,在 对攻击数据拟合实践中,难的往往不是算法,而是如何把安全 / 攻防 经验进行有效量化,以及算法模型的持久运营。拟合的算法,正如金庸老先生在《天龙八部》中写到的小无相功, 可以运使各家各派武功,只不过细微曲折之处,不免有点似是而非。 安全终究是要回归到人的,打造海量攻击数据下,人机有效结合的 运营体系,是我们一直以来的愿景和前进的方向。“机”做人力所不能及之事,“人”专攻去伪存真后的攻防智慧, 方得始终。