大数据时代下的数据安全,不能简单看作一个传统的数据安全问题,应该看作一个新的安全问题——如何在满足数据安全和隐私保护的同时,去实现数据的流动和价值的最大化/最优化。进一步说,“鱼和熊掌兼得”(数据安全与价值挖掘)成为了大数据时代下的主旋律。
01 背景
随着5G、IoT、AI等信息技术革命的推进,现实世界的各个角落变得越来越数字化、信息化。我们已经从“小数据”时代进入“大数据”时代。据IDC统计和研究,全球数据量已经进入了 ZB(1ZB=10^12GB)级别, IDC的“大数据摩尔定律”表明,人类社会活动产生的数据一直在以每年50%的速度增长。也就是说,全球数据量将在每两年翻一番。这些数据产生来源包括云、大数据平台以及各种各样的移动端、计算机、物联网设备与网络。
图1 大数据时代下各种数据源[1]
在大数据时代背景下,由于应用环境的多样性、复杂性和特殊性,数据的安全面临多种多样的威胁与挑战:不仅依然需要面临数据窃取、篡改与伪造等传统威胁,同时也需要面对近年来出现日益增多的数据滥用、个人信息与隐私泄露、“大数据杀熟”等新的安全问题。
仅在最近的一年中,一些重大的数据泄漏事件,将数据安全推到社会各界关注的焦点,如国外Facebook由于8700万用户数据泄漏问题,影响美国一大部分人的个人数据。美国政府处罚Facebook 50亿美元的罚款(相当于公司一年总收入的9%); Google旗下的子公司Alphabet因个人数据的处理违反欧盟GDPR法规,同样处罚5000万欧元罚款。这些巨额的罚款代价足见数据安全与隐私保护的重要性。在这样的背景下,如何应对数据安全与隐私保护带来的挑战,不仅是学术界的热点探究方向,也是工业界重点关注和实践方向。与此同时,数据安全引起全球各个国家的高度重视,近几年纷纷密集颁布数据安全相关的法规以及标准,如欧盟的《通用数据保护条例》(General Data Protection Regulation,简称GDPR),美国加州的《2018年加州消费者隐私法》,国内数据相关的法律如《中华人民共和国网络安全法》。
作为一名数据安全从业者,笔者从相关法规、场景与技术以及实践体系三个方面进行整理和概述。并于最后发表了几点不成熟的思考,希望起到抛砖引玉的作用,最终与各位专家或数据安全爱好者共同探讨和分享。需要注意的是,本文讨论主题并不限制在大数据安全,而是在大数据时代下/背景下,出现的数据安全问题,因此范畴更大一些。
02 第一部分:相关法规
本节将梳理和回顾国内外的一些相关法规。数据的开放、共享、再利用是大数据时代的趋势,全球各个国家纷纷对政府数据开放进行立法。然而,数据开放共享的另一面,数据安全与隐私问题同样需要约束和规范,因此各个国家也在颁布一系列数据安全相关法规。
2.1 国外
(1)数据开放相关法规
美国《开放政府指令》
美国于2009年发布M-10-06《开放政府指令》, 提出政务透明 (transparency)、公民参与 (participation)和协同合作 (collaboration)三个基本原则。该指令首次明确提及到了数据层面的开放, 它成为后续政府数据开放的基础。其中包括:发布政府数据开放网站;要求落实到一个具体的联系人而非只有联系方式;减少信息自由法案请求的积压;发布更多数据库。在这一指令的指导下, 美国发布了全球第一个政府数据开放平台Data.gov[2]。至今, 该平台上已经发布22.9万个数据集, 涉及农业、商业、气候等14个领域。
图2 美国政府数据开放平台(https://www.data.gov)
英国《信息自由法》
英国于2005年1月正式实施《信息自由法》。规定原则上公共机构拥有的信息都是应该公开的。任何人都有权利了解包括中央和地方各级政府部门、警察、国家医疗保健系统和教育机构在内的约10万个英国公立机构的信息。被咨询机构必须在20个工作日之内予以答复[3]。同样地,英国政府也开放各行各业数据,如下图所示。

图3 英国政府数据开放网站(https://data.gov.uk/)
欧盟《公共部门信息再利用指令》
欧盟议会和理事会在2003年11月17日通过了公共部门信息再利用指令。指令提出了公共部门信息再利用的制度框架,对于相关制度进行了初步规定,其目的在于尽可能地减小欧盟各成员国在公共部门信息再利用制度方面的差异以促进公共部门信息的充分利用。对于公共部门信息再利用的收费问题,指令认为,总的收入不应该超过收集、制造、复制和传输文档的总成本[4]。
图4 欧盟开放数据平台(http://data.europa.eu/euodp/en/data)
(2) 数据安全相关法规
欧盟《通用数据保护条例》
对于个人数据的保护,欧盟于2018年5月25日正式实施了《通用数据保护条例》 (General Data Protection Regulation,简称GDPR),是一项保护欧盟公民个人隐私和数据的法律,其适用范围不仅包括欧盟成员国境内企业的个人数据、也包括欧盟境外企业处理欧盟公民的个人数据。

GDPR由11章99个条款组成,它是一项的“大而全”的个人数据保护框架。给出个人数据的处理范围十分宽泛,不仅包括一些常见的个人数据,如自然人的姓名、身份证号码、位置数据、地址信息。同时也包括与自然人相关的网络信息,如cookie,IP地址, Mac地址,以及自然人的生物识别数据,如指纹、虹膜等,因为GDPR认为,这些数据在使用合理可能手段,可以唯一确定到“自然人”。对于如何这些数据主体,给出了个人数据的处理原则、处理的合法性、同意的条件等。同时明确了数据主体拥有知情权、访问权、修正权、删除权(被遗忘权)、限制处理权(反对权)、可携带权、拒绝权等基本权利。在儿童同意的条件、跨境传输给出相应的规范和约束。特别值得关注的是,GDPR的处罚措施非常严厉,对于违反GDPR规定的,最高可以罚款2000万欧元或全球年度营业额的4%(取两者最高数值)[5]。
欧盟《非个人数据自由流动条例》
对于非个人数据的保护,欧盟委员会于2017年9月提出“促进非个人数据在欧盟境内自由流动”的立法建议。并于2018年10月4日,欧洲议会投票通过《非个人数据自由流动条例》,旨在促进欧盟境内非个人数据自由流动,消除欧盟成员国数据本地化的限制。非个人数据是指GDPR规定的“个人数据”以外的数据,比如匿名化数据,设备之间产生的数据。另外,它目的在于与已经实施生效的GDPR形成数据治理的统一框架,以此平衡个人数据保护、数据安全和欧盟数字经济发展[6-7]。
美国《健康保险隐私及责任法案》
美国于1996年颁布的《健康保险隐私及责任法案》(Health Insurance Portability and Accountability Act, HIPAA),确保健康信息的安全性和隐私性,并且保护个人的健康信息(Protected health information, PHI)。PHI数据包括个人以往、目前或将来的身体(或精神)健康或状况有关的数据;个人接受健康保健服务的相关数据;个人以往、目前或将来接受健康保健服务的费用支付相关等。隐私条例的基本规定是企业只有在隐私条例允许范围内或者获得数据主体的个人书面同意之后才能够披露PHI[8]。
美国《家庭教育权和隐私权法案》
美国于1974年颁布《家庭教育权和隐私权法案》 (Family Educational Rights and Privacy Act, FERPA),以保护学生的个人可识别信息(PII)的安全。该法案适用于所有接受联邦基金的教育机构。还规定,未满18岁的学生或符合条件的学生家长可以查看并申请修正学生的教育记录。该法案还规定,学校必须取得学生家长或符合条件的学生的书面允许才可发布学生的个人验证信息[9]。
美国《2018年加州消费者隐私法》
2018年6月28日,美国加州通过《2018加州消费者隐私法案》(California Consumer Privacy Act, CCPA)该法案被称为美国“最严厉和最全面的个人隐私保护法案”,将于2020年1月1日生效。CCPA规定,要求企业披露其所收集的消费者个人信息的类别、收集或出售、使用信息的目的。同时,CCPA也赋予了消费者创建了访问权、删除权、知情权等一系列隐私权利。在处罚方面,若企业违反隐私保护要求,将面临支付给每位消费者最高750美元的赔偿金以及最高7500美元的民事处罚[10]。
2.3 国内
(1) 数据开放相关法规
《中华人民共和国政府信息公开条例》
我国于2019年5月15日正式实施《中华人民共和国政府信息公开条例》,旨在保障人民群众依法获取政府信息。条例规定,坚持“公开为常态、不公开为例外”的原则,凡是能主动公开的一律主动公开。积极扩大主动公开范围和深度,根据政务公开实践发展要求,明确各级行政机关应当主动公开机关职能、机构设置、行政处罚等行为的依据条件程序、公务员招考、国民经济和社会发展统计信息等十五类信息。除主动公开信息外,也规定公民、法人或者其他组织可以依法向政府部分申请获取相关政府信息[11-12]。
图5 国家数据网站(http://data.stats.gov.cn/)
《北京市公共数据开放管理办法》(征求意见稿)
北京市于4月23日发布《北京市公共数据开放管理办法》(征求意见稿)。管理办法第十一条指出,建设市、区两级大数据管理平台,通过该平台实现全市公共数据的目录管理、汇聚、共享、开放和利用。这显示北京市政府开放数据的力度。第二十五条规定,促进数据利用,推动社会主体对开放数据的创新应用和价值挖掘[13]。在北京市政务数据资源网中,已经有基于公开数据开放的多个应用,包括“逛逛博物馆”APP自助导览、E上学、智慧学路——学生通勤时段北京道路拥堵分析与预测等等。

图6 北京市政务数据资源网(http://data.beijing.gov.cn/)
《上海市公共数据开放管理办法(草案)》
上海市政府于2019年4月30日发布《上海市公共数据开放管理办法》(征求意见稿),旨在促进和规范公共数据的开放和利用,推动数字经济发展,提升政府治理能力和公共服务水平。值得关注的是该办法的第七条,相比北京市的法规,增大了开放范围,对于一些敏感不能开放的数据,如涉及商业秘密、个人隐私等开放会对第三方合法权益造成损害的,但经过脱敏、脱密处理可以开放的,或者第三方同意开放的公共数据,是可以开放的[14],这条法规对于一些共享场景是十分有利的。
图7 上海市政府数据服务网(http://data.sh.gov.cn/)
《贵州省大数据发展应用促进条例》
贵州省作为我国首个大数据创新基地,于2016年3月1日正式实施《贵州省大数据发展应用促进条例》。这是我国首部大数据地方法规,它包括大数据发展应用、共享开放和安全管理等内容。值得关注的是,数据的共享开放是大数据发展应用的重要基础和核心内容。条例规定,全省统一的大数据平台(以下简称“云上贵州”)汇集、存储、共享、开放全省公共数据及其他数据(第二十六条)。并且,鼓励单位和个人对共享开放的数据进行分析、挖掘、研究,开展大数据开发和创新应用(第三十条)。这奠定了公共数据共享、挖掘、利用产生价值的基调[15]。
(2) 数据安全相关法规
《中华人民共和国网络安全法》
我国于2017年6月1日正式实施《中华人民共和国网络安全法》(通常简称《网安法》)。《网安法》是我国首部全面规范网络空间安全管理方面问题的基础性法律,包含的内容十分丰富,一共包括7章79条,包含网络运行安全、关键信息基础设施的运行安全、网络信息安全等内容。值得关注的是,《网安法》在数据安全也有诸多规定。包括第十八条,国家鼓励开发网络数据安全保护和利用技术,促进公共数据资源开放,推动技术创新和经济社会发展。第四十至四十五条明确规定了网络运营者收集、使用个人信息应当遵循合法、正当、必要的原则,用户知情同意、修正等权利。其中第四十二条规定,网络运营者不得泄露、篡改、毁损其收集的个人信息;未经被收集者同意,不得向他人提供个人信息。但是,经过处理无法识别特定个人且不能复原的除外。这条说明并没有完全去限制住个人信息数据的流动,给出该类敏感数据共享、使用和挖掘和发挥价值的出路[16]。
《个人信息和重要数据出境安全评估办法》(征求意见稿)
2017年4月11日发布《个人信息和重要数据出境安全评估办法》征求意见稿。征求意见稿中确立了安全评估的适用范围、评估程序、监管机构、评估内容等基本规则。在后续的《数据出境安全评估指南》征求意见稿中,根据法规指导,明确具体地给出了个人信息、敏感数据的评估要点、方法和流程等内容[17]。
《数据安全管理办法》(征求意见稿)
2019年5月28日国家互联网信息办公室发布《数据安全管理办法》(征求意见稿)。明确管理范围是中华人民共和国境内利用网络开展数据收集、存储、传输、处理、使用等活动(第二条),数据安全分为个人信息和重要数据安全(第一条)。征求意见稿中包括数据收集、数据处理使用和数据安全监督管理等内容。数据处理内容中值得关注的是,第二十三条,网络运营者利用用户数据和算法推送新闻信息、商业广告等(以下简称“定向推送”),应当以明显方式标明“定推”字样,为用户提供停止接收定向推送信息的功能;用户选择停止接收定向推送信息时,应当停止推送,并删除已经收集的设备识别码等用户数据和个人信息。这条对当前火热的用户画像技术对这一行为进行了严格的约束,提升了用户的体验和个人数据的安全。特别地,对于个人信息的安全具体实施,最近几年密集制定了一系列的标准和规范,包括《个人信息安全规范》、《个人信息去标识化指南》(征求意见稿)和《个人信息安全影响评估指南》(征求意见稿)[18]。
其他的一些法律
行业的法规,比如2013年9月1日正式实施的《电信和互联网用户个人信息保护规定》,旨在保护电信和互联网用户个人信息的合法权益。一些地方性法规,比如《贵州省大数据安全保障条例》已于2019年8月1日通过,并于2019年10月1日起正式施行。条例明确大数据安全责任单位内部职责,规定在数据采集、使用、处理需要进行一定和必要的数据安全措施,以及违反条例相应一些法律责任等。此外,《个人信息保护法》是一部系统的保护个人信息的法律条款,目前尚在制订中,值得期待。
对于个人信息的保护,法规-标准逐渐趋于体系化。
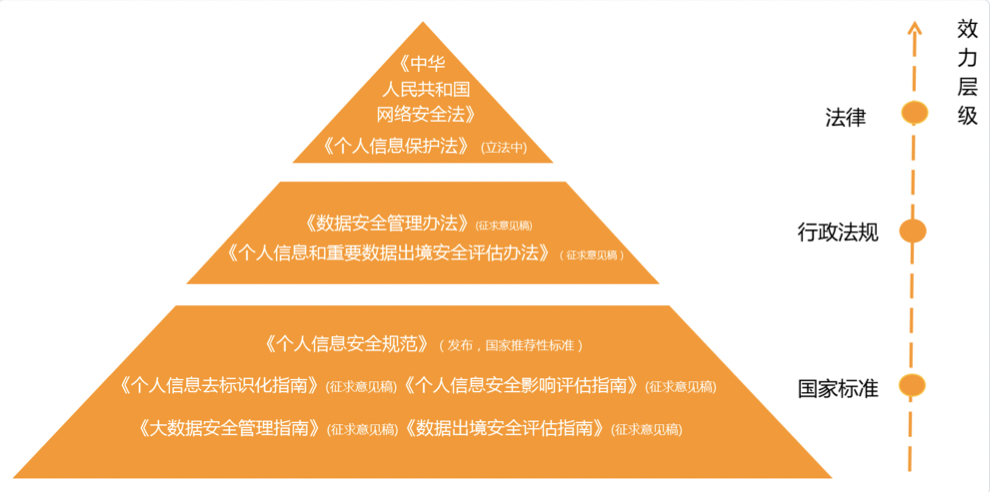
图8 国内数据安全相关法规-标准体系
03 第二部分:场景技术
本节将从数据安全的六个典型场景中分别进行阐述,包括安全传输、数据脱敏、匿名化、差分隐私、同态加密和数据溯源。
3.1 安全传输
安全场景
数据的安全传输是传统的数据安全场景,最早可以追溯到二战时期的军事保密通信。后面随着计算机等终端的普及和网络技术的发展,以及安全传输的需求增长,数据的安全传输场景非常普遍。比如,张三给李四发送邮件,需要实现电子邮件从张三电脑安全传输到李四的电脑,如下示意图所示。

图9 邮件数据安全传输场景
安全需求
在数据安全通信中,要实现数据传输的不可窃听和不可篡改两个基本的安全需求。
关键技术
为了达到防窃听的目的,可使用加密技术。加密技术包括对称密码技术和非对称密码技术。对称加密通信的双方使用同一个密钥进行加密与解密;在非对称加密通信中,发送方使用公钥加密,接收方使用私钥解密。一般来说,非对称加密比对称加密更加安全,但需要消耗更多的时间。另外,为了实现数据传输过程的不可篡改,发送方一般使用签名或散列函数技术,接收方验证签名或哈希认证码。若未验证通过,则请求再次发送。
国际密码标准包括分组密码算法AES、3DES、IDES、非对称加密算法包括RSA、Elgamal等;哈希函数包括MD5、SHA1、SHA-256和SHA-512;数字签名包括DSA、ECDSA。国密标准算法包括分组密码算法SM1(算法不公开,存储在芯片中)、SM4,非对称加密算法包括基于ECC的SM2, 哈希函数包括SM3以及数字签名算法SM9。

3.2 数据脱敏
安全场景
数据脱敏是企业处理与保护敏感数据的普遍场景之一。具体来说,产品测试,对外公开、培训、敏感数据分析与统计等场景均需要使用脱敏后的数据,以降低数据的敏感度或者保护用户的隐私。比如小明需要使用公司的用户信息数据库,以测试产品应用的功能。为了防止这些敏感的个人信息被泄露,那么需要经过一定处理。一般来说,不会直接使用加密技术,因为加密会破坏数据展示和使用价值。取而代之的技术是在数据可用性和安全性进行折中处理,比如姓名仅保留姓、年龄进行模糊处理(四舍五入)、电话屏蔽中间四位。具体场景示意图所示。

图10 测试场景:使用脱敏数据
安全需求
如前所述,脱敏场景的需求是在保留一定的数据可用性基础上,降低数据的敏感度、或者保护用户的隐私。具体的需求需根据业务的应用进行定制化调整。比如某一个业务场景需要分析真实的年龄分布,那么保留年龄的统计分布,同时对年龄进行重排;另一个场景需要分析年龄与体重的关系,那么需要尽可能保留年龄和体重数据的真实性,就不能使用重排方法,尽量使用量化失真方法。
关键技术
脱敏方法/策略有多样,可以看作失真和变形一系列的集合。以下表格列举一些典型的脱敏方法/策略。具体使用哪种脱敏方法,需要根据业务场景,如数据的使用目的、以及脱敏级别等需求去选择和调整。
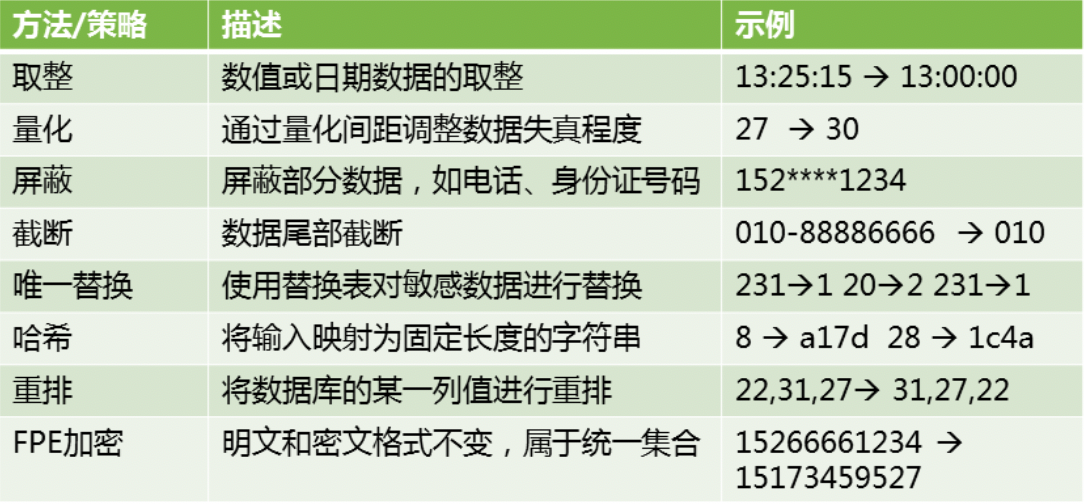
图11 常见脱敏方法/策略
其中,保留格式加密(Format-Preserving Encryption,FPE)是一种特殊的加密方式,其输出的密文格式仍然与明文相同。比如中国联通手机号15266661234,通过FPE加密可以实现仍然输出的是联通手机号15173459527。 FPE加密应用时,需考虑格式及分段约束,这与一般的对称分组加密不同。为了规范FPE技术实施,美国NIST发布了FF1标准算法,可用于保险号、银行卡号、社保卡号等数字标识符的加密。
3.3 匿名化
安全场景
含个人信息的数据库发布或挖掘(Privacy Preserving Data Publishing,PPDP,或Privacy Preserving Data Mining, PPDM)。比如医疗患者信息的对外共享或公开,有利于保险行业和疾病研究科学家的分析与研究。一般来说,直接去掉姓名、身份证标识符等信息,剩余公开的数据仍然存在患者隐私泄露风险。例如一个经典案例,美国马萨诸塞州发布了医疗患者信息数据库(DB1),去掉患者的姓名和地址信息,仅保留患者的{ZIP, Birthday, Sex, Diagnosis,…}信息。另外有另一个可获得的数据库(DB2),是州选民的登记表,包括选民的{ZIP, Birthday, Sex, Name, Address,…}详细个人信息。攻击者将这两个数据库的同属性段{ ZIP, Birthday, Sex}进行链接操作,可以恢复出大部分选民的医疗健康信息,从而导致选民的医疗隐私数据泄露[19]。
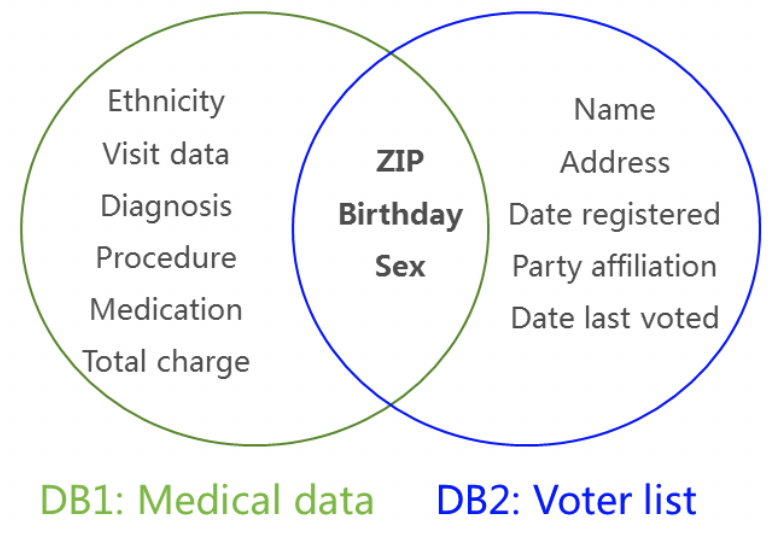
图12 链接攻击:两个数据库的链接
安全需求
以上场景的需求即是隐私保护的需求,即如何更好地保护隐私属性。通俗地讲,如何使得发布数据库的任意一条记录的隐私属性(疾病记录等)不能对应到某一个“自然人”,无法实现“重识别”,即切断“自然人”身份属性与隐私属性的关联。
关键技术
对于匿名化技术,最早由美国学者Sweeney提出,设计了K匿名化模型(K-Anonymity)。即通过对个人信息数据库的匿名化处理,可以使得除隐私属性外,其他属性组合相同的值至少有K个记录。下图展示了一个公司处理薪资敏感信息实现2-匿名化的过程。

图13 2-匿名化示例:保护薪资隐私信息
除K匿名化外,还发展和衍生出了(α, k)-匿名 ((α, k)–Anonymity)[20]、L-多样性 (L-Diversity)[21] 和T-接近性 (T-closeness)[22]模型。在具体应用时,需要根据业务场景(隐私保护程度和数据使用目的)进行选择。
3.4 差分隐私
安全场景
典型的场景是公开统计数据库开放的场景。比如医院提供医疗信息统计数据接口,某一天张三去医院看病,攻击者在张三去之前(第一次)查询统计数据接口,显示糖尿病患者是人数是99人,去之后攻击者再次查询,显示糖尿病患者是100人。那么攻击者推断,张三一定患病。该例子应用到了背景知识和差分攻击。
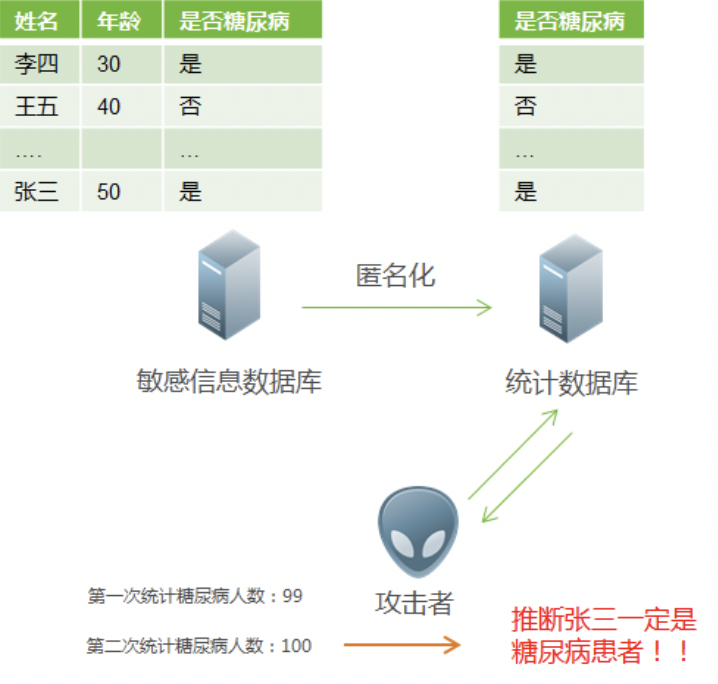
图14 攻击场景:应用背景知识和差分攻击获取隐私信息
安全需求
上述场景要求设计一种算法,可以最大化统计数据库的查询准确性的同时,也能控制隐私泄露的风险。
关键技术
为了这个需求,差分隐私技术应运而生。这项技术最早由微软研究者Dwork 在2011年提出[23]。它通过在查询结果加入噪声(比如Laplace噪声),使得查询结果在一定范围内失真,那么可以抵抗差分攻击。比如上述场景,第一次查询结果是99个,第二次查询概率为 p结果为99个, 1-p的概率结果是100个,那么攻击者无法准确地确认张三是否患病。如何平衡差分隐私技术的查询准确率和隐私保护能力是学术界近年来的一个研究热点。对于差分隐私应用,一些公司开始应用该项技术。比如iPhone使用差分隐私技术用户隐私,在可获得统计行为的同时,避免用户隐私的泄露,Google也进行类似的应用,通过Chrome浏览器使用差分隐私技术采集用户行为统计数据。
3.5 同态加密
安全场景
不可信任第三方平台(比如公有云环境)上传的加密数据仍然可以被计算、检索与处理。
安全需求
不可信的第三方平台无法解密和查看数据,但仍然可以执行密文处理操作,比如统计、分析和检索等操作,以在处理中保护数据和隐私的安全。
关键技术
同态加密满足上述需求的一项关键的技术之一。其加密函数具有以下性质,
Enc(A)°Enc(B)=Enc(A*B)
该性质称为同态性。通俗地讲,在密文域进行*操作相当于在明文域进行操作。这种性质使得密文域的数据处理、分析或检索等成为可能。如下示意图所示,张三将加密的数据Enc(A)、Enc(B)存储到不可信的云平台中,李四提交两个密文对应的*的任务,那么云计算平台执行密文操作Enc(A)°Enc(B)。从始至终,云平台一直没有接触到相关的明文信息。
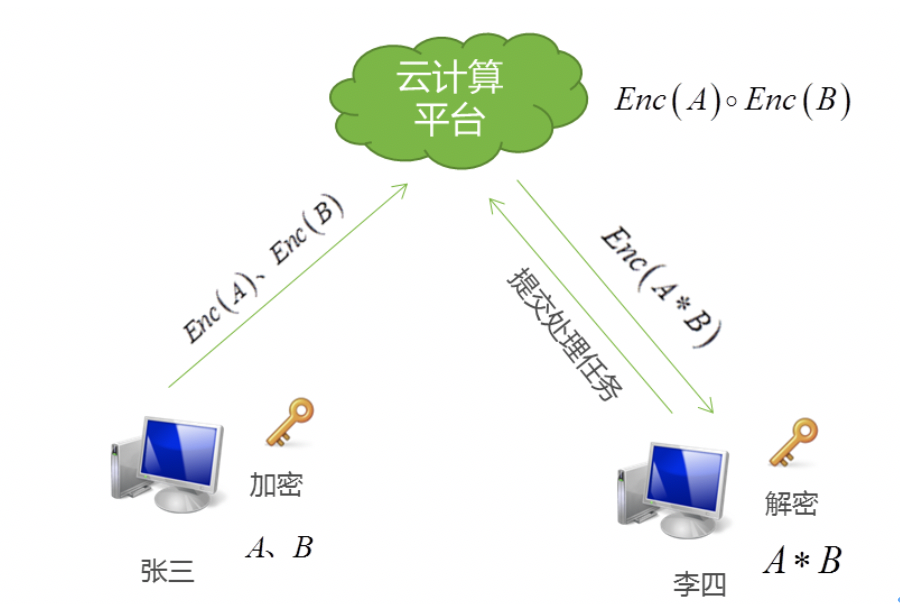
图15 同态加密在云平台的应用
3.6 数据溯源
安全场景
据统计其中大部分数据泄露事件原因,是内部人员造成和引起的。可见数据泄露事件发生后,数据溯源和追责十分重要。
安全需求
下发和使用的数据记录嵌入使用者的ID信息、时间等信息。这些信息对于数据使用者来说不可感知的,且几乎不影响数据的使用价值。
关键技术
数据库水印是数据管理和溯源的一项关键技术。通过改变数据库记录属性的值或者插入新的伪造记录实现嵌入水印信息。嵌入水印需要具有鲁棒性,即嵌入水印的数据表需要抵抗攻击者尝试的插入、替换、删除行/列等攻击。下图展示了数据库水印追踪溯源的过程。

图16 通过水印技术追踪数据泄露者
04 第三部分:实践体系
上节将数据安全一些相关场景和技术列出来进行分析和阐述,但缺乏体系化和系统化的框架。随着企业业务丰富和扩展,数据越来越多种多样,越来越庞大,相应的数据安全问题也变得越来越复杂。单独使用一两种技术难以应对;此外,数据安全并不仅是一个技术问题,还涉及到法律法规、标准流程、人员管理等问题。因此,一套科学的数据安全实践体系对于企业来说是十分必要的。近年来,一些安全相关的企业纷纷提出数据安全的实践体系、方法论与解决方案。主要分为两类:一类是“由上而下”的数据安全治理体系;另一类是数据安全能力成熟度模型体系。
4.1 数据安全治理框架体系
数据安全治理 (Data Security Governance,DSG)最早由Gartner在 2017安全与风险管理峰会上提出。 在Gartner Summit2019进一步完善。Gartner 认为数据安全治理是从决策层到技术层,从管理制度到工具支撑,自上而下贯穿整个组织架构的完整链条。组织内的各个层级之间需要对数据安全治理的目标达成共识,确保采取合理和适当的措施,以最有效的方式保护数字资产。其安全治理框架如下图所示,一共共分为5步,“由上而下”,从平衡业务需求、风险、合规、威胁到实施安全产品、为保护产品配置策略。
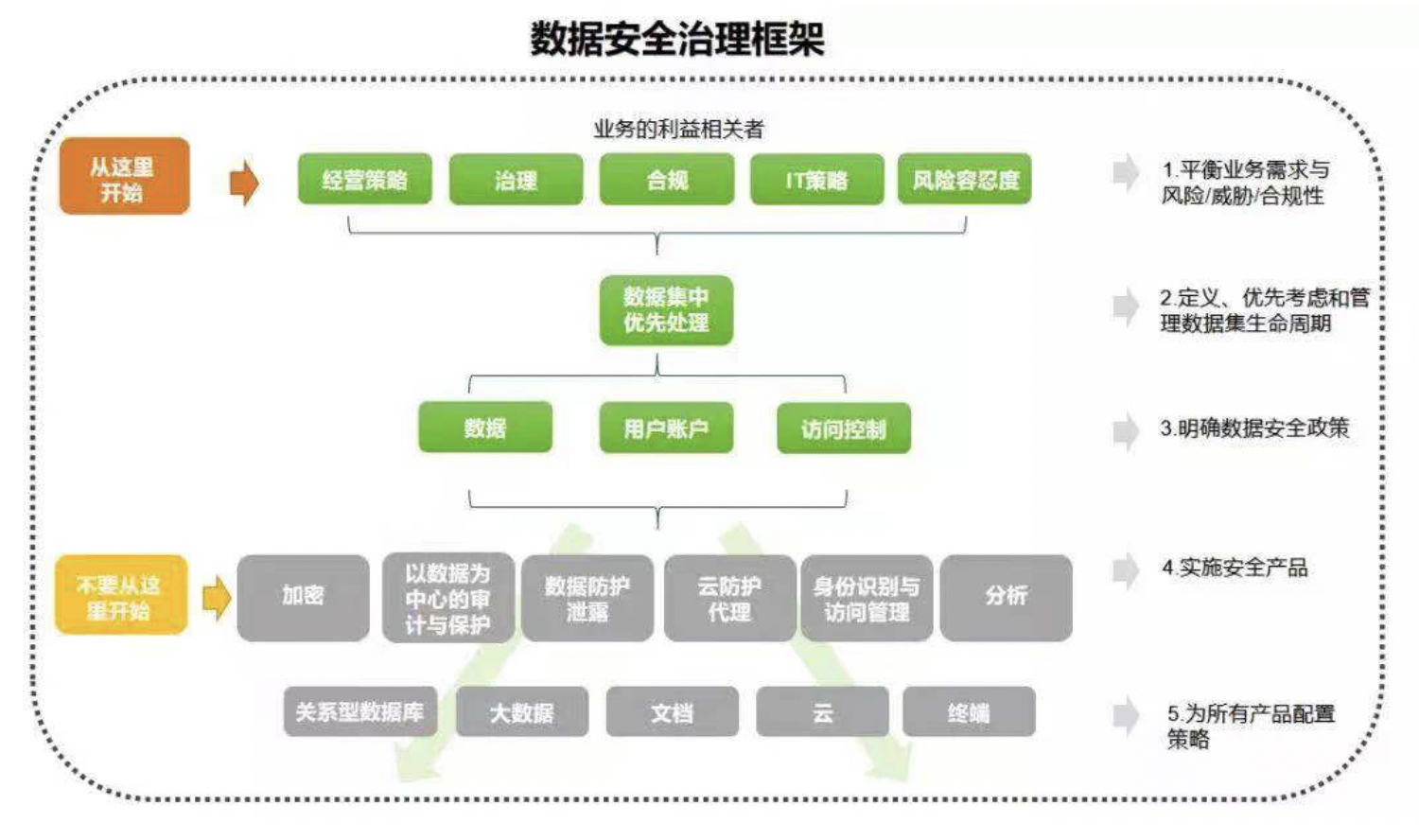
图17 Gartner数据安全治理框架[24]
绿盟数据安全解决方案在Gartner治理框架基础上,结合客户的数据安全防护需求,对实际情况进行研究和实践,分析总结出了一套完整又科学的数据安全治理方法体系[25-26]。该体系分为四个基本治理步骤—— “知”、“识”、“控”、“察”。

图18 绿盟数据安全解决方案[24]
知:分析政策法规,如中国的《中华人民共和国网络安全法》、欧盟的《General Data Protection Regulation》(简称《GDPR》)等;及时梳理业务及人员对数据的使用规范,定义敏感数据;
识:根据定义好的敏感数据,利用工具对全网进行敏感数据扫描发现,对发现的数据进行数据定位、数据分类、数据分级。这一步十分重要,直接决定后续治理步骤和数据保护的质量;
控:根据敏感数据的级别,设定数据在全生命周期中的可用范围,利用规范和工具对数据进行细粒度的权限管控;
察:对数据进行监督监察,保障数据在可控范围内正常使用的同时,也对非法的数据行为进行了记录,为事后取证留下了清晰准确的日志信息。如使用审计或行为分析工具UEBA。对应Gartner治理框架的第二步。
4.2 数据安全能力成熟度模型体系
数据安全能力成熟度模型最早由阿里提出,现在处于标准化进程中(《信息安全技术 数据安全能力成熟度模型》(修订稿))。在该修订稿中,将模型架构由分成三方面构成(如图10所示)[25]:
- 数据生命周期安全: 围绕数据生命周期, 提炼出大数据环境下,以数据为中心, 针对数据生命周期各阶段建立的相关数据安全过程域体系。
- 安全能力维度: 明确组织机构在各数据安全领域所需要具备的能力维度, 明确为制度流程、人员能力、组织建设和技术工具四个关键能力的维度。
- 能力成熟度等级:基于统一的分级标准, 细化组织机构在各数据安全过程域的 5 个级别的能力成熟度分级要求。
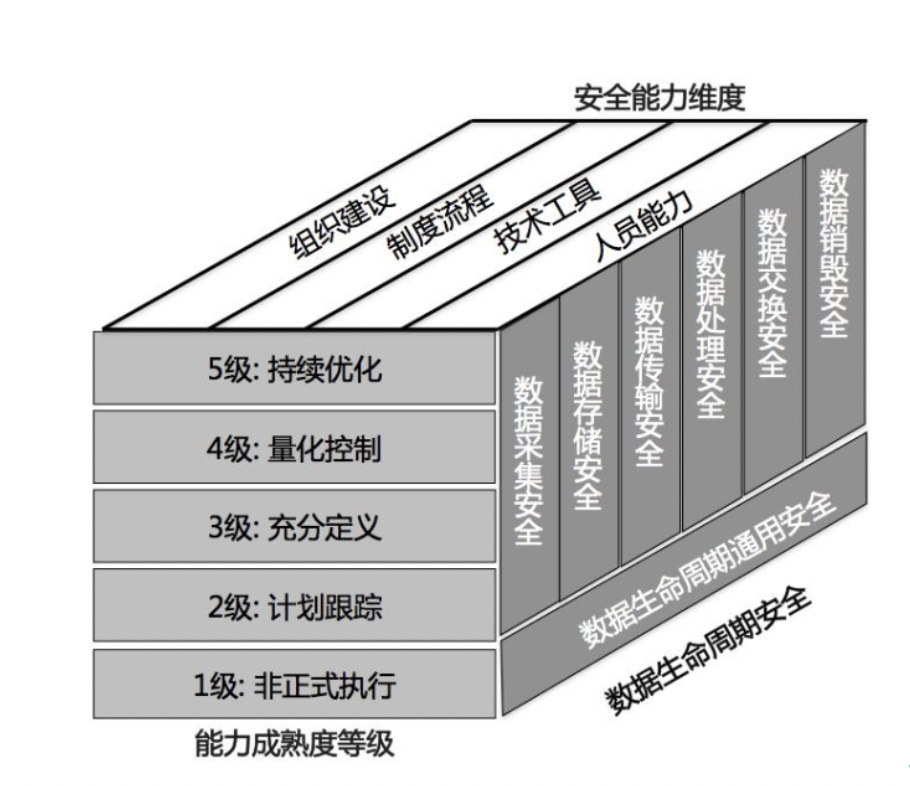
图19数据安全能力成熟度模型架构[25]
以数据生命周期为主线,其数据安全过程域体系,分为数据生命周期通用的安全和各生命周期阶段下的安全,包含一系列相应的内容、方法和策略,如图11所示[25]。
 图20数据安全过程域体系[25]
图20数据安全过程域体系[25]
05 关于数据安全的几点思考
通过政策法规的研究,场景和技术的梳理,以及实践体系的调研。从市场和技术视角看,笔者有以下几点观察与思考。抛砖引玉,欢迎各位共同讨论。
- 数据安全与隐私合规是未来几年企业数据安全建设和治理的重要驱动力:据普华永道调查报告,68%的美国公司预计将花费100万到1000万美元投入来满足GDPR,还有9%的企业预计投入将超过1000万美元[26]。国外的《GDPR》、《2018年加州消费者隐私法》等严厉的处罚,迫使企业尽快部署和实施数据安全相关的措施与产品。国内近几年来数据安全相关的法规和标准体系密集颁布和建立,同样促使国内企业,特别存储和处理大量数据的企业,未雨绸缪,大数据开发与数据安全进行同步建设。
- 个人数据与隐私保护是2C企业重要梳理的合规方向:面向消费者的企业,特别是互联网公司,运营商、银行等,掌握大量的个人信息与敏感数据。为了满足法规,需在数据采集、传输、处理、共享和销毁等全生命周期投入精力和成本进行建设和部署。
- 平衡数据可用性和安全性是隐私保护的关键方向:不管使用脱敏、匿名化还是差分隐私技术,最终都需在数据可用性(0-100%)和安全性(0-100%)一对矛盾中,根据业务场景需求寻找合适的平衡点。
- 隐私保护处理后的个人信息“重识别”和隐私泄露风险需根据实际场景进行评估:在实际应用中,对于风险评估,攻击目的、攻击成本以及背景知识的假设在实际中,应该是合理和可能的。
- 分类分级是数据安全防护的前提:特别在混杂的大数据环境,信息多种多样,且包括普通数据,敏感数据,个人信息,分类分级决定了后续数据安全治理的质量。
- 数据安全需要学术界和工业界紧密合作:总体来说,数据安全与隐私保护技术仍然滞后于数据挖掘/利用技术。一些隐私保护模型、算法在企业实践、落地面临各种各样的困难与挑战。只有学术界与工业界紧密结合,提出一些重要理论,解决一些关键性问题,才能使得这些算法真正地广泛应用。
- “鱼和熊掌兼得”是最终目标:在大数据时代,数据的价值在于流动,最终需要实现数据的开发、利用、挖掘、共享和融合;但数据安全和隐私保护问题需要妥当处理。那么大数据时代下,它们两者之间的关系是:
大数据技术 + 数据安全技术 = 让数据在安全流动中发挥最大的价值!
参考资料
- 绿盟数据安全解决方案信息安全技术,绿盟数据安全技术专刊,2019
- 蔡婧璇, 黄如花. 美国政府数据开放的政策法规保障及对我国的启示[J]. 图书与情报, 2017(1).
- http://www.istis.sh.cn/list/list.aspx?id=1367
- 冉从敬, 陈通晓, 李楠, 等. 欧盟公共部门信息再利用制度研究[J]. 图书馆论坛, 2010 (6): 244-247.
- https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=uriserv:OJ.L_.2016.119.01.0001.01.ENG&toc=OJ:L:2016:119:TOC
- http://www.sohu.com/a/259650011_99943543
- https://www.secrss.com/articles/5639
- 大数据安全标准化白皮书 全国信息安全标准化技术委员会 大数据安全标准特别工作组
- https://searchsecurity.techtarget.com.cn/whatis/11-25320/
- http://li-yan.blog.caixin.com/archives/183275
- http://www.gov.cn/zhengce/content/2019-04/15/content_5382991.htm
- http://www.gd.gov.cn/gdywdt/zwzt/zfxxgktl/
- http://www.beijing.gov.cn/zfxxgk/110069/zwdt53/2019-04/26/content_b3f43884b1d9493b9348c086b614ee74.shtml
- http://www.sheitc.sh.gov.cn/gg/682371.htm
- http://www.gzrd.gov.cn/dffg/sgdfxfg/23501.shtml
- http://www.xinhuanet.com//politics/2016-11/07/c_1119867015_3.htm
- http://www.zhonglun.com/Content/2017/09-22/1521375229.html
- http://www.moj.gov.cn/news/content/2019-05/28/zlk_235861.html
- Sweeney L. K-anonymity: A model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-based Systems, 2002,10(5):557-570.
- Wong R C, Li J, Fu A W, et al. (α, k)-anonymity: An enhanced kanonymity model for privacy-preserving data publishing [C]. The 12thACM SIGKDD International Conference on Knowledge Discovery andData Mining, Philadelphia, PA, USA, August 20-23, 2006.
- l-diversity:Pri-vacy beyondk-anonymity. Machanavajjhala A,Gehrke J,Kifer D,et al. Proceedings of the 22th International Conference on Data Engineering . 2006
- Li N H, Li T C, Venkatasubramanian S. t-Closeness-privacy beyond kanonymity and l -diversity [C]. IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, April 15-20, 2007: 106-115.
- Dwork C. Differential privacy[J]. Encyclopedia of Cryptography and Security, 2011: 338-340.
- 绿盟科技公众号:数据为王 安全至上
- 数据安全能力成熟度模型(征求意见稿)2017-08-17
- https://www.aqniu.com/learn/30670.html