最近审计代码过程中出现了没有正确处理url形成目录穿越,导致可以读取或下载任意文件的案例,过程很简单,由此却引发了和小伙伴的讨论,对风险的控制需要依赖框架本身还是必须从根本上规避风险点。下面就通过目录遍历漏洞的案例分析一下django的路由传参方式,以及在日常开发中如何避免此类风险。
一、示例代码
我们写一个简单的views,用来实现文件下载功能,代码如下
python
import os
from django.http import HttpResponseNotFound, HttpResponse
# Create your views here.
def file_download(request, filename):
path = '/tmp/test/2'
full_path = os.path.join(path, filename)
if not os.path.exists(full_path):
return HttpResponseNotFound('<h1>file not found</h1>')
else:
response = HttpResponse(read_file(full_path))
response['Content-Type'] = 'application/octet-stream'
response['Content-Length'] = os.path.getsize(full_path)
response['Content-Disposition'] = 'attachment; filename=%s' % filename
response['Accept-Ranges'] = 'bytes'
return response
def read_file(filename, bufsize=8192):
try:
with open(filename, 'rb') as f:
while True:
content = f.read(bufsize)
if content:
yield content
else:
break
except Exception as e:
print(e.message)
print('read error')
代码很简单,就不过多解释了,目的是提供`/tmp/test/2/`目录下的文件下载。`read_file()`使用了切片避免文件过大造成拒绝服务风险。
`/tmp/test/`结构如下,内容分别为1,2
test
├── 1
│ └── 1.txt
└── 2
└── 2.txt
有经验的同学马上就能看出`file_download()`对传入的文件名并没有任何限制,只是做了文件是否存在的判断,也就是说我们可以传入`/../1/1.txt`的文件名,`full_path`经过拼接就会成为`/tmp/test/2/../../1/1.txt`,传入`read_file()`就能够读取到1.txt
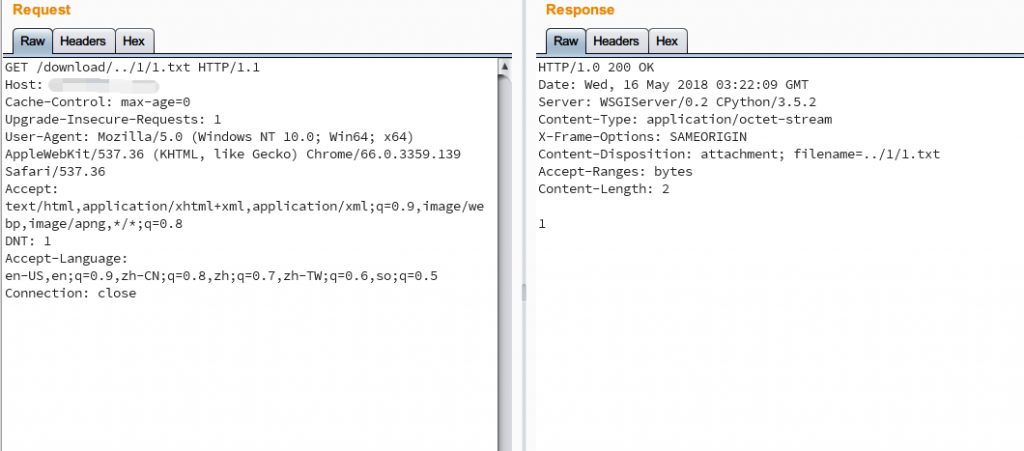
类似的,如果我们传入`../../../etc/passwd`就能下载到敏感文件
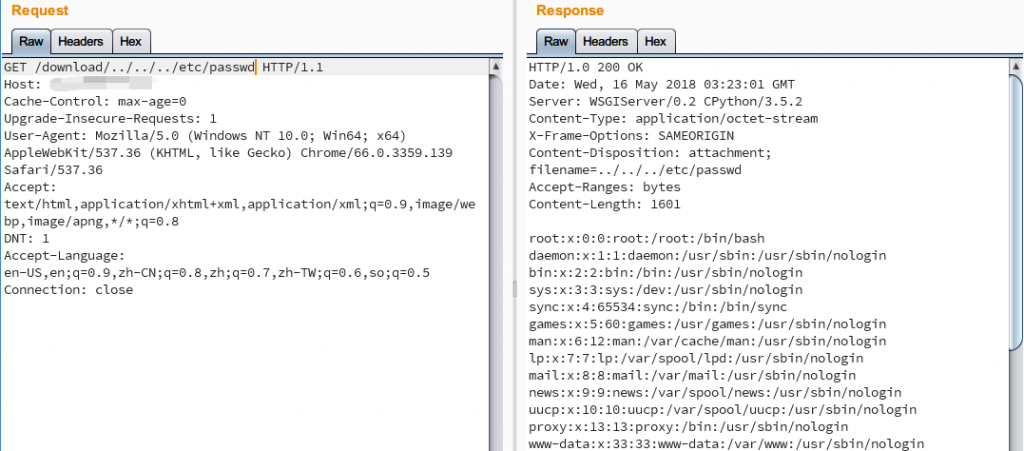
可是事实上每次都是如此吗?
其实这跟我们如何处理传入的url有关,也就是Django对于url路由的处理。
二、测试
在刚才的示例中,我们在`urls.py`中是这样定义路由的
`url(r’^download/(.+)$’, “mysite.views.file_download”),`
相信这也是很多同学会采用的写法,匹配任意文件名使得可以下载`/tmp/test/2`中的任意文件,认为在views里面限定了目录,只能读取到该文件夹下的内容,忽略了用户可以输入`../`进行目录穿越,而在接收文件名的时候却没有对参数进行任何过滤,这样就会导致一个任意文件读取的漏洞。
在django2.0中,url路由部分由`path`代替`url`,即原来的
`url(r’^articles/(?P<year>[0-9]{4})/$’, views.year_archive),`
新语法
`path(‘articles/<int:year>/’, views.year_archive),`
新语法支持url参数的类型转化。这里的year_archive函数接收到的year参数作为参数,并且会自动转换year为整型而不是字符串。
这里的int称为路径转换器,[Path converters](https://docs.djangoproject.com/en/2.0/topics/http/urls/#path-converters)
默认情况下,Django内置下面的路径转换器:
– str – **Matches any non-empty string, excluding the path separator, ‘/’.** This is the **default** if a converter isn’t included in the expression.
– int – Matches zero or any positive integer. Returns an int.
– slug – Matches any slug string consisting of ASCII letters or numbers, plus the hyphen and underscore characters. For example, building-your-1st-django-site.
– uuid – Matches a formatted UUID. To prevent multiple URLs from mapping to the same page, dashes must be included and letters must be lowercase. For example, 075194d3-6885-417e-a8a8-6c931e272f00. Returns a UUID instance.
– path – **Matches any non-empty string, including the path separator, ‘/’.** This allows you to match against a complete URL path rather than just a segment of a URL path as with str.
我们重点关注一下`str`和`path`的区别,也就是
`path(‘download/<str:filename>’, views.file_download),`
和
`path(‘download/<path:filename>’, views.file_download),`
有什么不一样。
根据[Django文档](https://docs.djangoproject.com/en/2.0/topics/http/urls/#path-converters)描述,str不匹配`/`而path匹配`/`,意味着当使用`<path:filename>`的时候我们还是可以传进去`../`
测试一下
– 使用`path(‘download/<path:filename>’, views.file_download),`的情况
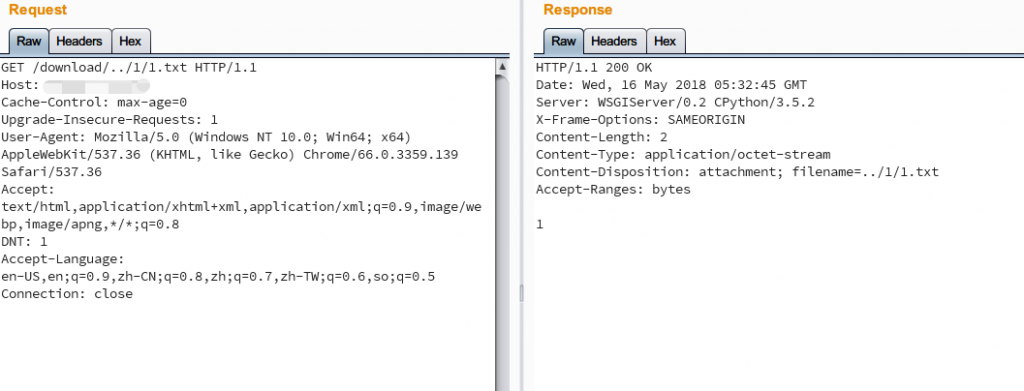
– 使用`path(‘download/<str:filename>’, views.file_download),`的情况
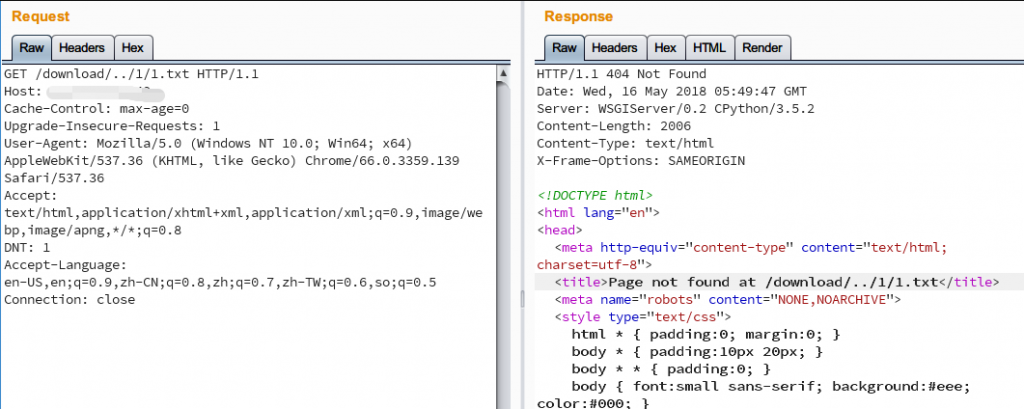
可以看到当我们定义url的时候如果使用了`<path:filename>`的形式,传入的包含`/`的参数会被原样接收,当作完整参数交给路由部分处理,而定义为`<str:filename>`(默认即为str)的时候,`/`不被后端接收,这时候`xx.com/download/../1/1.txt`这种路径下浏览器就根据url往上跳一级,也就是`xx.com/1/1.txt`,django收到了的请求也是如此,于是django抛出一个找不到对应页面的异常

Django2.0的url虽然更改了写法,但依然向老版本兼容,兼容的办法就是用`re_path()`方法代替`path()`方法
`re_path(‘download/(?P<filename>.+)’, views.file_download),`
这个匹配方式和1.8版本中`url(r’^download/(.+)$’, “mysite.views.file_download”),`的意思是一样的,只是写法不同
我们知道任何一种路由写法在经过django的urls模块相关方法处理之后都会转换为正则表达式进行匹配,之所以几种方式匹配结果不一样是因为处理完成后生成的正则不一样,把url路由转换为正则表达式的过程只会在django启动的时候编译一次,接收到的任何url形式都会根据生成的正则来路由到views定义的相关方法,urls模块就不用每次都去处理用户传递的url。
三、断点分析
我们从代码层面来看一下这几者的区别
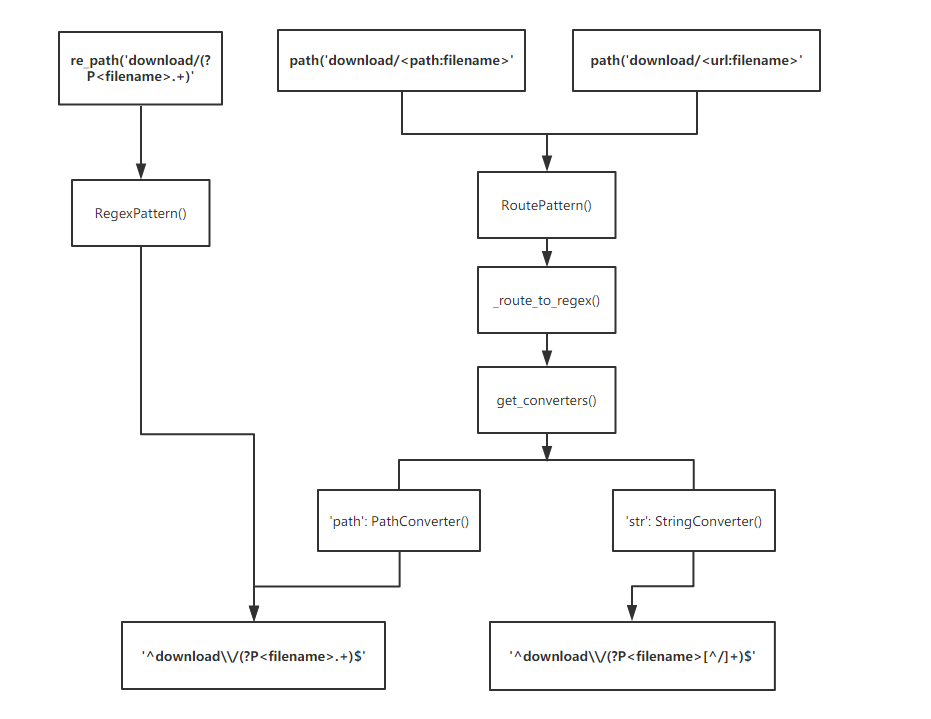
1. `re_path(‘download/(?P<filename>.+)’`方式
在`/Lib/site-packages/django/urls/conf.py`中定义了相关方法
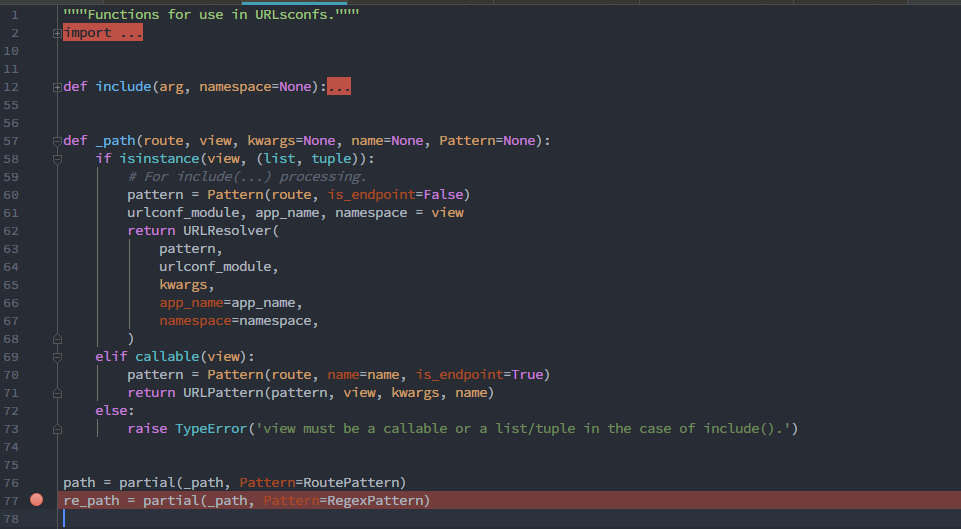
`partial()`方法的作用就是把一个函数作为另一个函数的参数传入,这里就是把`RegexPattern()`类作为参数传进`_path()`方法,因为在下面第70行`RegexPattern()`就作为处理`re_path()`时的方法
`pattern = Pattern(route, name=name, is_endpoint=True)`
跟入`RegexPattern()`类 `/Lib/site-packages/django/urls/resolvers.py:136`
构造方法之后regex就确定为我们定义的表达式,也就是`’download/(?P<filename>.+)’`
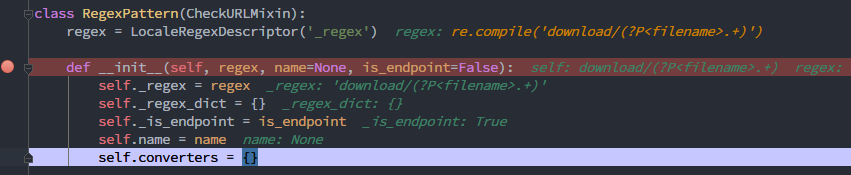
这种情况下是可以匹配任何字符串的,起不到防护目录穿越的作用
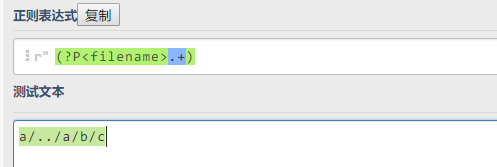
2. `path(‘download/<path:filename>’`方式
同样的,第一步还是进入到`/Lib/site-packages/django/urls/conf.py`,处理`path()`相关的就交给`RoutePattern()`类
`path = partial(_path, Pattern=RoutePattern)`
跟入`RoutePattern()`类 `/Lib/site-packages/django/urls/resolvers.py:234`
初始化过程中进行了route转换成regex的操作
python
def __init__(self, route, name=None, is_endpoint=False):
self._route = route
self._regex_dict = {}
self._is_endpoint = is_endpoint
self.name = name
self.converters = _route_to_regex(str(route), is_endpoint)[1]
跟入`_route_to_regex()`方法,`/Lib/site-packages/django/urls/resolvers.py:194`,看到该方法描述的功能就是将路径模式转换为正则表达式。
首先对我们的”路由”通过`_PATH_PARAMETER_COMPONENT_RE()`方法使用正则进行分割,
_PATH_PARAMETER_COMPONENT_RE = re.compile( r'<(?:(?P<converter>[^>:]+):)?(?P<parameter>\w+)>' )
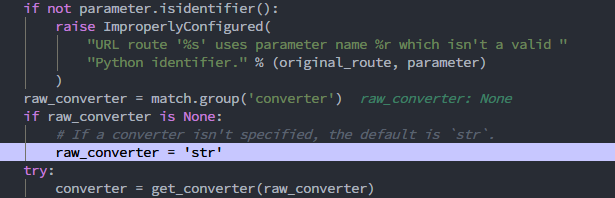
取出`converter`部分,也就是我们指定的`path`,然后判断如果`converter`为空的话就赋值为’str’,这也就是为什么我们不指定路径转换器时默认是str的原因。
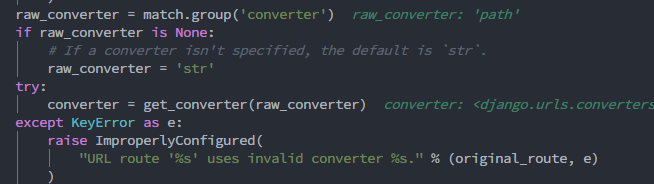

接下来对转换器部分的操作
python try: converter = get_converter(raw_converter) except KeyError as e: raise ImproperlyConfigured( "URL route '%s' uses invalid converter %s." % (original_route, e) )
跟入`get_converter()`方法,`/Lib/site-packages/django/urls/converters.py:69`
最后调用的是`get_converters()`,看到该方法里面定义了一些默认属性,这些属性的值在这个文件上方定义,
这里我们看到定义了文档中提到的5种路径转换器
python
DEFAULT_CONVERTERS = {
'int': IntConverter(),
'path': PathConverter(),
'slug': SlugConverter(),
'str': StringConverter(),
'uuid': UUIDConverter(),
}
相对应的regex值也就在这里被定义
于是在`decorating_function()`通过`cache_get()`方法取到了这些转换器对应的表达式,最后进行了拼接
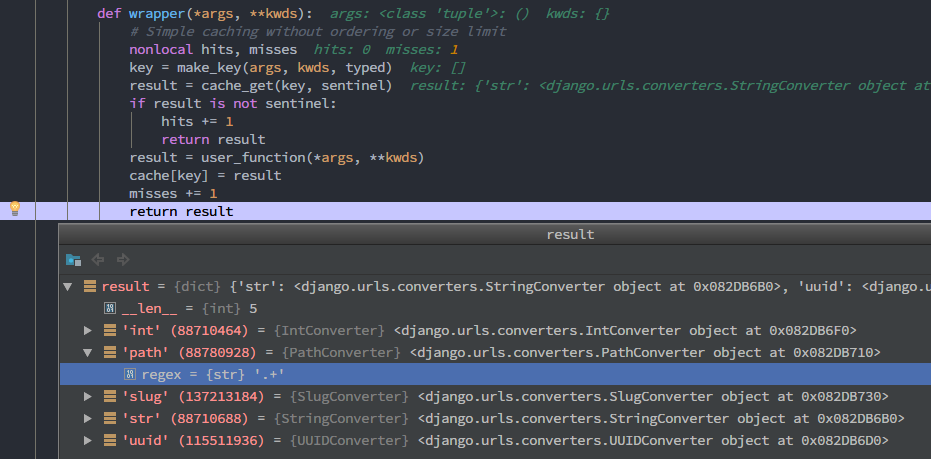
通过`parts.append`拼接
`parts.append(‘(?P<‘ + parameter + ‘>’ + converter.regex + ‘)’)`
此时的’parameter’值即为’filename’,regex值为converter对象的属性,也就是`’.+’`

最后拼接成的正则表达式为`’^download\\/(?P<filename>.+)$’`
与我们使用`re_path()`时的表达式是一样的,所以也能匹配到`../`之类的字符串,依旧起不到防止目录穿越的作用
3. `path(‘download/<str:filename>’`方式
接下来看`path(‘download/<str:filename>’`方式,不指定converter时`path(‘download/<filename>’`默认的就是这种方式
同样跟入到`RoutePattern()`类 `/Lib/site-packages/django/urls/resolvers.py:234`
流程跟上面指定`path`的方式一样,`converter`为空时设置为’str’
此时对应的regex值为`'[^/]+’`,也就是不匹配`’/’`
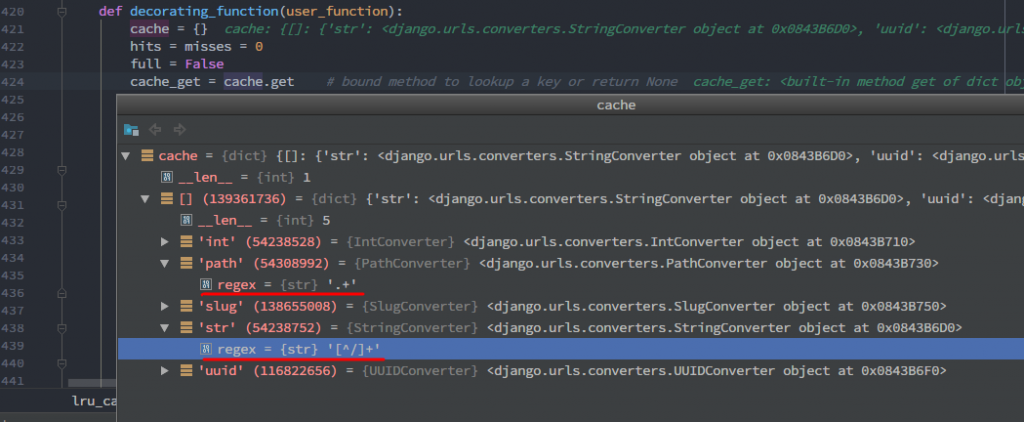

最终拼接成的正则为`’^download\\/(?P<filename>[^/]+)$’`
这种情况下由于不匹配`/`我们就无法传入`../`之类的字符串,也就不能穿越目录
流程图
画了一张简单的流程图方便理解上述三种情况
四、如何避免&正确的代码
把django处理url的各种情况理清了之后可能有同学会问,是不是以后都用`path(‘download/<str:filename>’`的方式就能避免目录穿越呢?实际上是不建议这样的,我们不能把风险点由存在缺陷的代码处转移到依赖框架上面,主要原因有二:
- 我们无法确保每次写url传递规则的时候不出错,特别是项目庞大之后为了兼顾功能而忽略一些安全隐患点;
- 存在缺陷的代码不能就这样放着,因为无法保证在别处不会调用这块代码,必须把风险点从根本上消除。
回到代码脆弱性本身,如何从根源处消除目录遍历漏洞呢?
一个想法是限定basedir,并递归过滤任何`../`之类的字符串,当然也要考虑经过url encode之后的路径,另一个简单的方法是使用`os.path.basename()`方法,这个方法会忽略前面的路径只取到文件名,可以杜绝此类漏洞。
五、总结
本文从目录遍历漏洞入手,分析了django框架处理url传递的逻辑,以及如何正确控制风险点避免出现问题代码,遵循的原则就是不要相信用户的输入,严格控制每一个参数。
感谢阅读,有任何不足之处欢迎指正。