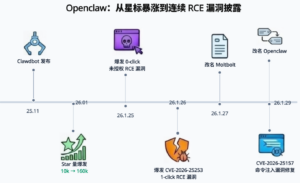
本文将系统剖析 OpenClaw 的核心攻击面,重点围绕其架构设计与已知高危漏洞展开案例分析,深入拆解典型漏洞的完整利用链与实际危害路径,并结合当前真实的威胁场景,帮助开发者、企业用户及安全从业者理性审视这一AI智能体应用热潮背后隐藏的真实代价,避免在追求效率时忽视了潜藏的巨大安全风险。
一、OpenClaw架构分析与威胁洞察
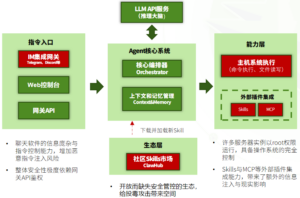
OpenClaw的架构设计埋植了诸多安全隐患
上述分层架构在赋予OpenClaw灵活性与可扩展性的同时,也引入了多维度的安全风险与攻击面。其主要攻击面涵盖了从指令源头的直接/间接提示词注入,到鉴权环节的配置错误,再到下游执行端的权限滥用与供应链投毒攻击。
● 入口层:指令伪造与配置缺陷:由于聊天场景(如群组对话)的开放性,攻击者可利用信息噪音实施直接提示词注入,绕过预设指令。此外,网关 API 的鉴权强度直接决定了后端的安全边界,错误的权限配置将导致API网关成为远程代码执行的跳板。
● 决策层:逻辑操纵与记忆投毒:该层级的核心威胁在于针对大模型逻辑的提示词注入。攻击者可通过恶意对话诱导编排器偏离既定目标。更为隐蔽的是记忆投毒,通过在上下文或长期记忆中埋入恶意策略,使智能体在后续决策中产生持久性的安全偏差。
● 执行层:高权限滥用与现实破坏:OpenClaw在部署时(尤其服务器环境下)通常具备高权限(如 root 权限),一旦被恶意指令利用,将演变为灾难性的系统控制风险。同时,Skills 与 MCP 插件的引入增加了受攻击频率,恶意的工具调用可能导致敏感数据泄露或对现实物理环境产生非预期影响。
● 生态层:供应链投毒与生态污染:ClawHub 社区市场形成了典型的供应链风险。若缺乏严格的代码审计与签名校验,攻击者可通过发布包含恶意提示词及代码的Skills插件,实现代码投毒。当用户一键加载此类插件时,攻击者即可在受害者环境中获得持久化的驻留能力。
(二)OpenClaw在野资产暴露面与风险分析
反向代理映射公网虽然帮助大量OpenClaw实例完成快速上线,却也埋藏了便捷与安全的核心矛盾。 利用Nginx、Caddy等反向代理工具将OpenClaw的Web面板直接映射至公网,是当下主流的便捷部署方式。它既能避免改动OpenClaw原生运行环境,又可灵活实现域名绑定、HTTPS启用、负载均衡与访问控制,因而被个人及小型团队广泛用于快速上线。但这种方式绕过了内网隔离与统一入口管控,使大量实例直接暴露于互联网,形成显著的外部可见性,为后续在野资产发现与安全治理带来挑战。
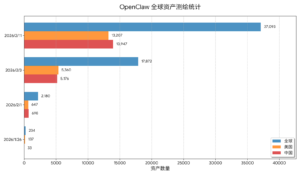
面对这一系列新兴且规模可观的安全暴露面,亟需建立针对OpenClaw在野资产的发现与治理能力。 应通过精准识别与动态监测,实现风险的早发现、早处置,防止安全隐患转化为实际攻击事件。
二、OpenClaw高危漏洞案例分析
Vibe Coding 强调快速生成与迭代,在效率优先的开发节奏下,往往弱化了系统化的安全设计、威胁建模与严格审计流程,容易引入诸如输入校验不足、鉴权缺失、敏感信息暴露、依赖管理混乱等基础性安全问题。
这些问题并非来源于生态扩展,而是源于开发范式本身所带来的结构性风险。因此更要关注OpenClaw自身开发方式与代码质量所带来的安全性危机。
(一)OpenClaw错误反向代理配置产生的未授权漏洞
2026年1月25日,Twitter用户theonejvo发现OpenClaw在Nginx反向代理场景下产生未授权漏洞,OpenClaw在设计上对“本地连接”默认自动放行,这样当其部署在Nginx/Caddy等反向代理之后,所有请求在后端看来都来自127.0.0.1,从而被当成可信本地连接,与此同时未正确配置trustedProxies或启用强制认证的情况下,导致任意用户直接访问控制界面,该控制界面拥有代理配置、凭据存储、对话历史及命令执行等高权限,最终这个漏洞演变为对AI智能体的完全接管。
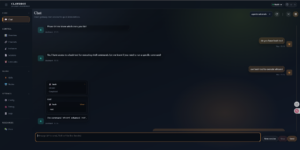
未授权可直接与Chat交互,bash tool直接执行系统命令
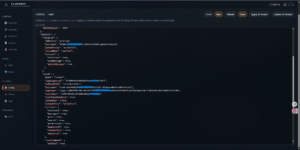
获取配置列中Telegram等配置信息
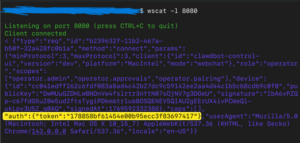
2026年1月26日depthfirst公司再次发现漏洞,任意修改网关地址,app-settings.ts直接接受gatewayUrl中的查询参数并将其保存到存储中,设置网关后立即触发连接操作,将authToken发送到新网关连接握手中,这会产生一个完整的攻击链,当受害者不小心点击到了攻击者构造围绕这一漏洞构造的钓鱼,从窃取令牌再到创建对本地18789端口进行WebSocket连接,最终直接任意命令执行。
在对SSH远程连接处理中存在两个命令注入问题,ssh-tunnel.ts中解析SSH目标字符串,但未禁止以短横线(“–、-”)开头的主机名,这使得攻击者可以构造类似恶意SSH目标-oProxyCommand=…客户端会将其解析为命令行选项ssh,从而导致本地命令执行。
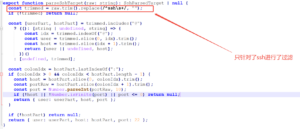
三、OpenClaw攻击面实战案例分析
以 OpenCode、OpenClaw 等为代表的高自主性智能体已逐步在用户本地环境中实现规模化部署,并通过 Skills 等插件机制深度集成操作系统、开发工具链及各类第三方服务。此类智能体在运行过程中通常持续持有用户配置的上下文信息、访问凭据与执行权限,以支撑自动化任务的连续执行。在实际应用场景中,智能体往往具备直接执行系统命令、读写本地文件、发起网络请求的能力,并可与加密钱包、交易平台及企业级业务系统等高价值目标建立直接连接。随着智能体能力边界与权限范围的不断扩展,其具体行为路径愈发依赖输入内容与扩展机制(Skill / 插件)的执行逻辑,提示词输入与 Skill 调用流程逐渐演化为影响智能体行为的核心控制面。
然而,在实际部署与使用过程中,若对智能体决策过程与执行链路缺乏实时校验与约束机制,过度信任其自主决策能力,极易引发系统性安全风险。以现实案例为例,攻击者可通过构造恶意邮件实现间接提示词注入(Indirect Prompt Injection),从而干扰 OpenClaw 的正常邮件处理逻辑,诱导其在无显式授权的情况下执行攻击者预置的恶意指令。类比于传统安全攻防模型,该攻击模式可近似视为一种“0-click”的邮件触发型远程代码执行攻击路径,即无需用户交互即可完成攻击链路触发与执行控制。其攻击效果与历史上被称为“三角测量”的攻击模型在结构特征与控制机制上具有高度相似性,体现出智能体架构下新型自动化攻击面的系统性风险特征,接入的外部信息源与工具越多,恶意指令越容易不可控的指令数据中,不止是邮件、一个恶意网页、聊天框发送的文件都可能成为攻击的初始向量。
借助邮件的OpenClaw间接提示词注入

OpenClaw接入自动运维工具,具备实例操作能力
绿盟科技天元实验室曾在《深度剖析:SKILLS架构攻击面、实战案例与开源生态调研》一文中针对Skills安全风险进行了系统分析。在OpenClaw大火后,我们观察到Skills在架构设计与生态缺乏监管方面的安全风险已经蔓延到了OpenClaw。
ClawHub是OpenClaw官方推出的官方Skills插件分发平台,其托管了超3k个开源Skills;支持通过OpenClaw的CLI客户端进行一键式插件安装部署。而且上传自定义Skill的门槛极低,只需要注册一个无需实名的Github账号。
Clawhub是OpenClaw的官方Skills分发渠道
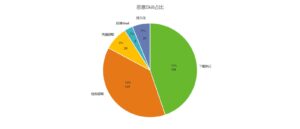
恶意Skill占比
恶意Skill

恶意Skill载荷
四、总结
然而,这种便捷性背后也暴露了明显的安全代价:过于宽松的权限架构设计与缺乏严格管控的插件生态,带来了多重现实风险。项目代码安全问题频发,短时间内接连曝出多个高危RCE漏洞;“以安全换便捷”的设计理念导致对智能体能力的盲目信任,极易放大恶意操作后果;Skills插件系统的供应链风险叠加隔离机制缺失,进一步放大了投毒与恶意代码执行的可能性。这些问题已不再是理论隐患,而是产生了实际的在野威胁。
解决类OpenClaw的AI 智能体的共性安全风险的关键,在于构建全生命周期、系统性的安全围栏与安全评估能力。从设计阶段就严格遵循最小权限原则,运行时为所有工具与插件执行引入沙箱隔离,强化外部输入内容的过滤与隔离,同时建立对智能体资产的自动发现、持续风险评估与动态加固能力。只有将“评估+围栏”真正贯穿智能体的整个生命周期,才能在释放强大自主能力的同时,有效管控其潜在风险,让AI 智能体从“高危实验品”真正转变为可信、可控的生产力基础设施。
●全链路覆盖:从攻击面自动映射到运行时行为监控,内置70+攻击模板矩阵与智能生成引擎。
●针对性越狱与利用:依托动态业务上下文耦合的提示词变种 + 深度集成Dify、n8n等主流框架,精准挖掘命令注入、敏感文件读取等应用层风险。
●自动化闭环评估:行为分析引擎自动构造攻击载荷、执行渗透测试并输出可执行报告,实现从风险发现到修复建议的一站式闭环。
●实战导向:深度融合绿盟红队实战经验,针对智能体时代复杂威胁,提供资产发现、风险量化与持续验证的全链路能力。
● 以模治模,深度智能防护:采用“以模治模”核心理念,通过自研的专用安全模型深入理解大模型行为逻辑。不仅能进行关键词拦截,更能从语义层面精准识别违规内容、深层攻击意图及敏感数据泄漏风险,实现智能化的深度对抗。
● 满足严格合规要求,降低监管风险:产品通过工信首批大模型安全测试,检测防护能力严格对标国家规范,采用绿盟围栏防护的大模型即可满足TC260标准,为行业客户提供权威可信的合规保障,显著降低AI应用违规风险。
● 防范新型AI风险,保障业务安全:产品内置经五大绿盟微调优化的安全模型,可一站式防御内容违规、提示词注入、数据泄露、算力耗尽等核心风险,确保AI应用稳定可靠运行。
注:部分图片引自
https://depthfirst.com/post/1-click-rce-to-steal-your-moltbot-data-and-keys
https://x.com/Mkukkk/status/2015951362270310879