摘要
机器学习在很多领域展现出其独特的优势,在过去的很多年里,我们关注更多的是封闭环境下的机器学习,即静态地收集数据并训练模型,但是在现实生活中越来越多地遇到开放环境下的任务,比如数据分布、样本类别、样本属性、评价目标等都会发生变化,这就需要模型具有较好的鲁棒性。本文重点关注流式数据中样本类别增加的问题,并给读者介绍一种可行的解决方法。
一、前言
传统的机器学习研究,大部分基于封闭静态的环境,此时在做机器学习分类任务的时候,会做一系列假设。首先假定数据分布恒定,即训练数据和预测数据来自独立同分布,其次假定样本类别恒定,即能预测数据的类别不能有别于训练集中的类别;然后假定样本属性恒定,即训练好的模型只适用于训练集中给定的属性空间;最后假定评价目标恒定。
但是现实生活并不是这样,我们会遇到越来越多开放环境下的任务,在封闭环境下做的假设可能都会被推翻。我们以网络流量为例,在不同的网络环境中,数据分布会发生变化,用某个网络环境下的数据训练的模型可能并不适用于另一个网络环境,比如随着时间的推移,恶意流量的类别会越来越多,之前训练的固定类别的模型不能检测新出现的恶意类别,再比如随着攻防的升级,攻击者可能对之前暴露出来的特征进行隐藏,恶意流量的属性空间发生变化。在这些情况下,模型的鲁棒性就变得尤为重要。
在过去的很多年里,我们关注更多的是模型的精确度,比如将模型的精度从97%提升到99%,在封闭环境下模型的表现固然重要,但在更多的现实任务中,模型的鲁棒性直接决定客户的体验,特别是在一些高风险应用,比如自动驾驶、智慧医疗等领域,相比之下,网络安全领域的风险虽然没有那么高,但是客户对误告的容忍度却不那么高,如果鲁棒性差可能直接导致模型的准确率下降到无法使用的程度。
本文关注样本类别的增加,考虑的情况是,在数据流分类问题上,随着环境的变化,流式数据中可能会出现新类,如果使用先前训练好的模型对数据流中未见过的类实例进行分类,其预测精度将严重降低。理想情况下,我们希望新类的实例在数据流中出现时就被检测到,只有可能属于已知类的实例才被传递给模型进行预测。最关键的是,在学习新类别的同时,不能将旧类学到的东西忘掉。
二、算法介绍
本节介绍应对流式数据中出现新类的一种算法,即SENCForest[1],它由SENCTree组成,为数据流中的每一个实例分配一个类标签,即新类或已知类的一种。对于数据流中的每个测试实例,检测器作为过滤器来确定它是否属于一个已知类,如果是,则将数据实例传给分类器以产生类预测,否则,这个实例将被作为一个新类存储在以前从未见过的候选类的缓冲区中,当缓冲区满时,这些候选实例将被用于更新模型。在模型更新之后,上述过程在数据流中重复。
具体来说,首先,为新出现的类训练一个检测器,即给定已知类的初始训练集,训练无监督异常检测器SENCForest;然后,使用已知的类信息由检测器构建分类器,并在数据流中进行部署,一旦训练完成,训练集将被丢弃;最后,当缓冲区满时使用缓冲区中的实例对模型进行更新,将相同的树生长过程应用于现有树的每个叶子,即替换实例数量超过限定值的叶节点;此外,为了保持模型大小,在更新的过程中还使用了SENCForest引退机制。下面介绍实现细节。
2.1 从流数据中检测异常
(1)建立一个iForest
无监督异常检测器iForest是由孤立树iTree组成的孤立森林。构建每一个iTree是为了将每个实例从训练集中孤立出来,核心思想是异常实例符合“少”和“不同”这两个特点,所以比正常实例更容易被孤立。因此,在iTree中可以使用比正常实例更少的分区来孤立异常。
使用完全随机的过程创建iTree,每个iTree都使用给定训练集中随机选择的子样本生成。具体做法是,给定一个大小随机的子样本,随机选择一个属性并在其最小值和最大值之间随机选择一个切分点产生一个分区。分区过程会递归地重复,直到子样本中的每个实例都被孤立。
(2)确定路径长度阈值
对于新类和已知类的异常,都在iTree中路径长度较短的区域内,我们将这类区域称为异常区域A,以区别于路径长度较长的正常区域K。
为了检测新出现的类,我们首先需要确定一个路径长度阈值来区分A和K,然后在每个A区域内建立一个子区域B,如图1所示,子区域B覆盖了该区域内的所有训练实例,因为这些实例来自已知的类,所以它们是已知类的异常。

由于iTree中的每个区域都有自己的路径长度,而异常区域A的路径长度预计比正常区域K的路径长度要短。为了区分这两类区域,确定路径长度阈值的方法是,将iTree中所有区域的所有路径长度按升序排列,生成一个列表L,然后使用阈值τ产生两个子列表,即左子列表Ll和右子列表Lr。使用在标准差σ上的最小化差异确定最佳阈值,具体公式如下所示:
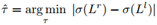
如图2所示,使用iTree展示了列表L及其SDdiff(=|σ(Lr)−σ(Ll)|)曲线的累积分布示例,其中最小SDdiff点用于划分正常区域和异常区域。
2.2 判断异常是否属于新类
(1)构建“离群”异常分区
在 确定后,使用树中每个区域A的所有训练实例构造球B,区域B为已知类的异常区域。当在每个SENCTree的所有A区域都构建了B,SENCForest的第一个功能是一个无监督检测器,可以检测新出现的类的实例。一个属于A但在B之外的测试实例是一个“离群”的异常,即一个正在出现的新类的实例。
(2)由检测器生成分类器
要使SENCForest具有分类器的功能,我们需要使用训练子样本在每个K或B区域记录类的分布,这是唯一需要类标签的步骤。一旦训练步骤完成,SENCForest就可以部署到数据流中。
(3)在数据流中部署
给定一个测试实例,SENCForest会产生一个类标签,如果测试实例位于A区域但不在B区域,则输出为“NewClass”,否则输出为已知类的一种。
值得注意的是,尽管SENCForest可以检测任意数量的新类的实例,但为了更新模型,它们被分组到新类“NewClass”中。在本文的其余部分,我们将重点关注一个时期内一个新类的模型更新(但多个新类可能出现在一个数据流的不同时期)。
如果SENCForest的输出为“NewClass”,这个实例会被放在缓冲区中,当数量达到缓冲区大小时,这些实例用于更新分类器和检测器。一旦这些更新完成,缓冲区将重置。
2.3 更新模型
模型的更新有两种机制,一种是在SENCTree中生长一个子树,另一种是生长多个SENCForest。
(1)在SENCTree中生长一个子树
用缓冲区更新SENCForest是一个简单的过程,使用从缓冲区中随机选择的实例更新每棵树中的每个叶节点。每个节点上的更新涉及到用一个新生长的子树进行替换,或者对类频率进行简单的更新,以包含新类。
如果属于叶子节点的实例总数超过限定值,则需要增长一个子树。示例如图3所述,在左上角的图中,三个新出现的类实例(绿色三角形)落在SENCTree的节点1中,一个新的子树是通过伪实例(由于没有存储训练集,所以对叶子节点生成伪实例)和新类的实例构建的,在左下角的图中,节点1被替换为这个新的子树。每个叶节点都经历相同的过程。
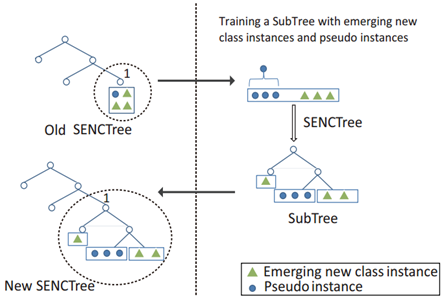
更新过程保留了原始的树结构,叶节点中的所有伪实例仍将被放置到新生长的子树的单个叶节点中。因此,在模型更新过程中,对已知类的预测不会改变。
一旦每棵树都完成了模型更新,就会重新计算 。
(2)生长多个SENCForest
当SENCForest中的类数量达到一定值时,它的SENCTree将停止为任何新出现的类而生长。一个新的SENCForest是为出现的新类而生长的。在一个有多个SENCForest的模型中,只有当所有SENCForest都预测一个实例属于新类时,最终的预测才是新类。否则,最终的预测是已知的某个类。
2.4 引退机制
随着数据流不断增多,SENCForest在以下场景被引退。
(1)当SENCForest在一段时间内不用于预测已知的类时,它将被用于任何未知类的预测,即长期输出“NewClass”的SENCForest将被淘汰;
(2)如果SENCForest的数量已经达到预设的限制,并且根据(1)没有SENCForest可以引退,那么选择在最后一段时期中对已知类做出最少预测的SENCForest进行引退。
三、小结
本文介绍了一种在流式数据中解决样本类别增加的方法,首先从流数据中检测异常,然后判断异常是否属于新类,最后对模型进行更新。在初始训练之后不需要任何标签,也不需要存储初始训练集,相较其他方法,SENCForest在KDDCup99、MNIST等数据集上表现出更优的性能。该方法的优势在于,不仅能区分已知类异常和新类实例,以高精度检测出新类,而且能在内存有限环境下的长流中有效地运行。
参考文献
[1] Xin M , Kai M T , Zhou Z H . Classification Under Streaming Emerging New Classes: A Solution Using Completely-Random Trees[J]. IEEE Transactions on Knowledge & Data Engineering, 2017, 29(8):1605-1618.
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。