近日,国家互联网信息办公室发布的《数据安全管理办法(征求意见稿)》,对各方关注的数据安全问题的管理进行了直接回应。可见国家对数据安全的重视。
5G、云计算、物联网、人工智能、工业互联网和区块链等新兴技术飞速变革,以数字化、网络化为核心的信息变革深刻改变着世界,这个时代已经越来越离不开数据。数据量越大,安全保障的责任就越大。数据安全已经事关经济社会大局。
做好数据梳理是数据安全治理的第一步,也是关键的一步。通过数据梳理可以识别关键业务数据及其面临的风险,完善组织数据保护政策,有效落实数据安全管理规定,降低业务运营风险,建立动态可持续的数据安全运维管理保障体系。
如何做好数据梳理呢?
第一步:定义敏感数据
《网络安全法》《等级保护2.0》将敏感数据分为“个人隐私数据”和“企业敏感数据”两大类,而落实到应用中,我们会发现还有一种衍生数据是不好界定的,比如消费信息、行为信息等等。现在只有运营商行业出台的数据安全标准或规范相对较完善,我们参考了《中国移动大数据安全管控分类分级实施指南》可以看到更细致的数据分类,及“A类:用户身份相关数据”、“B类:用户服务内容数据”、“C类:用户服务衍生数据”、“D类:企业运营管理数据”共四类,这样分类更加明确和具体。
通过上述对敏感数据的定义与归类,可以从全局上把控自身企业中包含的敏感数据的内容,再根据自身的业务情况,可以快速的定义敏感数据,并确定敏感数据的类型和级别,为今后数据管理提供有利的数据支撑。
第二步:敏感数据追踪
数据分为结构化数据、半结构化数据、非结构化数据。结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据;半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但它含相关标记,用来分隔语义元素以及对记录和字段进行分层;非结构化数据就是没有固定结构的数据。在大数据环境中,这三类数据都会存在,并且被合理的存储和使用。
从数据存储和使用的角度,我们会发现数据有两种形态,分别为静态数据和动态数据,下面,我们就以大数据环境Hadoop为例来看看数据都在哪里。

从上图可以看出,静态数据滞留在数据存储层,而动态数据则出现在数据分析层、数据共享层、数据应用层。在数据存储层利用主动扫描的技术可以快速发现和梳理静态数据,在数据分析层、数据共享层、数据应用层,我们可以利用监听的方式获取动态数据以及数据的流转与转换情况,监听方式包括:链路旁路镜像和插件Agent方式。
第三步:敏感数据挖掘
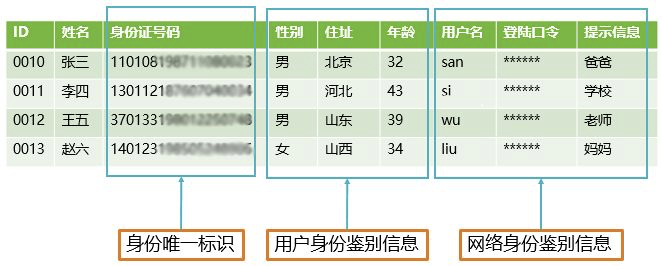
综上所述,企业敏感数据梳理,需要根据自身业务特点进行数据的挖掘分析,再利用现代化的工具快速的实现企业敏感数据的发现与分类分级,并根据梳理的结果实现数据风险的分析与展现。
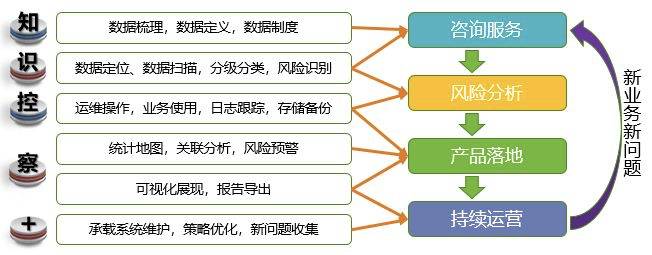
绿盟数据安全解决方案为数据安全设计全面可信的防御体系,提出“知”、“识”、“控”、“察”的数据安全治理方法论,包括数据梳理、运维数据监管、业务数据监管、办公数据监管、数据可视化的完整解决方案,有效保护数据在全生命周期过程中的安全,达到合法采集、合理利用、静态可知、动态可控的防护目标。