图数据库所提供的关联分析能力是金融反欺诈、威胁情报、黑产打击和案件溯源等业务所需要的核心能力。图数据库的需求非常多,例如金融安全业务希望使用图数据库进行金融反欺诈关联分析、威胁情报业务希望通过图数据库进行黑产研究和情报分析、还有社交关系分析、知识图谱等需求场景。
图数据库应用背景
金融机构每年因欺诈带来的坏账损失每年高达数百万美元。随着在线数据量的增长,骗子的行骗能力也水涨船高,精心设计的骗局、身份窃取、欺诈手段及一些新型的诈骗手段层出不穷,方法复杂且容易广泛复制,当事后发现时,已经太迟了,客户和企业往往已经损失惨重。
使用关系数据库来进行欺诈侦测不是不可行,但表形式并不适合描述数据之间的某些特定的复杂关系,而且在海量数据的情况下,表之间的JOIN操作会带来大量系统性能的损耗,单次运算时间甚至以小时计,导致反欺诈策略无法实时返回结果。与关系数据库相反,图数据库是基于现实世界的描述,非常易于理解,也非常容易能形成信息之间的链接,可以轻松遍历整个图来对欺诈活动进行实时侦测。图数据库以图论为基础,数据本身以图的方式存储(比如邻接表),在处理与图相关的任务时占有先天的优势。
图数据库所提供的关联分析能力是金融反欺诈、威胁情报、黑产打击和案件溯源等业务所需要的核心能力。图数据库的需求非常多,例如金融安全业务希望使用图数据库进行金融反欺诈关联分析、威胁情报业务希望通过图数据库进行黑产研究和情报分析、还有社交关系分析、知识图谱等需求场景。
本文首先介绍了Tinkerpop这种图计算框架,然后介绍了一种基于Tinkerpop的分布式图数据库JanusGraph。
Tinkerpop
简介
图是由点和边组成的数据结构。当在计算机中构建一个图并应用于现代数据集和实践时,以计算为导向的二元图支持标签和key/value键值对。这种结构称为属性图。或更正式的成为一个有方向的,二元的,多属性的图。属性图的例子如果下图所示。
图形数据库是NoSQL数据库的一种类型,它应用图形理论存储实体之间的关系信息。最常见的例子,就是社会网络中人与人之间的关系。关系型数据库用于存储关系型数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷。 Google的图形计算系统名为Pregel。
目前主流的图数据库有:Neo4j,FlockDB,GraphDB,InfiniteGraph,Titan,JanusGraph,Pregel等。
图计算引擎多种多样。最出名的是有内存的、单机的图计算引擎Cassovary和分布式的图计算引擎Pegasus和Giraph。大部分分布式图计算引擎基于Google发布的Pregel白皮书,其中讲述了Google如何使用图计算引擎来计算网页排名。
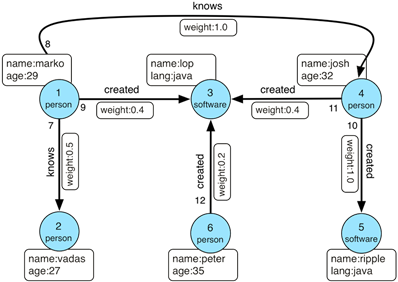
图2.1 属性图示例
Tinkerpop3是tinkerpop图计算框架的第三代产品。跟一般计算相似,图计算在结构(图)和处理(遍历)做了区分。图的结构是由点、边和属性定义的数据模型。图数据的处理是基于图结构进行分析。图处理的典型方式称为遍历。
Tinkerpop结构
Tinkerpop处理是图结构的数据,它的结构API的基础组件包括如下几部分:
Graph:维护点和边的集合,数据库访问如事务;
Element:维护属性和标签(表示元素的类型)的集合;
Vertex:继承Element,并维护入边和出边集合;
Edge:继承Element,并维护入点和出点集合;
Property<V>:字符串key关联V ;
VertexProperty<V>:字符串key关联V,并且V也可以是Property<U>的集合。
Tinkerpop处理机制
Tinkerpop的处理主要是遍历,它的 处理API的基础组件包括如下几部分:
TraversalSource:遍历的生产者,domain specific language (DSL),执行引擎;
Traversal<S,E>:数据流处理的功能,将类型为S对象转化为对象为类型为E对象;
GraphTraversal:遍历的DSL,是面向语义的原始图;
GraphComputer:在多机器集群并行处理图的系统;
VertexProgram:通过消息传递进行通信,用逻辑并行的方式在所有点上执行的代码;
MapReduce:并行的分析图中所有的点,对结果进行归约的计算。
当一个图系统实现的TinkerPop3的结构和处理API,则该系统是支持TinkerPop3的并且跟其他支持TinkerPop3的图系统在时间复杂度和空间复杂度是没有区别的。
Tinkerpop系统结构

图2.2 Tinkerpop 系统框架
TinkerPop是由多个可共同操作的组件组成的架构。Core TinkerPop3 API是整个架构的基础,它定义了什么是点、边和属性。一个图系统至少要实现 Core API。一旦实现,就可在系统中是有Gremlin遍历语言。然而图系统的提供者还可以特定的TraversalStrategy优化策略,允许系统在执行Gremlin查询时对其进行优化(例如索引查询,步骤重排序)。如果使图系统具有处理功能(OLAP),则需要实现GraphComputer API,它定义了消息或遍历器是如何在工作者(线程或机器)之间进行交互和传递的。一旦实现,Gremlin遍历可以在图数据库(OLTP)和图处理器(OLAP)上执行。然而,Gremlin语言是基于图的领域特定语言,根据点和边来解释图。用户也可以创建自己的领域特定语言。最后,采用Gremlin Server使用用户连接支持Tinkerpop的图系统,Gremlin Server提供了可配置的交互接口和度量,这就是Tinkerpop。
Gremlin简介
Gremlin是Apache TinkerPop框架下的图遍历语言。Gremlin是一种函数式数据流语言,可以使得用户使用简洁的方式表述复杂的属性图(property graph)的遍历或查询。每个Gremlin遍历由一系列步骤(可能存在嵌套)组成,每一步都在数据流(data stream)上执行一个原子操作。
Gremlin包括三个基本的操作:
- map-step:对数据流中的对象进行转换;
- filter-step:对数据流中的对象就行过滤;
- sideEffect-step:对数据流进行计算统计。
OLTP 和 OLAP遍历
Gremlin遵循“一次编写,到处运行”的设计哲学。这意味着不仅所有的TinkerPop启用的图形系统都能执行Gremlin遍历,而且每个Gremlin遍历都可以被评估为实时数据库查询或批处理查询。(前者被称为在线交易流程(OLTP),后者被称为在线分析流程(OLAP))。
协调多种图遍历
Gremlin遍历机具有更好的普遍性。这种分布式、基于图形的虚拟机了解如何协调多机器图遍历的执行,用户不需要学习数据库查询语言和域特定的BigData分析语言(例如Spark DSL,MapReduce等)。Gremlin是构建基于图的应用程序所必要的,其余一切都交给Gremlin遍历机处理。
命令式和声明式遍历
Gremlin遍历可以以命令式(程序式)方式,声明性(描述性)方式编写,也可以包含命令性和声明性的混合方式编写。
命令式编写方式
获得Gremlin合作者的上司名字分布:
g.V().has("name","gremlin").as("a").
out("created").in("created").
where(neq("a")).
in("manages").
groupCount().by("name")
一个命令式的Gremlin遍历告诉运行器如何执行遍历中的每一步;然后,遍历器分裂到所有的“Gremlin”的合作者(去除Gremlin自己);下一步,遍历器走到“Gremlin”合作者的上司(managers),最终根据上司的名字进行统计分发。
之所以是命令式的Gremlin遍历,就是它明确地、程序化地告诉遍历器“去这里,然后去那里”。
声明式编写方式
以下使用声明式编写方式实现了同样的结果:
g.V().match(
as("a").has("name","gremlin"),
as("a").out("created").as("b"),
as("b").in("created").as("c"),
as("c").in("manages").as("d"),
where("a",neq("c"))).
select("d").
groupCount().by("name")
声明式的Gremlin遍历并不能告诉遍历器执行它们的步骤的顺序,而是允许每个遍历器从一个(可能嵌套的)模式的集合中选择一个模式来执行。
然而,声明遍历具有额外的好处,它不仅利用了编译时查询计划器(如命令式遍历),而且还是一个运行时查询计划器,根据每个模式的历史统计信息选择下一个执行哪个遍历模式 – 有利于那些倾向于减少/过滤大多数数据的模式。
用户可以选择上述提出的方式编写自己的遍历语句。不管怎样,用户的遍历语句都会根据具体的执行引擎和遍历策略traversal strategies被重写。Gremlin为用户提供灵活性表达自己的查询的;图系统也针对具体启用TinkerPop的数据系统进行有效地评估图遍历提供了灵活性。
无缝嵌入主语言
经典数据库查询语言(如SQL)被认为与最终在生产环境中使用的编程语言截然不同。因此,经典数据库要求开发人员既要编写主编程语言,还要编写数据库相应的查询语言。Gremlin统一了这个划分,因为遍历可以用支持功能组合和嵌套(主要编程语言都支持)的任何编程语言编写。因此,用户的Gremlin遍历可以使用应用程序语言(主语言,Host language)编写,并受益于主语言及其工具(例如类型检查,语法高亮,点完成等)所提供的优点。目前存在各种Gremlin语言变体,包括:Gremlin-Java,Gremlin-Groovy,Gremlin-Python,Gremlin-Scala等。
比较以下两种方式,高低立判:
public class GremlinTinkerPopExample {
public void run(String name, String property) {
Graph graph = GraphFactory.open(...);
GraphTraversalSource g = graph.traversal();
double avg = g.V().has("name", name).
out("knows").out("created").
values(property).mean().next();
System.out.println("Average rating: " + avg);
}
}
public class SqlJdbcExample {
public void run(String name, String property) {
Connection connection = DriverManager.getConnection(...)
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery(
"SELECT AVG(pr." + property + ") as AVERAGE FROM PERSONS p1" +
"INNER JOIN KNOWS k ON k.person1 = p1.id " +
"INNER JOIN PERSONS p2 ON p2.id = k.person2 " +
"INNER JOIN CREATED c ON c.person = p2.id " +
"INNER JOIN PROJECTS pr ON pr.id = c.project " +
"WHERE p.name = '" + name + "');
System.out.println("Average rating: " + result.next().getDouble("AVERAGE")
}
}
Janusgraph图数据库
JanusGraph是一个可扩展的图数据库,可以把包含数千亿个顶点和边的图存储在多机集群上。它支持事务,支持数千用户实时、并发访问存储在其中的图。
我们可以将图数据库系统的应用领域划分成以下两部分:
1用于联机事务图的持久化技术(通常直接实时地从应用程序中访问)。这类技术被称为图数据库,它们和“通常的”关系型数据库世界中的联机事务处理(Online Transactional Processing,OLTP)数据库是一样的。
2用于离线图分析的技术(通常都是按照一系列步骤执行)。这类技术被称为图计算引擎。它们可以和其他大数据分析技术看做一类,如数据挖掘和联机分析处理(Online Analytical Processing,OLAP)。
Janusgraph功能
JanusGraph最大的一个好处就是:可以扩展图数据的处理,能支持实时图遍历和分析查询。
因为JanusGraph是分布式的,可以自由的扩展集群节点的,因此,它可以利用很大的集群,也就可以存储很大的包含数千亿个节点和边的图。由于它又支持实时、数千用户并发遍历图和分析查询图的功能。所以这两个特点是它显著的优势。
它支持以下功能:
(1)分布式部署,因此,支持集群;
(2)可以存储大图,比如包含数千亿Vertices和edges的图;
(3)支持数千用户实时、并发访问;
(4)集群节点可以线性扩展,以支持更大的图和更多的并发访问用户;
(5)数据分布式存储,并且每一份数据都有多个副本,因此,有更好的计算性能和容错性;
(6)支持在多个数据中心做高可用,支持热备份;
(7)支持各种后端存储系统,目前标准支持以下四种,当然也可以增加第三方的存储系统:Cassandra、HBase、Google Cloud Bigtable和BerkeleyDB;
(8)通过集成大数据平台,比如Apache Spark、Apache Giraph、Apache Hadoop等,支持全局图数据分析、报表、ETL;
(9)支持geo(Gene Expression Omnibus,基因数据分析)、numeric range(这个的含义不清楚);
(10) 集成ElasticSearch、Apache Solr、Apache Lucene等系统后,可以支持全文搜索;
(11) 原生集成Apache TinkerPop图技术栈,包括Gremlin graph query language、Gremlin graph server、Gremin applications;
(12) 开源,基于Apache 2 Licence。
JanuGraph图数据框架
JanusGraph是一个图数据库引擎。JanusGraph集中在图的序列化,图的数据模型和高效的查询。此外,JanusGraph依赖hadoop来做图的统计和批量图操作。JanusGraph为数据存储,索引和客户端访问实现了粗粒度的模块接口。JanusGraph的模块架构能和和许多存储、索引、客户端技术集成。可以简便的扩展新的功能。
JanusGraph标准支持下列存储适配和索引适配, 同时也支持第三方适配数据存储:
- Apache Cassandra
- Apache HBase
- Oracle Berkeley DB Java Edition
索引,加快查询和复杂查询
- Elasticsearch
- Apache Solr
- Apache Lucene
通常,应用通过两种方法与JanusGraph交互:
1当从本地或者远程检索数据, 内嵌在应用中的JanusGraph,运行Gremlin查询,JanusGraph缓存和事务处理和应用在同一个JVM上;
2通过提交Gremlin查询,和本地或者远程的JanusGraph实例交互,JanusGraph原生支持Gremlin Server 组件(TinkerPop stack)。
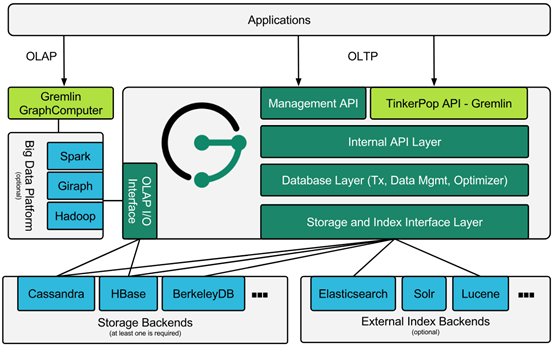
Figure 3.1. 高级架构和上下文
JanusGraph数据批量导入实例
每个JanusGraph都有一个schema,该schema由edge labels,property keys和vertex labels组成。JanusGraph的schema可以显式或隐式创建,推荐用户采用显式定义的方式。JanusGraph的schema是可以在使用过程中修改的,而且不会导致服务宕机,也不会拖慢查询速度。
数据准备
在数据导入之前需要显示的定义数据模式,模式定义写在schema.groovy文件中。
def defineGratefulDeadSchema(janusGraph) {
m = janusGraph.openManagement()
person = m.makeVertexLabel("person").make()
//使用IncrementBulkLoader导入时,去掉下面注释
//blid = m.makePropertyKey("bulkLoader.vertex.id").dataType(Long.class).make()
birth = m.makePropertyKey("birth").dataType(Date.class).make()
age = m.makePropertyKey("age").dataType(Integer.class).make()
name = m.makePropertyKey("name").dataType(String.class).make()
//index
index = m.buildIndex("nameCompositeIndex", Vertex.class).addKey(name).unique().buildCompositeIndex()
//使用IncrementBulkLoader导入时,去掉下面注释
//bidIndex = m.buildIndex("byBulkLoaderVertexId", Vertex.class).addKey(blid).indexOnly(person).buildCompositeIndex()
m.commit()
}
数据格式如下图所示,存放在data.json文件中

数据导入
首先需要启动Hbase,打开gremlin。
./bin/gremlin.bat
接着,创建shcema,可以将下面整个粘贴到命令行中。会等待一些时间,执行完成后,在hbase中会看到多了janusgraph表,并且查询到里面有了数据(是配置以及schema数据)。
:load schema.groovy
graph = JanusGraphFactory.open('janusgraph-test.properties')
defineGratefulDeadSchema(graph)
使用OneTimeBulkLoader批量导入,导入完成后hbase中又会多出3行数据(json文件中数据已经被到入成功了)。
graph = GraphFactory.open('data/zl/hadoop-graphson.properties')
blvp = BulkLoaderVertexProgram.build().bulkLoader(OneTimeBulkLoader).
writeGraph('janusgraph-test.properties').create(graph)
graph.compute(SparkGraphComputer).program(blvp).submit().get()
可以通过如下命令查看导入的节点数据。
graph = JanusGraphFactory.open('janusgraph-test.properties')
g = graph.traversal()
g.V().valueMap()
IncrementBulkLoader批量导入
- 首先停掉gremlin console
- 删除hbase中的janusgraph表
- 将schema.groovy文件中的注释代码去掉。
- 在janusgraph-test.properties设置storage.batch-loading=true。
- 我使用的是Git Bash命令终端。
打开gremlin
./bin/gremlin.bat
创建shcema,可以将下面整个粘贴到命令行中。会等待一些时间,执行完成后,在hbase中会看到多了janusgraph表,并且查询到里面有了数据(是配置以及schema数据),因为schema多了两行代码,所以数据也会多几行。
:load data/zl/test-janusgraph-schema.groovy
graph = JanusGraphFactory.open('janusgraph-test.properties')
defineGratefulDeadSchema(graph)
使用IncrementBulkLoader批量导入,导入完成后hbase中又会多出3行数据(json文件中数据已经被到入成功了)。
graph = GraphFactory.open('hadoop-graphson.properties')
blvp = BulkLoaderVertexProgram.build().writeGraph('janusgraph-test.properties').
create(graph)
graph.compute(SparkGraphComputer).program(blvp).submit().get()
OneTimeBulkLoader:一次批量导入数据,不会保存源图(此案例是json)中的id,导入数据不会开启事务。IncrementBulkLoader:增量导入数据,并且通过bulkLoader.vertex.id属性保存源图中的id值,对于id已导入过数据会执行更新操作。为此每导入一个顶点数据都会执行如下逻辑:获取要导入顶点的id值,查询图中是否有某个顶点的bulkLoader.vertex.id值等于id值的,如果等于,则使用要插入的值,更新该图中已存在的顶点属性;如果不存在,则直接添加。
参考文献
1 百度百科-图形数据库,https://baike.baidu.com/item/图形数据库/5199451?fr=aladdin
2 JanusGraph官方网站,http://janusgraph.org/
3 TinkerPop官方网站,http://tinkerpop.apache.org/