摘要:
关于物联网资产识别研究的话题,我们介绍了资产识别的研究现状、物联网设备的特征以及基于先验知识的资产标记实践(文章链接见往期回顾),通过对问题的分析和标记实践后得知,要想解决好互联网上物联网设备识别的问题,必定是采用人工与智能的结合。本文是物联网资产发现的终篇,主要介绍如何通过机器学习聚类和人工标记结合快速准确的发现网络空间内的物联网资产指纹以及具体的识别效果。
一、人工+智能物联网资产标记流程
首先对使用扫描组件对国内网段进行探测,获取到全部HTTP(s)协议存活的资产数据。接下来使用先验知识对数据进行做过滤处理,先验知识主要包括:物联网负特征、HTTP异常状态码(40x,50x等)、返回空的数据。再通过机器学习聚类算法对处理后的数据进行文本聚类,得到相似的高置信度的资产类别,然后采用人工标记的方式对各个资产类进行标记,产出物联网指纹和非物联网资产指纹。通过不断运营标记迭代,实现对目前数据的资产标记的全面覆盖。资产标记流程如下图所示:

图1 基于资产聚类与人工标记相结合的资产标记过程
二、智能:资产聚类算法
2.1 Banner文本聚类
资产服务页面的文本包括HTTP请求头内容以及资产服务页面源码等内容,根据积累的历史数据以及人工标记过的资产页面发现相同资产服务的页面信息具备很高的相似性。例如下列两个资产服务的页面都属于NETGEAR厂商设备仅仅是设备型号有所差异。
HTTP/1.0 401 Unauthorized WWW-Authenticate: Basic realm="NETGEAR WGR614v10" Content-type: text/html <html> <head> <meta http-equiv='Content-Type' content='text/html; charset=utf-8'> <title>401未授权</title></head> <body><h1>401未授权</h1> <p>到本资源的访问被拒绝,您的客户端未提供正确的认证。</p></body> </html>
与之类似的情况还有很多,有些相似的资产页面请求头会发生局部变化,而页面内容本身也会存在变化。但是相同资产服务的请求头和页面内容是高度相似的,利用这一特点本文提出利用文本聚类算法应用于资产服务页面文本,对相同资产服务进行聚类分析,从而得到不同资产服务的各个类别,并对物联网资产类进行梳理划分标签。进一步加快为专家提取相关指纹带来有效信息。
2.2 Banner文本数据向量化
资产服务页面文本和普通的英文或者中文文本在结构上存在差异,既无法直接使用现有的中英文文本进行分词,也无法进行词根提取。其原因在于资产服务页面是HTML网页格式文本以及HTTP协议响应文本。虽然无法直接利用已知分词及词根进行提取和处理,但是作为结构化数据依然可以实现文本数据向量化。
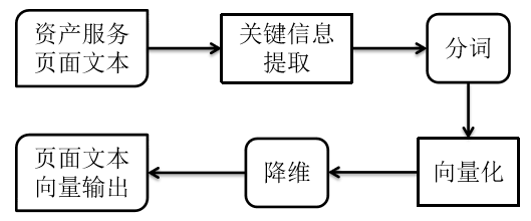
图2 资产服务页面聚类的向量化过程
2.3 聚类算法实践应用
本文采用的聚类算法包括基于距离计算的KMeans算法以及基于密度计算的DBSCAN算法,其原因在于不同的聚类算法在效果和实践开销层面表现不同。因此采用两者结合的方式对资产服务数据进行无监督聚类,从而达到资产服务聚类的效果。
Means算法是一种基于距离计算的朴素聚类思想,其过程如下。
- 选择若干个cluster center
- 对其他所有点进行分类,按照距离center的距离,划分给最近的cluster

- 更新center
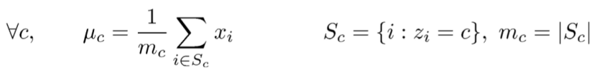
- 重复23步骤直到收敛或者终止条件
BSCAN算法是一种基于密度计算的聚类算法,其过程如下。
- 找到任意核心点,寻找从核心点出发的所有密度连接点。
- 遍历邻域内所有核心点,寻找密度连接点。不停迭代直到无法寻找到连接点。
- 重新寻找没被聚类的核心点,重复步骤12直到收敛。
首先利用KMeans算法进行第一次文本聚类,由于资产服务数据量大,聚类算法速度不能太慢,所以KMeans算法可以简单高效的得到聚类结果。通过人工确认后,确实有比较多效果比较好的物联网资产类别,但是同样也噪声很大的类别,为了尽可能获得全部物联网资产类别,所以将效果不好的类别使用DBSCAN算法对文本聚类的结果进行二次聚类,这样由于第一次聚类结果得到的每个聚类簇的大小相对原来的数据已经小了很多,而且DBSCAN再次进行聚类能够得到噪声更少的聚类效果。其过程如图所示。
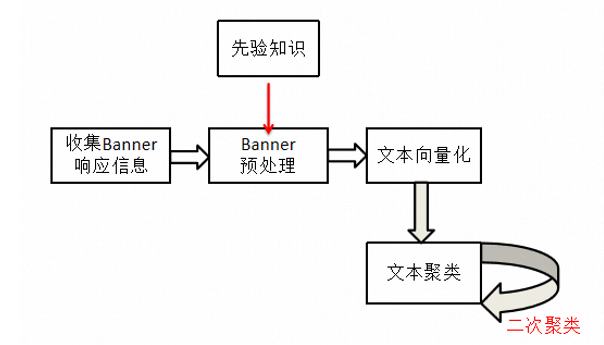
图3 资产聚类过程
最后通过多轮次迭代结合专家经验,进行资产服务聚类的效果评估。最终实现全量资产服务数据的标签化以及指纹化。
三、人工:多人协作标记
物联网资产聚类确实可以为了提供高置信度的物联网资产类别,但是准确的提取物联网设备指纹还需要人工参与完成,所以为了提高资产标记效率,我们设计了一款多人协作的物联网资产标记平台(Fiot),主要包括资产聚类、任务生成、资产标记、特征标记、指纹管理和标记态势六个功能。
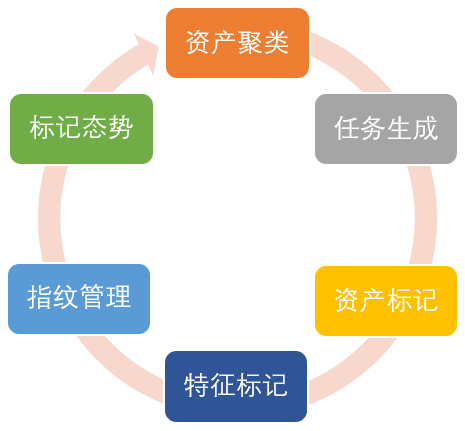
图4 Fiot主要功能和流程

图5 Fiot平台页面
- 资产聚类
将目标数据集中高置信度为物联网设备的资产进行聚类。
- 任务生成
将需要人工处理的高置信度物联网资产类别打包生成任务。
- 资产标记
人工对各个类别进行标记处理,如果有对应的物联网设备,进行指纹标记。
- 特征标记
如果类别中出现非物联网设备类别,提取相关指纹,进行负特征标记。
- 指纹管理
对多人协作提交的指纹进行存储管理,在指纹标记之前,审核人员再次校验指纹准确性。
- 标记态势
持续对标记的资产数量、指纹数量、厂商、设备类型等信息进行可视化运营,实时展示标记进度和产出。
四、实际物联网资产标记效果
接下来主要针对国内的开放web服务的资产数据作为标记的目标数据集进行标记实践,经过两个月的时间,迭代标记两个轮次的标记共发现352个物联网设备指纹、36种设备类型以及137个物联网厂商,共标记498401物联网设备。具体每轮的标记结果如表1所示。
表1 通过聚类发现的物联网设备情况
| 标记轮次 | 发现指纹数量 | 标记总数量 | 发现设备类型 | 发现厂商 |
| 第1轮标记 | 251 | 317622 | 25 | 91 |
| 第2轮标记 | 101 | 170779 | 11 | 46 |
在覆盖度方面,第一轮标记后发现的物联网资产占6%,发现非物联网资产占26%,无效数据(Banner为空和状态码异常)数据占47%,待处理的占21%(没有任何标签的)。第二轮标记发现物联网资产增加3%,非物联网资产增加2%,待处理减少5%。
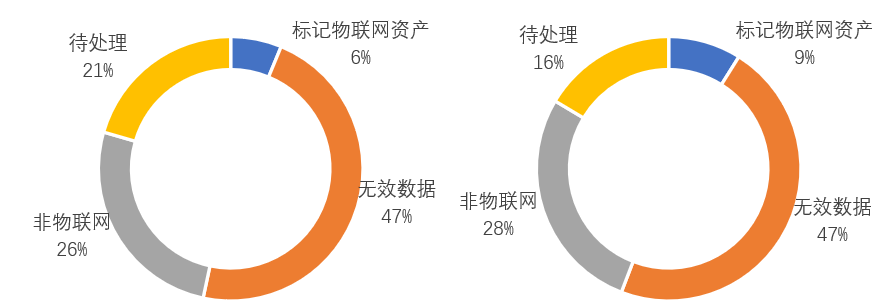
图6 两个标记轮次的各个部分数据占比情况(左为第一轮)
每个标记轮次发现的物联网资产数量趋势如下图所示,第一轮标记是从D点开始至E点结束,第二轮标记是从E点开始至F点结束,从标记数量折线来看,发现的资产数量增速锁着标记轮次逐渐变缓,随着标记轮次的增加发现的物联网设备数量也趋于平稳,近似等于目标数据集中存在的物联网设备数量。由此可见,基于资产聚类和人工标记相结合的方法可以尽可能的发现目标数据集中的物联网资产,在识别覆盖度方面有较好的效果。
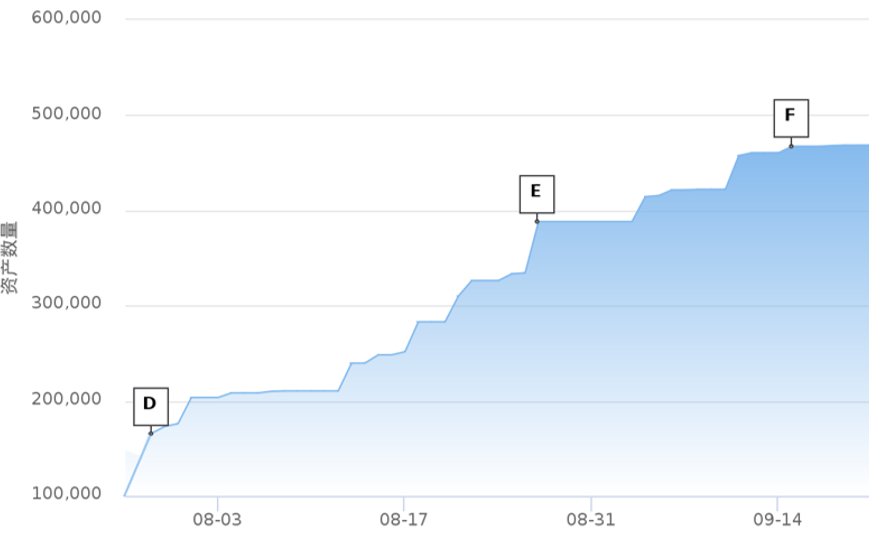
图7 标记的物联网设备数量趋势情况
五、结语
物联网资产识别貌似是一个“昨天”就应该解决的问题,但因为设备类型的不断的推陈出新以及网络场景的日益多样化,所以确切的说资产识别是进行时的问题,需要持续关注和投入才能更好的解决。本文将是未知物联网资产识别研究的最终篇,针对解决物联网资产识别覆盖度和精度的问题,提出了基于机器学习聚类与人工标记相结合的资产标记方法,一方面通过人工标记增加资产指纹的准确性,另一方面通过资产特征和聚类算法,能更快速的提取有效的资产信息,极大程度上减少标记的工作量。此外,还需要通过对标记持续运营和聚类迭代,才能尽可能对物联网资产进行全覆盖标记。当然这种资产识别方法不仅限于识别物联网设备,只需输入我们要关注的其他类型资产的特征,即可对该类型的资产进行识别标记。
作者:桑鸿庆 张胜军