和前面的文章一样,这次我们来一起讨论下bridge设备的数据走向。以下的实验简单,可以帮助linux技术初学者入门、理解。
往期回顾:
Linux 内核网络设备——vEth 设备和 network namespace 初步
Linux内核中的bridge设备
1. bridge设备介绍:
1.1 bridge设备也是一种虚拟的网络设备,所以具有网络设备的特性,bridge设备是一种纯软件实现的虚拟交换机,所以和物理的交换机有着类似的功能(mac地址学习、stp、fdb等)
1.2 bridge设备既可以配置ip地址也可以配置mac地址,可以实现交换机的二层转发。
1.3 bridge设备有多个端口,我们可以将tap设备、veth设备attach到bridge设备,我们可以想象成是交换机上的各种端口。
2. bridge实验:
2.1 我们将在ubuntu16.04上进行实验(之前在Centos7上出现了icmp报文在协议栈icmp_rcv丢包的情况,导致ping失败,但实际是抓到了包、也关闭了iptables的过滤,折腾了几天,最后换成ubuntu就没有这个情况)
2.2 拓扑环境介绍:
2.2.1在系统中创建一个名为br0的bridge设备,如图2-2-1:

图2-2-1
2.2.2 当我们创建br0设备时,它是一个独立的网络设备,可以看成是一端连接协议栈,然后br0没有任何端口,就像NF没有任何板卡,纯属是一个二层设备,拓扑如图2-2-2,这里假设ens是我们ubuntu的物理网卡,IP地址是192.168.15.131,网关是192.168.15.2:
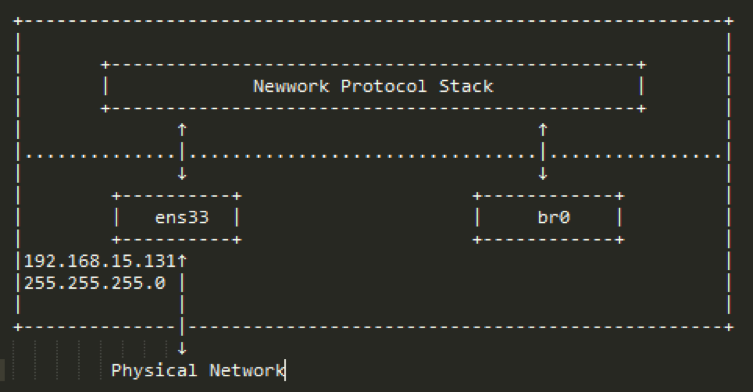
图2-2-2
2.3 将bridge和veth pair一端相连
2.3.1创建veth pair,并配置上ip,如图2-3-1:
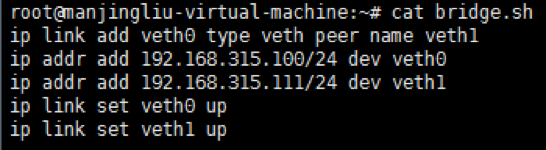
图2-3-1
2.3.2 将veth0 attached到br0,如图2-3-2-a,这就好比我们在交换机上加入了一块板卡(1个端口),这时候ubuntu上的而网络环境变为图2-3-2-b(为了画图方便,省略了IP地址前面的192.168,比如.15.111就表示192.168.15.111/24):
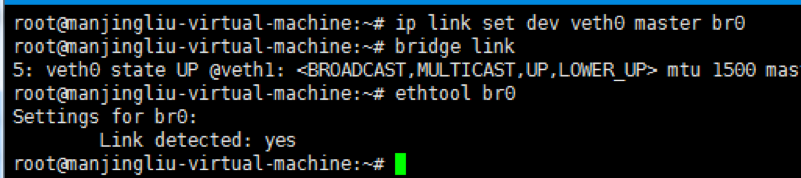
图2-3-2-a
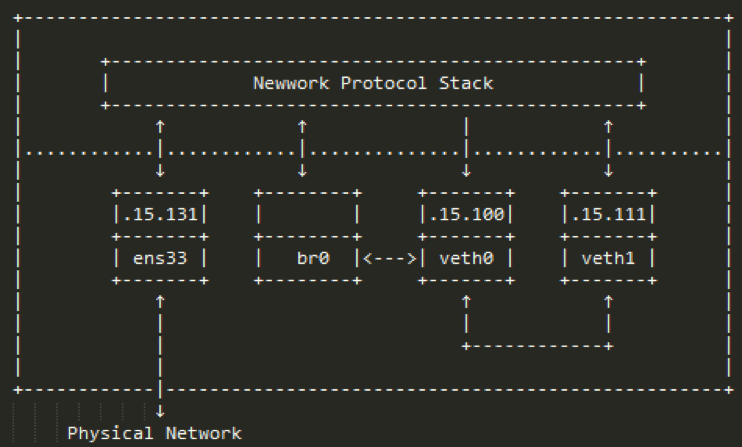
图2-3-2-b
2.3.3 br0和veth0相连之后,发生了几个变化:
* br0和veth0之间是双向通道,br0可以把数据从veth0转发出去,也可以从veth0收包进来
*协议栈和veth0之间成了单向通道,协议栈可以将数据发给veth0,但是veth0从veth1收到的包会转发给br0进行处理,而不会转发给协议栈,br0处理完后才会转发给其他端口
* br0的mac地址变成了veth0的mac地址,如图2-3-3:

图2-3-3
2.3.4 校验数据收发
* 通过veth0去ping veth1(在这之前先设置本地接口arp响应相关的内核参数,如图2-3-4-a),如图2-3-4-b,ping失败:

图2-3-4-a
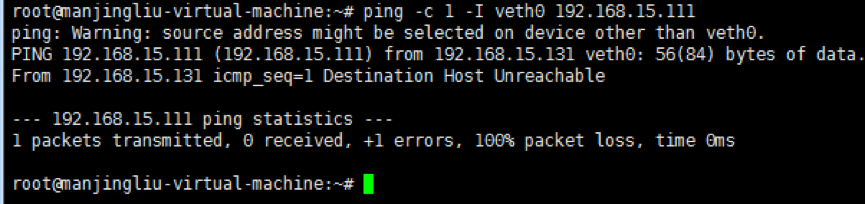
图2-3-4-b
*在br0上抓包,如图2-3-4-c,说明在br0收到arp响应:

图2-3-4-c
*在veth1上抓到双向的arp报文,如图2-3-4-d:
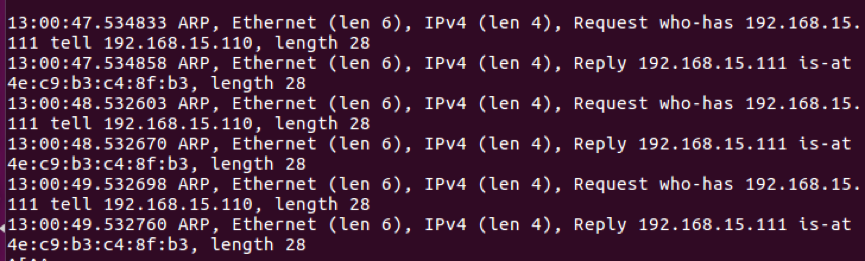
图2-3-4-d
*在veth0上抓到双向arp报文,如图2-3-4-e:
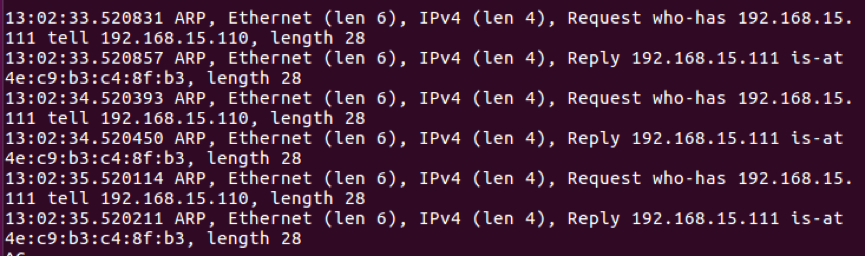
图2-3-4-f
*说明数据走向符合2-3-2-b描述的数据走向
2.4 给br0配置ip
2.4.1删除veth0的ip,给br0配置ip,如图2-4-1:
![]()
图2-4-1
2.4.2ubuntu上的网络拓扑如图2-4-2:
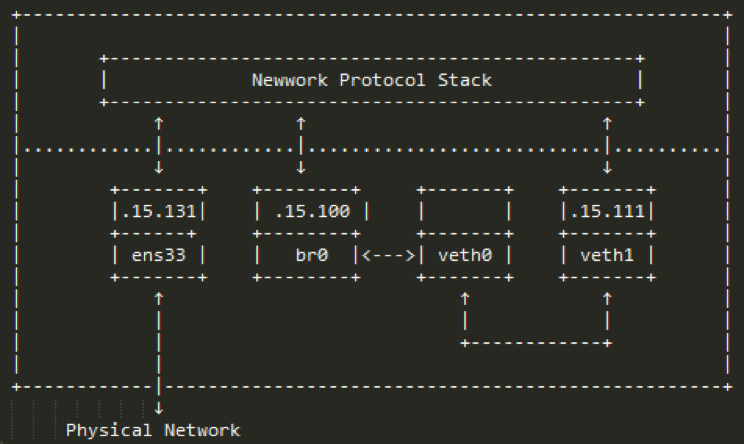
图2-4-2
2.4.3其实veth0和协议栈之间还是有联系的,但由于veth0没有配置IP,所以协议栈在路由的时候不会将数据包发给veth0,就算强制要求数据包通过veth0发送出去,但由于veth0从另一端收到的数据包只会给br0,所以协议栈还是没法收到相应的arp应答包,导致通信失败。这里为了表达更直观,将协议栈和veth0之间的联系去掉了,veth0已经attach到br上
2.4.4 这次通过br0去ping veth1,结果如图2-4-4:
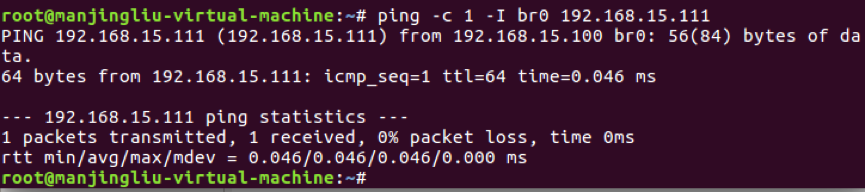
图2-4-4
2.4.5注意:icmp响应仍然是发给lo设备的,因为192.168.15.111是本地网络设备的地址,所以会发给lo设备(在以后的文章中会加入策略路由的讨论)如图2-4-5:
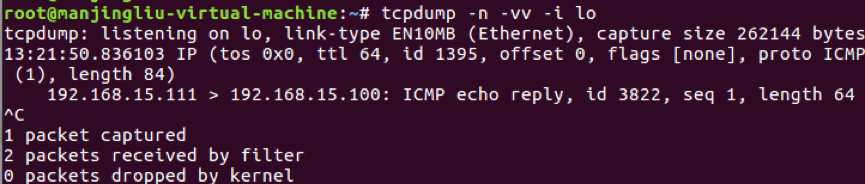
图2-4-5
2.4.6 所以数据收发符合图2-4-2的描述(因为开启了arp相关的内核参数,arp响应的走向是满足的,icmp的响应也可以通过策略路由的调整满足图2-4-2的走向)
2.5 将物理网卡attach到br0上
2.5.1添加ens33到br0,如图2-5-1-a,且br0的mac变成了ens33的mac,如图2-5-1-b:

图2-5-1-a
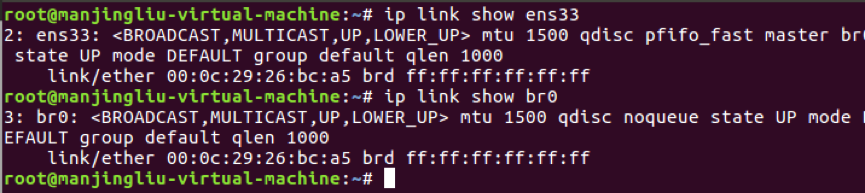
图2-5-1-b
2.5.2 bridge设备不管成员设备是虚拟设备还是虚拟设备,本质上都是在内核中创建的net_device
2.5.3 这是通过ens33去ping网关已经不管用了,如图2-5-3:
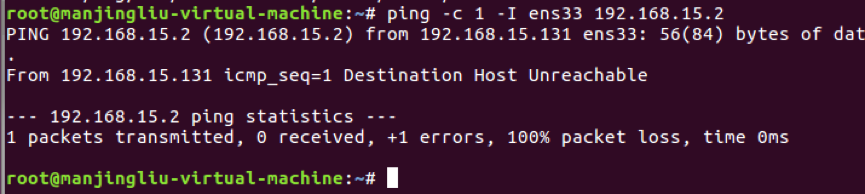
图2-5-3
2.5.4 此时arp响应转发给了br0设备,如图2-5-4:

图2-5-4
2.5.5 此时通过veth1、br0都能ping网关,因为arp响应发给了br0设备,如图2-5-5-a、2-5-5-b:
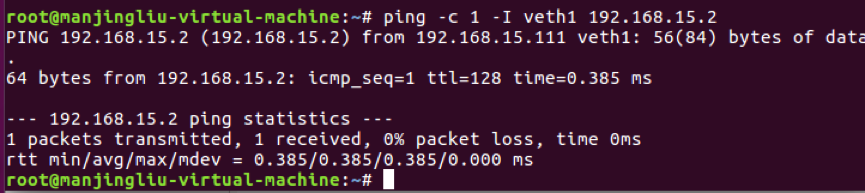
图2-5-5-a

图2-5-5-b
2.5.6 此时ens33的ip已经没有什么作用了,这里我们将他的ip删除,如图2-5-6-a,修改过后ubuntu的网络拓扑如图2-5-6-b(192.168.15.100这个ip其实可以看成是协议栈中有个接口连接着br0,这个ip可以看成是那个接口的):
![]()
如图2-5-6-a
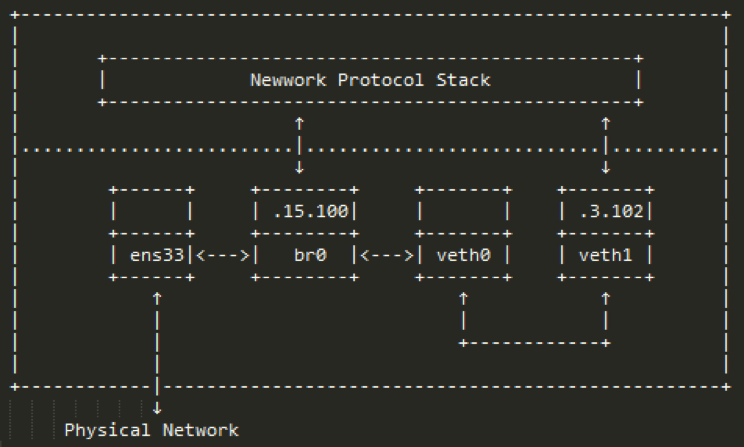
图2-5-6-b
2.6 将bridge设备的ip删掉
2.6.1删去br0的ip,如图2-6-1:
![]()
图2-6-1
2.6.2修改过的ubuntu的网络拓扑为图2-6-2:
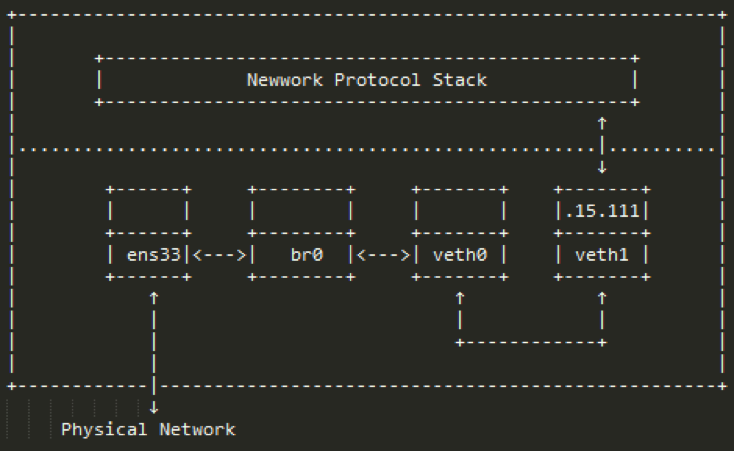
图2-6-2
2.6.3 此时ping网关仍然成功,如图2-6-3:
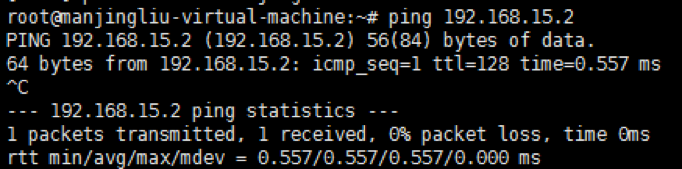
图2-6-3
3. Bridge设备的常用场景
3.1 虚拟机,如图3-1(摘自网络),虚拟机通过tun/tap或者其它类似的虚拟网络设备,将虚拟机内的网卡同br0连接起来,这样就达到和真实交换机一样的效果,虚拟机发出去的数据包先到达br0,然后由br0交给eth0发送出去,数据包都不需要经过host机器的协议栈,效率高。
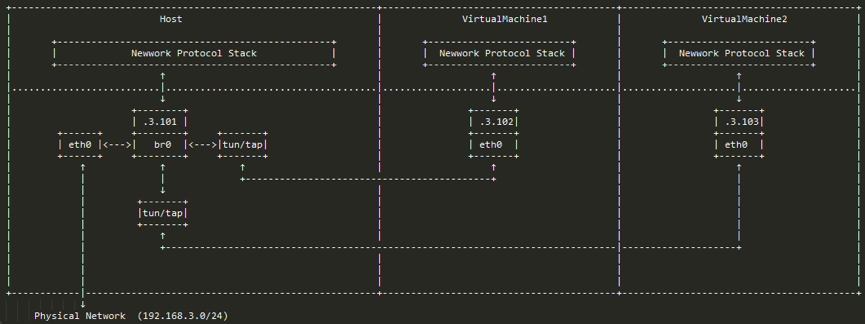
图3-1
3.2 docker,如图3-2(摘自网络),由于容器运行在自己单独的network namespace里面,所以都有自己单独的协议栈,情况和上面的虚拟机差不多,但它采用了另一种方式来和外界通信

如图3-2
3.2.1 容器中配置网关为.9.1,发出去的数据包先到达br0,然后交给host机器的协议栈,由于目的IP是外网IP,且host机器开启了IP forward功能,于是数据包会通过eth0发送出去,由于.9.1是内网IP,所以一般发出去之前会先做NAT转换(NAT转换和IP forward功能都需要自己配置)。由于要经过host机器的协议栈,并且还要做NAT转换,所以性能没有上面虚拟机那种方案好,优点是容器处于内网中,安全性相对要高点。(由于数据包统一由IP层从eth0转发出去,所以不存在mac地址的问题,在无线网络环境下也工作良好)
如有意成为绿盟科技博客作者,欢迎进入作者群讨论!
绿盟科技博客作者QQ群:695158981

绿盟科技博客作者微信群:
