Serverless概念首次出现在2012年,Kubeless是基于Kubernetes的原生无服务器框架,其允许用户部署少量的代码(函数),而无需担心底层架构。它被设计部署在Kubernetes集群之上,并充分利用Kubernetes的特性及资源类型。可以克隆在AWS Lambda,Azure Functions、Google Cloud Functions上的内容。由于 Kubeless 的功能特性是建立在Kubernetes上的,所以对于熟悉 Kubernetes的人来说非常容易部署 Kubeless, 其主要实现是将用户编写的函数在Kubernetes中转变为 CRD( Custom Resource Definition,自定义资源), 并以容器的方式运行在集群中。
一 Kubeless背景
Serverless介绍
Serverless概念首次出现在2012年,由云基础设施服务提供商Iron.io的副总裁Ken Fromm在《Why the future of software and apps is serverless》【4】一文中阐述,在2014年亚马逊发布了AWS Lambda之后,Serverless开始变得流行了起来,国内外的各大云厂商都争相跟进。
2016年8月,martinfowler.com网站上发表的《Serverless》 【5】 一文中对Serverless概念做了详细阐述,简单来说,Serverless可以理解为以下内容:
由开发者实现的服务端逻辑运行在无状态的计算容器中,通常可以理解为Faas(Functions as a Service)函数即服务的形式,它由事件触发,完全被第三方管理,目前使用最广泛的为AWS的Lambda。
而Serverless与容器和虚拟机的关系可由下图所示:
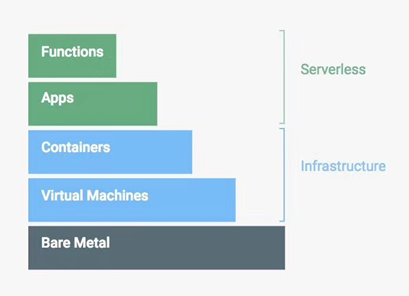
图1 从物理机到函数计算
由上图可以看出serverless是构建在虚拟机和容器之上的,与应用关系更加密切。
开源框架 Kubeless 是由 2017 年 3 月被 Bitnami 收购的软件供应商 Skippbox开发的。 Kubeless 是一个 Kubernetes 本地无服务器框架,具有符合 AWS Lambda CLI 的命令行界面( CLI)。
Kubeless官方对其定义是这样的:
Kubeless is a Kubernetes-native serverless framework that lets you deploy small bits of code (functions) without having to worry about the underlying infrastructure. It is designed to be deployed on top of a Kubernetes cluster and take advantage of all the great Kubernetes primitives. If you are looking for an open source serverless solution that clones what you can find on AWS Lambda, Azure Functions, and Google Cloud Functions, Kubeless is for you!【1】
Kubeless是基于Kubernetes的原生无服务器框架,其允许用户部署少量的代码(函数),而无需担心底层架构。它被设计部署在Kubernetes集群之上,并充分利用Kubernetes的特性及资源类型。可以克隆在AWS Lambda,Azure Functions、Google Cloud Functions上的内容。
Kubeless主要特点可以总结为以下几个方面:
- 支持Python, Node.js, Ruby, PHP, Golang, .NET, Ballerina和自定义运行时。
- Kubeless CLI符合AWS Lambda CLI。
- 事件触发器使用Kafka消息系统和HTTP。
- Prometheus默认监视函数的调用和延迟。
- Serverless框架插件。
由于 Kubeless 的功能特性是建立在Kubernetes上的,所以对于熟悉 Kubernetes的人来说非常容易部署 Kubeless, 其主要实现是将用户编写的函数在Kubernetes中转变为 CRD( Custom Resource Definition,自定义资源), 并以容器的方式运行在集群中。
二 Kubeless架构
1 Kubeless基本组成
Kubeless主要由以下三部分组成:
- Functions
- Triggers
- Runtime
下面针对这三个组成部分,进行详细介绍。
Functions
Functions 表示要执行的代码,即为函数,在Kubeless中函数包含有关其运行时的依赖、构建等元数据。函数具有独立生命周期,并支持以下方法:
(1) Deploy: Kubeless 将函数部署为 Pod的形式运行在Kubernetes集群中,此步骤会涉及构建函数镜像等操作。
(2)Execute:执行函数,不通过任何事件源调用。
(3)Update:修改函数元数据。
(4)Delete:在Kubernetes集群中删除函数的所有相关资源。
(5)List:显示函数列表。
(6)Logs:函数实例在Kubernetes中生成及运行的日志。
Triggers
Triggers表示函数的事件源,当事件发生时,Kubeless确保最多调用一次函数,Triggers可以与单个功能相关联,也可与多个功能相关联,具体取决于事件源类型。Triggers与函数的生命周期解耦,可以进行如下操作:
(1)Create:使用事件源和相关功能的详细信息创建 Triggers。
(2)Update: 更新 Triggers元数据。
(3)Delete:删除Triggers及为其配置的任何资源。
(4)List:显示Triggers列表。
Runtime
函数使用语言因不同用户的喜好通常多样化, Kubeless 为用户带来了几乎所有的主流函数运行时, 目前含有[3]:
(1) Python: 支持2.7、3.4、3.6版本。
(2) NodeJS: 支持6、8版本。
(3) Ruby: 支持2.4版本。
(4) PHP: 支持7.2版本。
(5) Golang: 支持1.10版本。
(6) .NET: 支持2.0版本。
(7) Ballerina: 支持0.975.0版本。
在Kubeless中,每个函数运行时都会以镜像的方式封装在容器镜像中,通过在Kubeless配置中引用这些镜像来使用,可以通过 Docker CLI 查看源代码。
2 Kubeless设计方式
与其它开发框架一样, Kubeless也有自己的设计方式,Kubeless利用Kubernetes中的许多概念来完成对函数实例的部署,主要使用了 Kubernetes以下特性【2】 :
(1) CRD( 自定义资源) 用于表示函数。
(2) 每个事件源都被当作为一个单独的 Trigger CRD 对象。
(3) CRD Controller 用于处理与 CRD 对象相应的 CRUD 操作。
(4) Deployment/Pod 运行相应的运行时。
(5) ConfigMap 将函数的代码注入运行时的 Pod。
(6) Init-container 加载函数的依赖项。
(7) 使用Service在集群中暴露函数( ClusterIP)。
(8) 使用Ingress资源对象暴露函数到外部。
Kubernetes CRD 和 CRD Controller 构成了 Kubeless 的设计宗旨,对函数和 Triggers 使用不同的 CRD 可以明确区分关键点,使用单独的 CRD Controller 可以使代码解耦并模块化。
部署Kubeless之后,集群中Kubeless对应的namespace中会出现三个CRD以代表Kubeless架构中的Functions和Triggers,如图 2所示,在此之后每通过Kubeless CLI创建的 Functions、 Triggers 均隶属于这三个CRD端点下,

图2 Kubeless的CRD
在Kubeless上部署函数的过程可分为以下三步【2】【2】:2
- Kubeless CLI 读取用户输入的函数运行配置, 产生一个 Function 对象
并将其提交给Kubernetes API Server。 - Kubeless Function Controller(运行在Kubeless Controller Manager中, 安装完Kubeless后在集群中默认存在的 Deployment, 用于监听及处理函数的相应事件) 监测到有新的函数被创建并且读取函数信息,由提供的函数信息 Kubeless首先产生一个带有函数代码及其依赖关系的ConfigMap,再产生一个用于内部通过HTTP或其它方式访问的 Service,最后产生一个带有基本镜像的Deployment ,以上生成的顺序十分重要,因为若 Kubeless 中的Controller无法部署ConfigMap 或 Service,则不会创建Deployment。任何步骤中的失败都会中止该过程。
- 创建完函数对应的Deployment后, 集群中会跑一个对应的 Pod, Pod在启动时会动态的读取函数中的内容。
三 Kubeless实例部署
1 部署前的安装工作
笔者的测试环境为Ubuntu 16.04,Kubernetes集群为node3、node4,node3为Master节点,以下实践均基于以上环境,不予赘述。
Kubeless的安装主要分为三个部分:
- 安装Kubeless CLI
首先下载CLI压缩包,可根据版本自行选择,如图3所示,安装包地址为:
https://github.com/kubeless/kubeless/releases/download/v1.0.0-alpha.7/kubeless_linux-amd64.zip
图3Kubeless CLI压缩包版本
下载后进行解压及移动操作:
unzip kubeless_linux-amd64.zip sudo mv bundles/kubeless_$OS-amd64/kubeless /usr/local/bin/
之后测试是否安装成功,如图4所示 :

图4查看Kubeless CLI安装情况
- 安装Kubeless框架
对应集群不同的Kubernetes环境,Kubeless提供了可选清单,即为非RBAC,RBAC,Openshift这三种,如图5所示:

图5Kubeless提供可选Kubernetes环境
在此由于笔者测试环境集群是基于RBAC环境所以选取RBAC安装模式,执行以下命令创建:
kubectl create ns kubeless kubectl create –f https://github.com/kubeless/kubeless/releases/download/v1.0.0-alpha.7/kubeless-v1.0.0-alpha.7.yaml
由以上命令不难看出,首先创建一个Kubeless的Namespace,然后再创建Kubeless框架相关模块,kubeless-v1.0.0-alpha.7.yaml中主要包括六种资源对象并依次创建,其内容如下图所示:
图6 Deployment – kubeless-controller-manager
图7 ServiceAccount – controller-acct
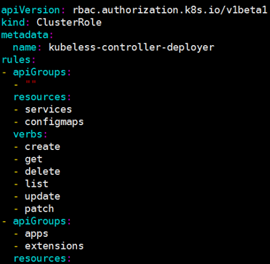
图8 ClusterRole – kubeless-controller-deployer
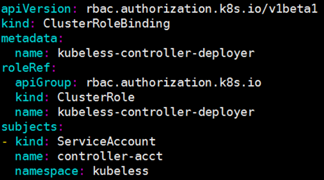
图9 ClusterRoleBinding – (controller-acct kubeless-controller-deployer)
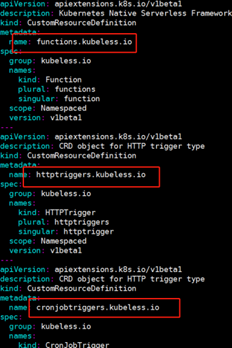
图10 CustomResourceDefinition-( functions.kubeless.io,httptriggers.kubeless.io, cronjobtriggers.kubeless.io)

图11函数运行时镜像 ConfigMap( nodejs,python,java,perl 等)
- 安装Kubeless UI
安装命令为:
kubectl create -f https://raw.githubusercontent.com/kubeless/kubelessui/master/k8s.yaml
安装完成后可查看部署情况,结果如下图所示:
kubectl get po,svc,deploy -n kubeless -o wide
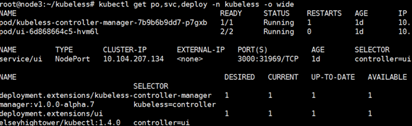
图12 Kubeless UI部署情况查看
可以在浏览器上访问部署的Kubeless UI,由下图所示:
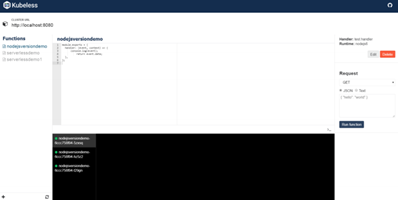
图13 Kubeless UI
2 编写函数并运行实例
由于Kubeless支持多语言环境,以python环境为例举例说明:
编写基于python的函数test.py, 函数具体如下图所示:
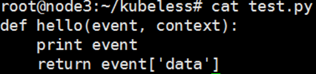
图14 基于python的test.py函数
由图14的函数定义可以看出,函数接收两个参数,分别为event和context,在此要说明的是,在Kubeless框架中,每种函数运行时在定义函数时都包含这两个参数,其中第一个参数包含有关函数收到的事件源信息,第二个参数包含相关函数的一般信息,如名称、最大超时等,函数最终会返回一个字符串用于响应调用者的返回。
为函数 test.py 运行实例,运行命令为:
kubeless function deploy serverlessdemo --runtime python2.7 --from-file test.py --handler test.hello
由于篇幅原因, — 后跟的参数不予赘述,详情可通过kubeless function deploy –help查看
通过kubeless function ls 或 kubectl get function查看已部署的函数,如下图所示:

图15 查看已部署的函数实例
调用已部署的函数,此时有三种可以调用的方式:
- 通过kubeless指定调用
kubeless function call serverlessdemo --data '{"dsds":"dsd"}

图16 调用函数实例
- 通过kube proxy调用
kube proxy -p 8889 & 指定代理端口

图17 开启指定端口代理
使用代理调用函数
curl -L --data '{"Another": "Echo"}' --header "Content-Type:application/json" localhost:8999/api/v1/namespaces/default/services/serverlessdemo:http-functionport/proxy/
- 通过Kubeless UI调用
Kubeless UI操作如下图所示:
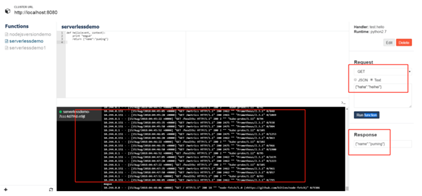
图18 通过Kubeless UI调用函数实例
通过上图可以看出调用函数支持 POST/GET 方法,传输 data 格式支持text/json,并且可以编辑/删除函数, 同时也可以看到该函数执行时的日志。
可通过命令查看函数调用次数,如下图所示:
kubeless function top

图19查看函数实例调用次数
也可以修改test.py并使用kubeless function update serverlessdemo –from-file test-update.py来更新函数。
可以查看函数在集群中的运行情况并进行进一步发现,首先查看集群中部署的函数实例如下图所示:

图20 查看集群中部署的函数实例
由上图可发现Pod名为serverlessdemo-07ccc4dxxxxxx的函数实例部署在node4节点上,于是去node4进一步查看信息如下图所示:
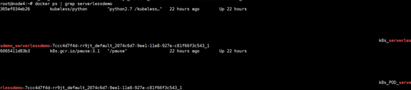
图21node4中查看Pod实例所运行容器
由上图可知,此函数实例在部署至node4节点后,产生了两个容器,一个为pause容器,一个为test.py实例化后的容器,再看看相关镜像,如下图所示:
node3:

图22 node3中相关镜像
node4:

图23 node4中相关镜像
由以上两张图不难看出,每个函数实例被集群调度至某个节点后都会在节点上pull对应函数的运行时镜像,比如python环境镜像或是node.js环境镜像。
若是部署中出现错误,具体可查看官方文档常见错误,地址为:
四 总结
Kubeless 虽然解决了 Serverless在 Kubernetes上部署的问题,但还是有一些缺点的,例如当扩展某个函数实例时, 如果实例运行所在的 node节点没有存在承载此函数的运行时镜像,则需要下载此镜像,目前看来这些镜像文件还是较大的,一个node.js 运行时镜像居然有 600 M,如果在多集群的环境下,当需要对请求进行大量负载均衡时, 则会导致每个部署节点都要下载运行时环境, 效率还是有点偏低。
另外 Kubeless 目前对基本镜像未设置缓存,意味着每次构建新镜像时,都需要下载一遍基本镜像, Kubeless 也在努力解决此问题。
目前有个较好的建议是给 Docker 配置私有仓库或是共有仓库。每次部署实例完成后, Kubeless 会自动将此镜像 push 到镜像仓库中去。之后如果部署相同的函数时就可直接从镜像仓库中 pull镜像, 如果改动了函数,Kubeless 也会更新相应镜像并上传至镜像仓库,从而解决了效率问题。