网络钓鱼频发,诱骗手段的不断进化,能从单纯的信息窃取演变为大规模APT攻击,不断威胁着个人与企业的信息、财产安全。本文介绍了一种多维度钓鱼检测技术方案:由情报匹配与模型检测相结合的钓鱼URL检测方案,区别于仅从URL本身特征去检测,该方案融入了其他的关联特征如whois信息、网页元素与其他网页链接的特征、图像视觉特征,是一种多层次、多维度的检测技术。
一、背景
网络钓鱼(phishing)是指攻击者达到一些恶意目的,如内网入侵、获取敏感信息数据等,伪装为可信实体,向受害者抛出诱饵的一种网络欺诈犯罪行为。近年来,钓鱼网站的数量一直呈高速增长,攻击对象也越来越有针对性,电商、运营商、银行保险等成为钓鱼攻击的高发行业,根据对2016年全球中文钓鱼网站统计数据,钓鱼网站的主要仿冒对象为淘宝、中移动、各大银行[1]。2017年第二季度,银行业是网络钓鱼攻击的第一大目标,占比23.49%[2]。
钓鱼攻击的手段多样,并且一直在变迁。网络钓鱼攻击、鱼叉式钓鱼攻击、域欺骗、语音钓鱼、短信钓鱼和社交工程欺诈是攻击者使用的几个常用的手法。钓鱼过程中,攻击者首先会搜集相关信息,制作仿冒的钓鱼网站,注册与仿冒实体相混淆的域名,如抢注域名和误植域名。抢注域名是指注册和实际公司域名非常类似的域名,然后再模仿真实公司网站伪造另一个网站;误植域名的过程大同小异,但利用的是输入公司域名时常见的打字错误,这两种方法依赖的都是正确拼写的URL的变体[3]。
钓鱼攻击一般都具有社交工程欺骗性,鱼钩是贴近受害者关心的诱惑性内容,所以受害者不会将其视为网络钓鱼诈骗,等意识到自己中招时为时已晚,危害已经发生。一些钓鱼URL点击之后,会泄露个人敏感信息或造成直接金钱损失;另一些钓鱼URL一旦点击,计算机中就开始下载恶意软件,或者用户被定向至病毒或链接到一个可秘密下载恶意软件到他们计算机上的网站,恶意软件乘机植入到计算机中。多数钓鱼攻击类似于肇事逃逸,持续时间相对较短,但钓鱼APT一旦得手,会长期潜伏,持续很长时间[4]。钓鱼攻击发生后,受害者个人信息、财产会有不同程度的损害,更有甚者造成企业内网被入侵、核心数据泄露,声誉受损,甚至导致拒绝服务[5]。美国联邦调查局(FBI)于2016年年中时发布警告,称2016年上半年网络钓鱼攻击造成的经济损失高达31亿美元。
二、钓鱼检测技术
钓鱼手段多样,名目繁多,如何辨别钓鱼攻击一直是各企业面临的难题。为了有效应对钓鱼攻击,识别尽可能多的钓鱼URL,绿盟科技提供了一种多维度多层次的钓鱼检测方案。该钓鱼检测技术方案由情报检测部分和模型检测两部分构成。
-
NTI情报匹配

图1 情报匹配过程
情报匹配流程如图1所示。NTI情报匹配包含三个情报资源库,其中,绿盟威胁情报云是不断更新的情报库;私有情报是客户自有的情报数据,具有个性化的特点;企业侧情报由绿盟威胁情报云下发的情报和私有情报共同组成,随着平台运行而不断更新并且缓存在本地。这种本地情报生成方式在匹配过程中,能减少网络通信,提高匹配效率。NTI情报匹配过程以BSA平台为中心,进行数据处理。BSA从客户侧接入待检测数据可以是直接的http访问数据,也可以原始流量类数据,如绿盟uts探针数据、netflow流量数据。这种流量数据可以通过BSA平台解析出其中的通信实体,从而进行情报匹配。
情报匹配过程首先将待检URL交由包含客户私有情报资源的本地情报进行匹配,无法判断的URL再提交NTI云端检测,有检测结果时,将检测结果返回客户侧,同时更新本地情报资源。情报匹配命中有三种情形,分别为URL的完全匹配、部分匹配和间接匹配。部分匹配又分为域名部分匹配和相对路径部分匹配,即整个URL中只有域名部分或者相对路径部分匹配上情报。当域名命中白名单时则放过,命中黑名单时则检测结果为网络钓鱼,而当域名黑白名单均为命中,可以根据相对路径是否为钓鱼黑名单再做判断。间接匹配则是利用了域名与IP之间的对应关系进行的匹配,取到域名对应的IP或者IP对应的域名与情报库中黑白名单进行匹配。
对于NTI云端检测无法判断的URL则存入模型待检库中,交由下一部分钓鱼检测模型进行检测。
-
模型检测
当现有情报库无法对URL进行判断时,则可以通过以钓鱼攻击的特征训练得到模型检测尚未被标记的URL。模型检测如图2所示,分为基于URL特征检测、基于DNS特征检测、基于HTML源码特征检测以及页面图像检测四种检测模型。
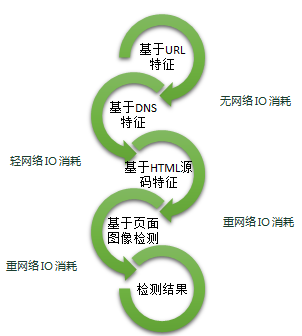
图2 模型检测过程
- 基于URL特征检测,是根据提取URL长度、包含字符等特征进行判断。较长的URL有利于攻击隐藏可疑的URL片段,而超短的域名更可能是为了逃避检测,经过短URL服务商处理的钓鱼站点。同时,钓鱼站点更可能包含一些IP,而合法站点往往不包含IP字段。此外,URL中包含的其他特殊字符,敏感字段等特点也对识别是否为钓鱼有一定的帮助。由于URL特征相对直观,使用URL特征检测是最常用的检测手段,也容易被攻击者规避,因此检测效率有限。
- 基于DNS特征检测,是根据URL对应的whois信息以及域名与行业库域名相似情况等特征判断。whois信息对探测钓鱼网站有一定作用,通常注册时间较短的域名更可能是钓鱼站点,同一注册者其他关联的域名有钓鱼的也更可能是钓鱼站点。根据统计,2016年147211的例钓鱼网站,其域名为8055位注册者持有,平均每个注册者持有18例[1]。另外,与行业库域名相似却不同的域名也更可能是钓鱼站点,很可能是攻击者事先特意抢注的域名和误植域名。但是,这种检测需要提取whois服务器的数据,但当数据量过大时,将会更耗费网络IO资源和时间。
- 基于HTML源码特征检测,通过抓取URL页面源码信息分析,根据源码包含的特征如外链比例、链接的域名、ICP备案等特征进行判断。在URL和DNS特征模型都无法对URL进行判断时,根据URL源码或许是一种不错的判断手段。通常,网页没有ICP备案信息、页面链接多个不同域名等更可能是钓鱼,此外源码中外链的也能帮助区分钓鱼站点。因为使用基于HTML源码特征检测需要抓取网页源码分析,耗费网络IO较大,费时较长,但检测效果通常更准确。
- 基于页面图像检测,根据截取的网页截图与合法网站图像相似度对比情况,或者logo包含情况判断是否为钓鱼站点。在URL和DNS特征模型都无法对URL进行判断时,也可以根据直观的网页呈现的视图与行业库网站的像素差异判断是否为钓鱼站点。但攻击仿冒方式的改变,很多仿冒钓鱼站点直接复制使用被仿冒实体的logo,因此可疑站点中若包含行业实体logo,那么也很可能是钓鱼站点。由于这种站点不仅要截取网站图像,网络IO耗费大,图像计算量也比较大,检测结果更理想,也更耗时。
模型检测过程是一个层层过滤筛选的过程,随着网络IO的消耗越大,检测的准确率也更大。其中基于页面源码和截图的检测为可选模块,可以根据实际的检测需求作取舍。
三、总结
越来越多的网络钓鱼威胁着网络安全,由情报匹配与模型检测相结合的钓鱼URL检测方案,区别于仅从URL本身特征去检测,该方案融入了其他的关联特征如whois信息、网页元素与其他网页链接的特征、图像视觉特征,是一种多层次、多维度的检测技术。该方案首先根据历史情报资源检测,充分利用了企业本身和绿盟威胁情报云实时的威胁情报,实现动态更新本地情报库,实时提升检测效果。此外,该方案不仅能够处理不同形式的数据输入,还能根据实际场景的检测需求和计算能力,灵活配置检测模块。
该方案需要将私有情报与NTI情报数据进行统一处理,生成本地情报资源,总体来说能对大部分钓鱼情形进行有效检测,对于一些包含有域名白名单的暗链钓鱼情形,依然是检测难点,需要作进一步研究。对于钓鱼URL链接的是资源文件的情形,未来或许可以根据分析链接文件特性,如文本特征对类似URL进一步判断。
参考文献
[1] CNNIC发布《全球中文钓鱼网站现状统计分析报告(2016年)》, http://news.west.cn/19371.html
[2] 卡巴斯基发布《2017年Q2垃圾邮件与网络钓鱼分析报告》, 我国依然形势严峻https://blog.nsfocus.net/2017-q2-phishing-report/
[3] 网络钓鱼大讲堂 Part1 | 网络钓鱼攻击定义及历史, https://blog.nsfocus.net/phishing-definition-history/
[4] 网络钓鱼大讲堂 Part3 | 网络钓鱼攻击向量介绍, https://blog.nsfocus.net/phishing-attack-vector/
[5] 网络钓鱼大讲堂 Part2 | 网络钓鱼风险(攻击带来的损失), https://blog.nsfocus.net/phishing-attack-risk/