XAI技术主要研究如何使得AI系统的行为对人类更透明、更易懂、更可信,本文主要讨论了XAI的概念、必要性、关键技术,并简要介绍基于XAI打造可信任安全智能的思考。
序
AI研究与应用不断取得突破性进展,然而高性能的复杂算法、模型及系统普遍缺乏可解释性,导致在涉及需要做出关键决策判断的国防、金融、医疗、法律、网安等领域中,或任何要求决策合规的应用中,AI技术及系统难以大范围应用。XAI技术主要研究如何使得AI系统的行为对人类更透明、更易懂、更可信,本文主要讨论了XAI的概念、必要性、关键技术,并简要介绍基于XAI打造可信任安全智能的思考。
一、 AI为何需要可解释性
1. 什么是XAI
XAI (eXplainable Artificial Intelligence) 近年来逐渐成为研究热点。KDD、ICML、NIPS及IJCAI等等著名国际性会议都有覆盖XAI话题的Workshop。美国国防高级研究计划局(DARPA)2017年发起的XAI项目,该项目从可解释的机器学习系统与模型、人机交互技术以及可解释的心理学理论三个方面,全面开展可解释性AI系统的研究。工业界方面,包括微软、谷歌、Oracle、H2O.ai等诸多科技巨头,都在开展XAI技术研发。
从概念上, XAI可定义为能够以人类可理解的方式解释其决策结果的人工智能算法及系统。XAI的核心是AI系统行为的可解释性,可以明确的是,可解释是一个与人的感受密切相关的心理学概念,从应用的角度来讲,可解释AI系统向使用者提供可以理解的辅助性内容,来提升系统决策过程的透明度,增强人对系统输出的信任。从相关学术论文中统计的词云[1]可以看出,“可解释性”内涵对应的英文单词主要包括两个:“Explainable”和“Interpretable”,一般认为AI系统的Interpretable是Explainable的基础,Explainable更强调对人类理解的支持,在此,我们可以认为两个单词都表示中文语义的“可解释性”。

图1 XAI相关词词云
2. 性能与可解释的平衡
如前文所述,“可解释”可以认为是一个心理学概念,与人的感受密切相关。机器向某个人解释某一决定,需要用此人所能理解的方式,提供更丰富的说明性内容。而人容易理解的是压缩的、概念性的、低维度可视的内容。以机器学习模型为例,低维度下的线性分类模型对人类最容易解释,而复杂的模型会降低可解释性;直线、平面、三维可视化是符合人类直觉的、易于理解的,而非线性、超平面是难以解释的;图像、声音是易于理解的,而转化为机器可读的高维数组、矩阵之后,人类就难以有直观的感受了。下图概念性的展示了不同人工智能模型的性能和可解释性的相对位置。当然,在不同的场景和数据条件下,不同模型的性能和可解释表现差异很大,但总体上我们可以得出以下趋势:模型越复杂(参数、结构等方面),能够刻画的空间越不直观,可解释性越低。天下没有免费的午餐,我们很难苛求机器完全按照人类可理解的方式去工作并输出,同时保持远高于人类的效率。目前来看,AI系统的性能与可解释性之间存在着微妙的平衡制约。因此,我们也可以得出XAI技术的目标:在提供模型可解释性的基础上,保持模型及系统的性能(识别性能、处理性能等)。
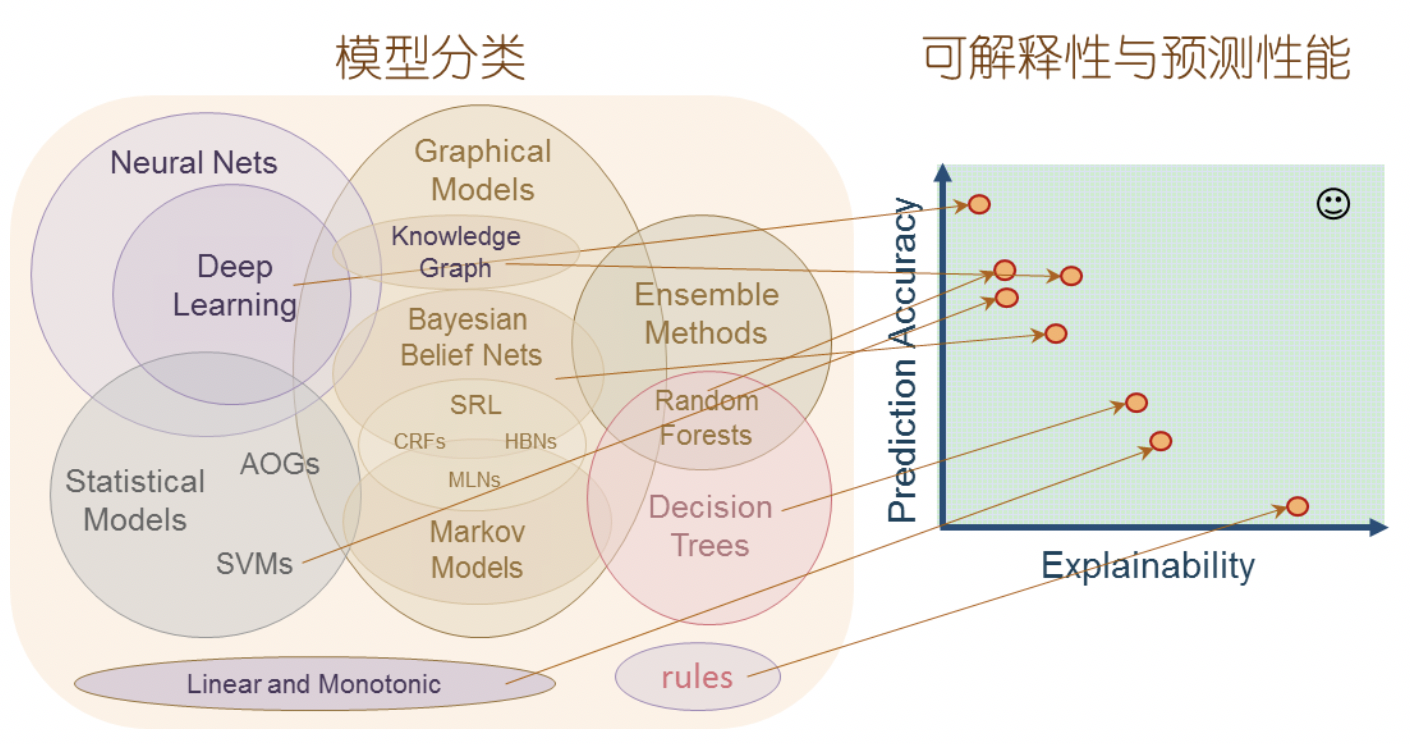
图2 AI模型的预测性能与可解释性
3. 可信任是AI应用落地的关键
基于深度学习的AI在语音、图像、知识图谱等多个领域大放异彩。AI算法广泛应用的几个场景中,如语音交互、人脸识别、智能推荐等,我们似乎看不到可解释性技术的应用。这些智能体一方面还处于在机器智能的早期感知阶段,另一方面他们所处理的任务都不是“关键性”任务。医生不能仅根据模型的分类置信度进行诊断,金融机构不能仅凭借模型的输出轻易判断违约风险,军方不能仅依赖自动的图像识别执行打击任务,安全公司也不能仅通过模型检测结果完全自动化威胁响应。能够在关键决策领域落地应用的AI,应该是可信任的AI。可信任,一方面AI系统的性能要足够高,即能够弥补人类在数据处理上的低效性;此外,需要AI本身的鲁棒性,能够适应或优化后适应不同的使用环境;AI自身的安全性也是搭载系统是否值得信任的关键;最后,AI系统需要以足够透明的方式输出其判断和决策。不可信任的AI,不能够胜任任何政治、经济、安全攸关的关键性场景,这将大大降低其可用性和适用性。

图3 缺乏可解释性的机器学习系统[2]
4. 可解释是建立信任的基础
以基于机器学习的AI系统为例,传统的模型性能评估方法,如accuracy, precision, recall, F1-Score、ROC曲线、MAE等等,是建模中的关键环节,也是衡量不同模型之间有效性的关键度量。但这些传统指标难以回答AI系统落地实践过程中的一个核心问题“我们如何信任模型的预测?”而信任是任何关键性决策的基础,如果没有人类可理解的解释性说明,AI产出的决策不能够被信任,这将大幅降低这些领域内任务处理的自动化程度。下图是DARPA对XAI系统的一个示意[3],当前阶段,多数高性能、复杂的AI系统都不具备可解释性。特别是基于深度神经网络的系统,端到端的学习给语音、图像识别等问题提供了绝佳的解决方案。例如,通过层级的卷积-激活-池化单元构成的CNN网络结构,测试集上的准确率可能达到了99.9%,并且以93%的概率预测图片为一只猫。然而该系统却无法解答使用者的关于系统推断过程的多个“为什么”。而这些问题,恰恰是系统获取人类信任的基础。XAI技术则通过增强系统的透明性、可解释性,让人类更容易理解机器的行为,以及机器做出任何判断背后的逻辑。
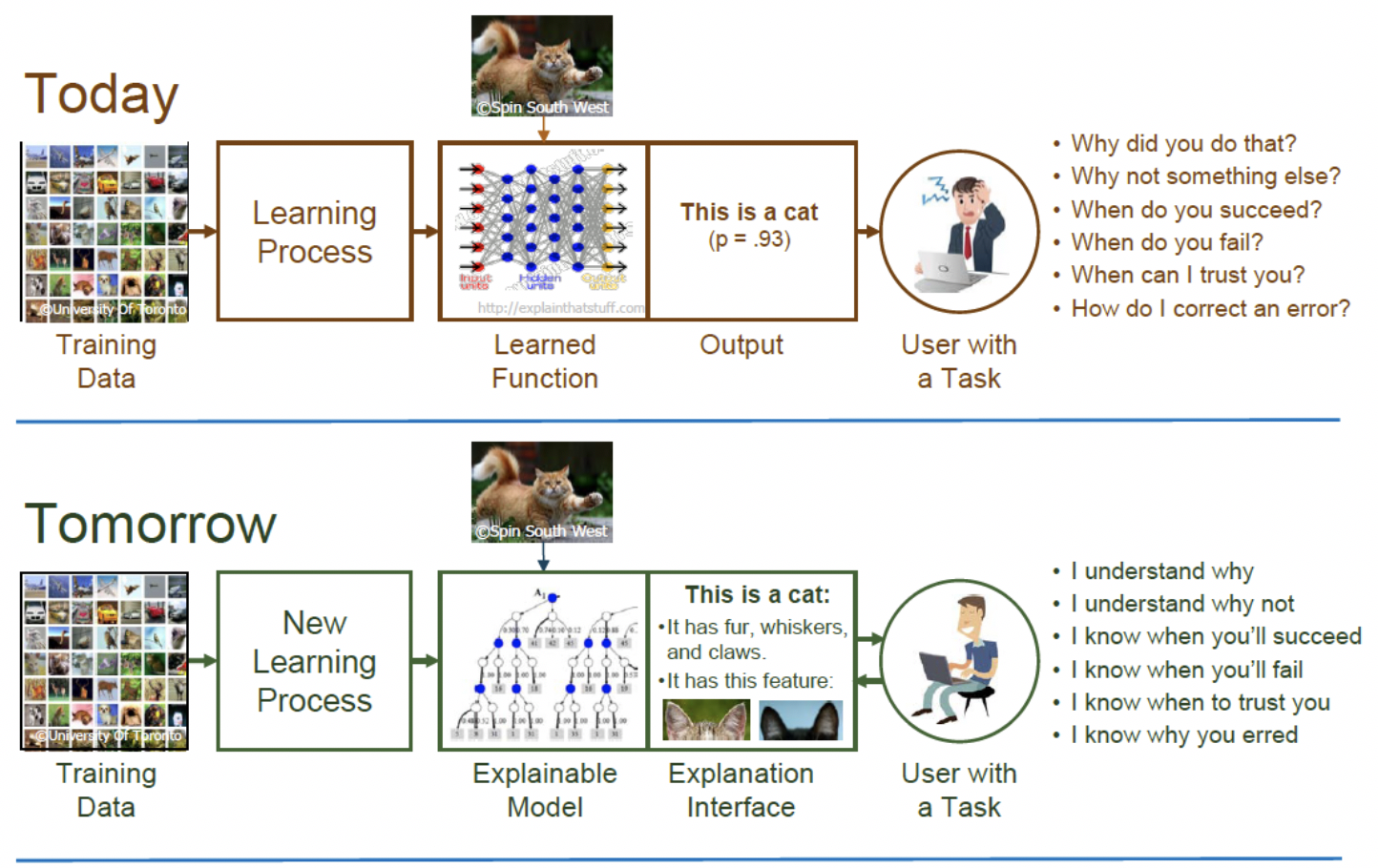
图4 XAI提供可解释性
举网络安全场景的例子来说,当前许多威胁检测引擎,如Webshell检测、SQL注入检测等,使用基于机器学习或者深度学习的方法,能够取得较高的准确性。这其中部分模型不具备提供可解释的能力,即黑盒模型。无论是用户,还是研究员,只能得到告警而不知道告警为何而来,特别是当模型产出大量告警(误报)时,黑盒机器学习引擎的鲁棒性、可用性大幅降低。这逼迫我们继续依赖安全研究员的规则引擎,耗费大量人力物力。与之相对的,通过可解释的模型和包含解释说明的人机交互接口,AI系统不仅仅告诉我们检测结果,还可以回答“why”类问题。XAI系统不仅告诉我们有威胁,还能提供威胁的“上下文”:比如提供恶意流量中,哪些载荷字节,或者流量的哪些统计特征导致模型触发恶意告警的判断。这些辅助的解释性说明,让用户感受到对系统的掌控,即通过提供系统决策的透明性,用户和系统之间才能够建立信任。
XAI提供的可解释性,能够从多个方面构建人与机器的信任:
- 向使用者证明结果是稳定的、准确的、道德的、无偏见的、合规的,从而提供决策的支持以AI自身安全性的可视性
- 向开发者提供模型改进、调试的基础信息
- 向研究者提供机器洞见,展现被人忽视、难于发现的潜在规律
XAI技术不仅仅是技术需求、业务需求,也已经成为法律合规需求。例如,《通用数据保护条例》GDPR包含了关于数据自动化处理过程中,须提供决策解释的相关内容;同时,XAI是国家AI战略发展需求,2017年中国国务院印发的《新一代人工智能发展规划》指出“……高级机器学习理论重点突破自适应学习、自主学习等理论方法,实现具备高可解释性、强泛化能力的人工智能……”。
二、 XAI实现概览
XAI技术没有明确的范畴,根据前文定义,能够提供人类可理解的决策说明的AI系统可称为可解释的AI。在此,我们不将AI技术局限在机器学习或深度学习技术。基于图以及语义网络为基础的知识图谱,具备自然的可解释性,在此也划入了XAI技术的行列。
1. XAI技术分类简介
总体而言,XAI技术研究可覆盖模型可解释性、人机交互应用以及可解释性的心理学研究等多个方面,本文重点关注模型可解释性的研究。模型可解释性的研究可根据解释的局部性(具体样本的局部解释还是整个模型的全局解释)、解释性实现的阶段(建模的前、中、后)、模型依赖性(模型相关、模型无关)等不同维度进行划分。以下是根据可解释性实现的阶段对XAI技术的一个粗略划分,列举的方法覆盖了可解释性模型实现的主要类型。其中,建模前的可解释性能力主要是针对数据层面的分析技术,可以通过基本的统计数据分析方法及可视化方法,得出关于待分析样本的初步结论,进而支持人类决策,如通过阈值检测异常,通过画像技术观测性质、趋势等等。建模前的数据分析能够避免构建复杂的模型,或者辅助模型的构建。此类方法应用涉及范围广,但几乎不涉及更自动化的AI系统。本文重点关注可解释的模型(explainable modelling)和建模后的可解释性(post-modelling explainability)的相关研究,针对每种方法举典型技术来说明具体实现及应用。
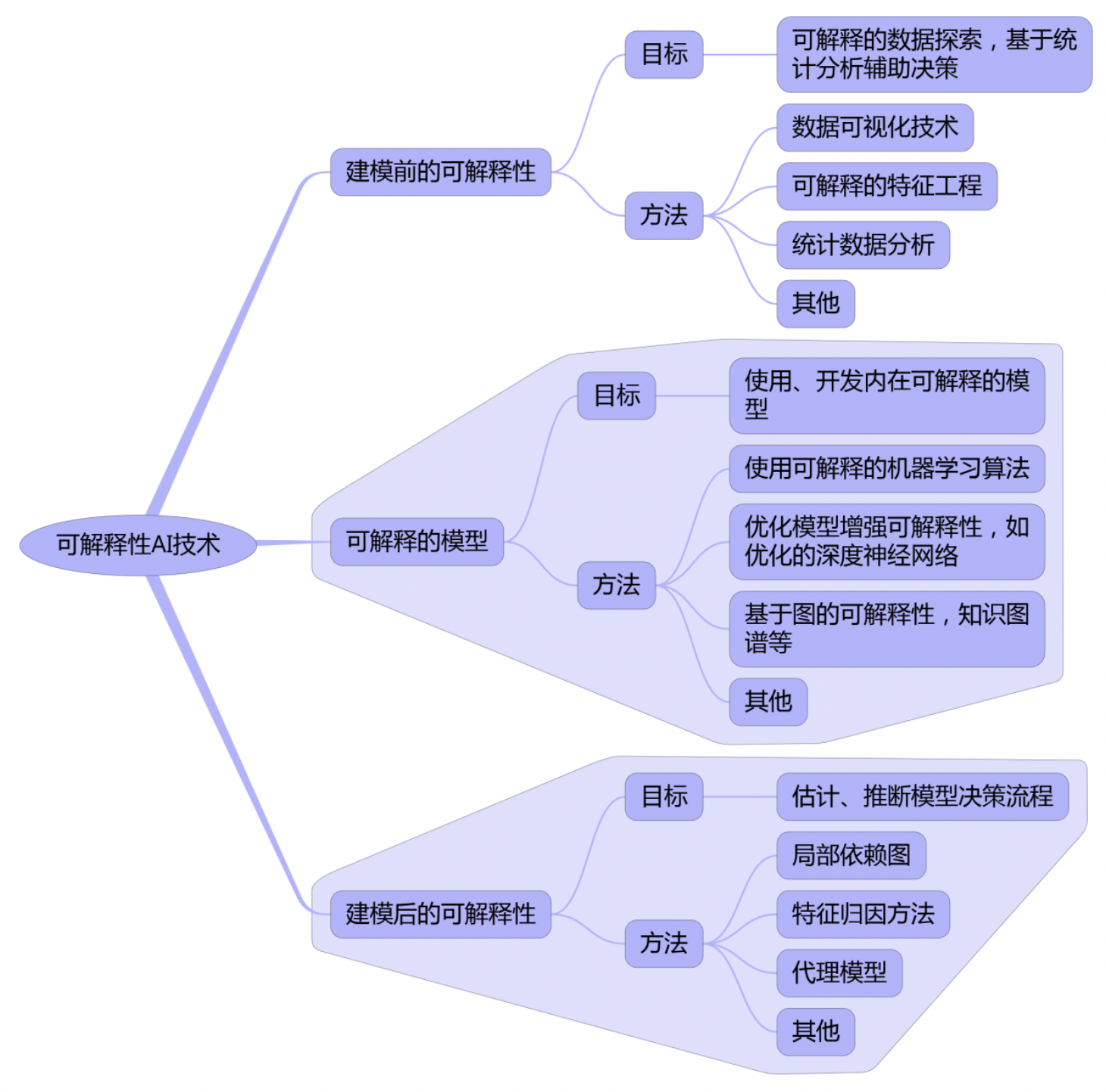
图5 基于可解释性构建阶段的XAI技术分类
1.1 可解释的模型
1.1.1 使用内在可解释的机器学习算法
以下表格概括了具备内在可解释性的机器学习算法[4]。这些“朴素”算法及其优化、变种方法,在许多实际场景下有大规模的应用。通过简洁的统计特性和可视化方法,即使最简单的机器学习方法也能够辅助人发现数据的基本规律并完成决策。例如线性回归(Linear regression),模型学习到的参数,能够直观的反映其决策原理:参与与特征值的加权值直接产生结果。KNN模型虽然非线性也不具备单调性,但其决策结果产生依赖最相似的K个实例,而这些实例是可被人理解的。与之相对的,多数复杂模型不具备这种内在可解释性,即输入与输出之间的学习过程高度分线性、不单调,参数之间相互影响,远超过人类可直接理解的范畴。
当然,显而易见的是这些算法一般情况下难以胜任复杂的数据分析任务,只使用此类算法将限制可用场景。
| 算法
Algorithm |
线性
Linear |
单调性
Monotone |
特征交互
Interaction |
面向任务
Task |
| Linear regression | Yes | Yes | No | regr(回归) |
| Logistic regression | No | Yes | No | class(分类) |
| Decision trees | No | Some | Yes | class,regr |
| RuleFit | Yes | No | Yes | class,regr |
| Naive Bayes | No | Yes | No | class |
| k-nearest neighbors | No | No | No | class,regr |
1.1.2 优化的深度模型增强可解释性
针对深度学习可解释性的研究不同于一般的深度神经网络的层次化可视化方法。可视化“忠实”输出网络学习的知识,而可解释性需要考虑学习到的知识是否是人类更容易理解的。举例来说,CNN模型在图像分析应用中很大的优势,然而传统的模型往往被看做黑盒模型,为了使模型具备可解释性,CVPR 2017上研究者提出了Interpretable CNN[5]。通过添加损失函数,保证每个高层过滤器必须编码一个明显的对象局部(object part),并且该对象局部包含在一个独立的对象类中;同时该过滤器只能被某对象的一个局部激活,从而保证了过滤器与对象局部的对应关系。该方法在保持较高分类性能的基础上,能够在使用与传统CNN相同的训练数据的情况下,让高层卷积的过滤器在训练过程中“记住”图像的局部特征,从而能帮助模型使用者理解该CNN学习到的内部逻辑。下图展示了Interpretable CNN与传统CNN所学习到的内在模式的显著不同:Interpretable CNN记住了更有可解释意义的图片内部结构。

图6 Interpretable CNN与传统CNN对比
嵌入可解释性的深度学习在推荐系统中也有不少研究。例如微软研究员通过Attentive Multi-View Learning对深度网络参数进行优化,以提供层次化的推荐可解释性[6]。
1.1.3 基于图的可解释性
图结构及算法能够更自然的表达数据的关联关系,是具备可解释性的模型类别。知识图谱可定义为基于语义网络的知识库,通过点、边及其类型的本体化、语义化定义,规范某应用领域内的信息表达和知识结构。大部分XAI研究关注可解释的机器学习模型,在XAI技术分类中往往不包含图、知识图谱及图算法技术。不过,AI技术不止通过机器学习、深度学习技术实现,知识图谱及图算法通过对关联世界的自然表达方法,同样具备内在可解释性,也是AI的重要组成部分。因此,本文将知识图谱划分到XAI可解释的模型类别下。同时,本文重点关注的是知识图谱及图算法在安全场景中的应用,而非知识图谱相关的NLP等技术,以展示图的原生可解释性。
本文重点关注网络信息安全场景下的图及图算法。多源安全日志数据构建的多种类型的图结构也可以具备语义结构,因此也可归类为知识图谱。美国的MITRE公司研究者提出将任务依赖、网络架构、网络暴露状况以及网络威胁统一组织成多层的知识图谱[7],通过自定义的图查询语言CyQL,能够实现诸如威胁狩猎、任务可视化、时序图分析等任务。
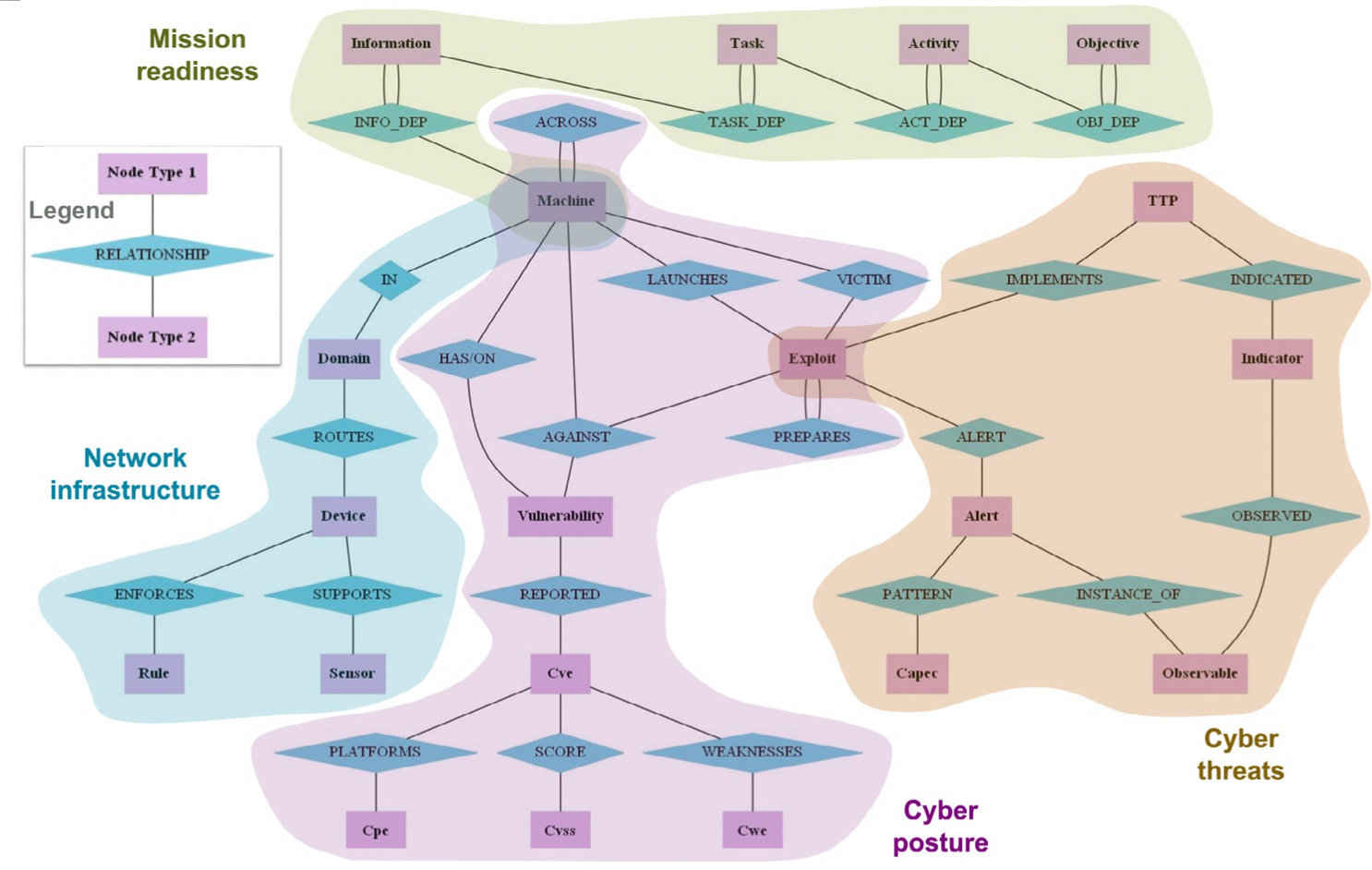
图7 MITRE CyGraph本体设计
ICCS 2018会议上IBM研究员提出威胁情报计算(TIC,Threat Intelligence Computing)的概念[8],通过构建时序图结构,实现敏捷的网络推理和威胁狩猎。在TIC框架下,所有的安全日志、告警日志以及流量日志都存储为统一的时序图,进而通过攻击子图描述威胁或者攻击,威胁发现的问题被转化成子图计算问题。

图8 Threat Intelligence Computing模型设计及示例
NDSS 2019会议上,研究者提出了NoDoze[9],通过在溯源图(Provenance Graph)上定义、查找低频事件路径,有效解决告警的溯源问题,降低误报事件的影响。其核心思路是通过低频事件的挖掘,将“异常”进程行为与实际的告警进行图上的关联。下图展示了通过在溯源图中评估告警依赖路径的异常程度,能够有效区分真正的攻击事件和运维调查导致的误报,并返回完整的事件上下文,有效解释了真实的攻击路径。
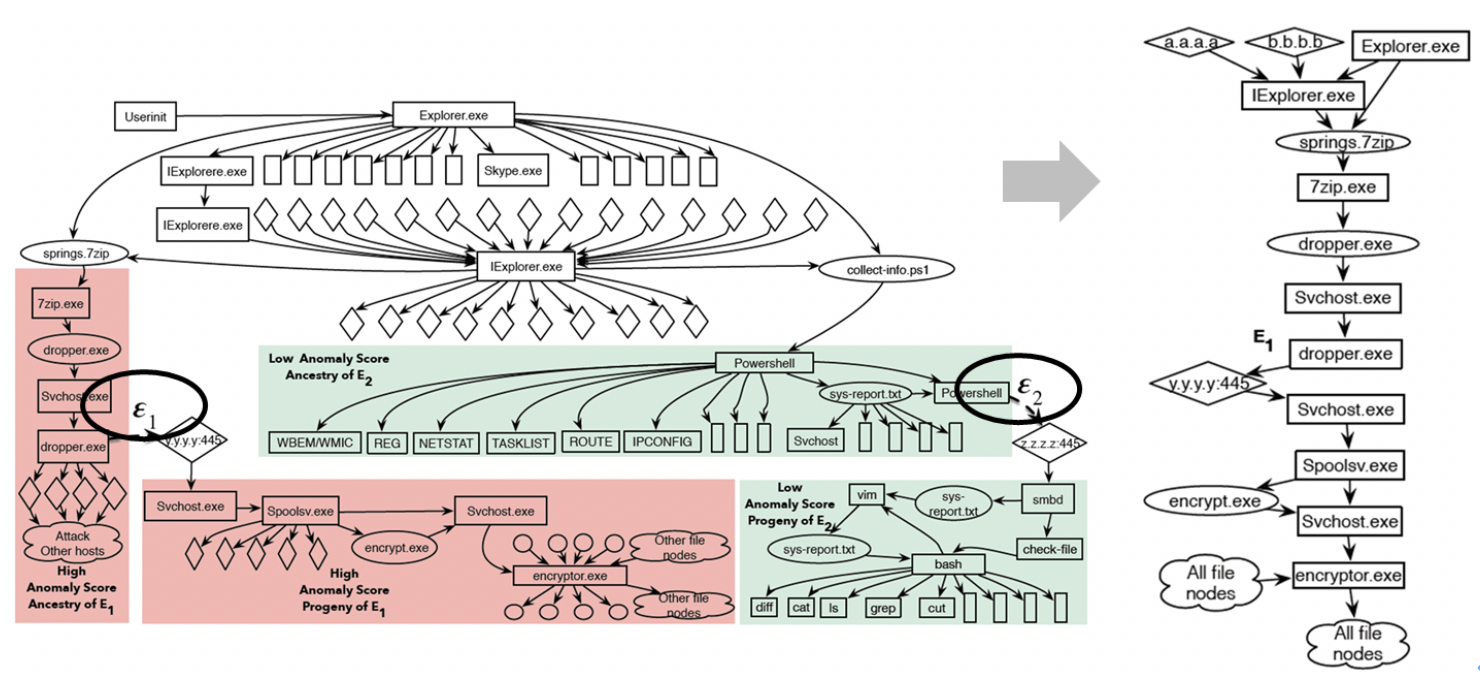
图9 NoDoze实现威胁溯源
IEEE S&P 2019研究者提出了Holmes系统[10]。该系统同样基于终端侧的溯源图进行分析,采用了层次聚合的策略。与NoDoze不同的是,该系统采用了基于攻击链视角的分析思路。将底层进程行为归一化为TTP (Tactics, Techniques, and Procedures),从全局视角语义化了攻击行为,有效将时序上松散的可疑进程事件关联,能够有效提取APT攻击行为及意图。
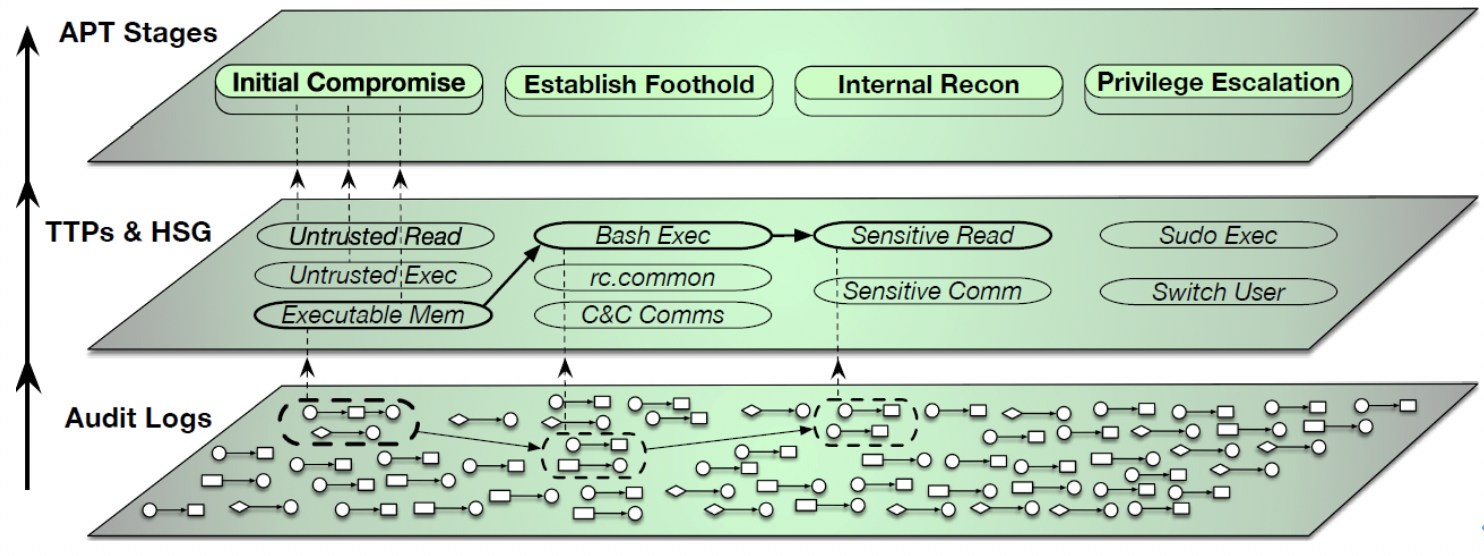
图10 Holmes层次化APT技术战术聚合
以上简要分析了图或者知识图谱在安全场景下的典型应用。依赖于语义图的内在可解释性,图结构及图算法广泛的应用在诸多场景下,如推荐系统、欺诈检测、网络安全等,为自然存在的大规模数据关系的挖掘提供了系统性的可解释的方法,成为XAI技术的重要组成部分。此外,针对图算法的研究,如基于深度学习的图嵌入、图遍历、图上异常检测等,增强其可解释性也是重要的研究方向。
1.2 建模后的可解释性
建模后(post-hoc)的可解释性研究是XAI研究的重点,该类研究一般将包含机器学习模型的AI系统看做黑盒,从而能够保证解释模型与方法和原AI系统之间是解耦的,保持解释层的模型无关性。以下介绍几种经典的模型无关的可解释性构建方法。
1.2.1 部分依赖图(Partial Dependence Plot)
针对复杂模型,部分依赖绘图Partial Dependence Plot (PDP)[11]计算中可以考虑所有样本点,在保持样本其他特征原始值不变的条件下,计算某(一般是1~2个)特征所有可能值情况下的模型预测均值,从而全局化的描述该特征对模型预测的边际影响,能够可视化特征的重要性,描述特征与目标结果之间的关系。PDP可视化结果非常的直观,并且全局性的分析了特征对模型输出的影响,但是可解释性的可信度很大程度上依赖特征之间的相关性:PDP没有考虑特征之间的相关性,在某特征值遍历求均值的过程中不可避免的引入一些不可能存在的点,导致最终结果出现偏差。
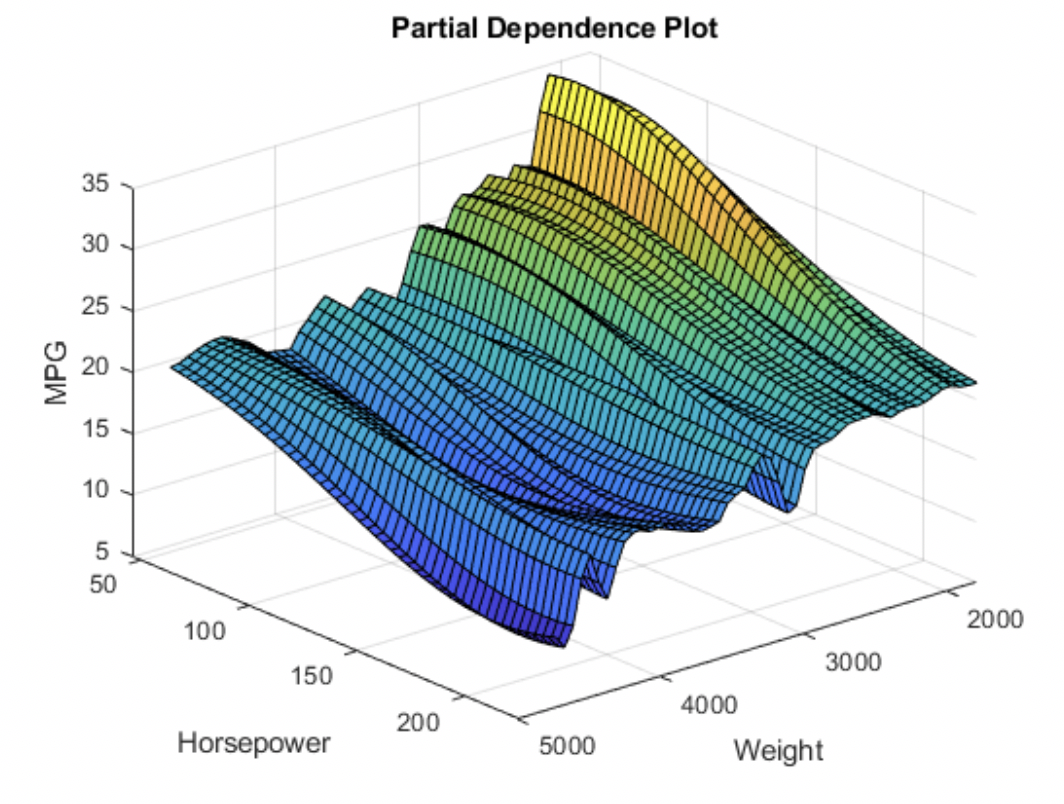
图11 PDP的可视化效果[12]
1.2.2 特征归因
特征归因(Feature Attribution),是分析模型决策依赖于指定特征程度的一种度量。该方法同样符合人类直觉:特征重要性越高,则模型预测中越“依赖”该特征,从而能够直观发现特征对结果的影响。
值得注意的一个问题是,许多Boosting方法及框架,如XGBoost、LightGBM以及Catboost等能够提供模型的Feature Importance参数。此类模型构建过程中获得的特征指数,能够反映模型在训练数据上对特征的依赖,有效辅助特征工程任务,可归属于建模前的可解释性部分,以辅助模型的构建;但此类Feature Importance不能够回答模型如何在任务中做出决策的问题:这些方法获取的特征重要性完全依赖于训练集,而训练集很难真实反映实际环境下的数据分布。
当然,说明哪些特征对模型的预测结果起到关键作用还不足以保证“可解释”,要么通过可解释层屏蔽模型的原始输入,呈现给人可解释的内容;否则原模型选取的特征本身的可解释性就显得尤为重要了。比如,文本中哪些单词或者词语决定了最终文本主题的判断,图像的哪一个局部决定了图像的分类,这些都是具有可解释性的;而类似高维矩阵的某些位置、图像的离散的像素值,则难以被人类理解。以下介绍几种经典子方法。
A.LIME
Local Interpretable Model-agnostic Explanations (LIME) 是2016年KDD会议上学者提出的一种可解释方法[13]。Local指出该方法是一种局部的可解释方法,即用于解释具体样本的预测原由。Model-agnostic表示了该方法是模型无关的,将任何机器学习模型看做黑盒。算法直观、效果明显,LIME目前在各类场景中应用较广泛。
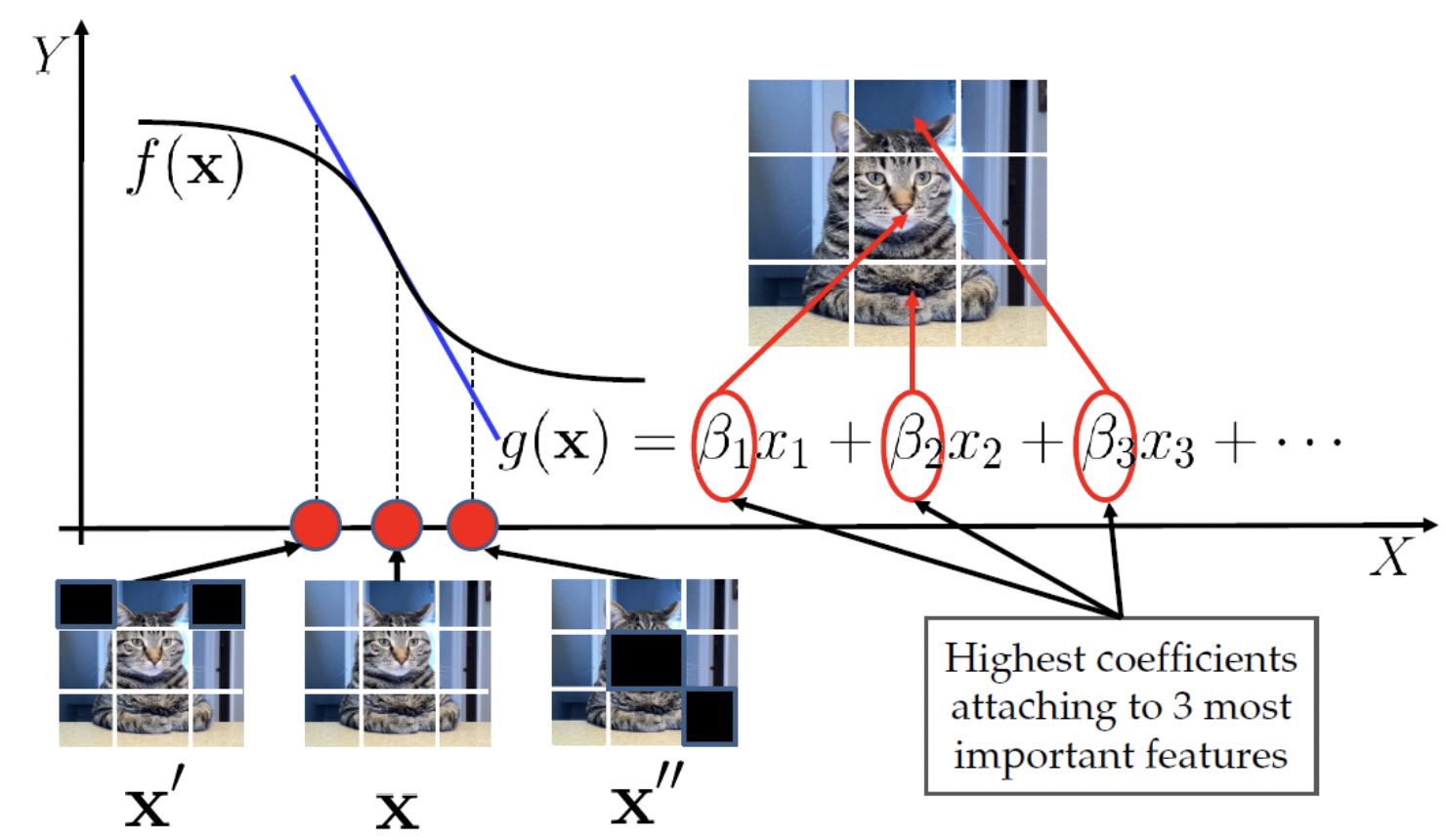
图12 LIME基本原理示意[14]
LIME的核心思路很简单,使用线性模型(或其他可解释的朴素模型)g(x)作为待解释黑盒模型f(x)的局部代理模型。获取某样本的可解释结果的工作流程可以直观上描述为:
- 首先将样本以人类可理解的方式表示,例如将文本划分为单词、将图像划分为超像素块(连续的像素组成的块);
- 在该样本表示的周围进行采样,例如去掉文本单词列表中的某些单词、将图像的某些超像素块屏蔽;将采样生成的新样本集合(可解释表示样本集)输入局部代理;
- 局部代理将输入的可解释表示样本集中的每个新样本转换为原黑盒模型可识别的输入矩阵,并获取这些新样本的预测标签,最终以可解释表示样本集及其预测标签集为输入,以输入样本与待解释样本的相似度为度量,以加权的方式训练生成线性模型,从而评估可解释表示样本集中每个样本(代表原始样本的某一部分)对该样本预测的影响。

图13 LIME预测解释效果
上图展示了LIME对图像的可解释能力,右侧三个子图分别标明了谷歌的Inception network模型根据图像的哪一部分将该图预测为电子吉他、木吉他或者拉布拉多犬(从左到右,类别预测概率依次降低)。虽然该模型的预测结果并不准确(我们更希望拉布拉多犬标签排在第一位),但是LIME解释了该模型判断的依据,增强了人与机器系统的信任,也为模型的优化提供了提示。
B.LEMNA
类似LIME的工作,LEMNA针对基于深度学习的安全应用,如PDF恶意软件识别、二进制逆向等进行了优化[14]。相较于LIME做出的模型的局部是线性的强假设,LEMNA方案是可以处理局部非线性的代理,并且将特征之间的依赖性考虑在内。LEMNA可用于二进制逆向中场景中函数起始位置检测模型的解释。如下图所示,RNN模型预测0x83为函数的实际起始位置,并给出了置信度0.99。而LEMNA通过对该样本进行代理分析,给出了模型判断0x83为起始位置的依据:红色、橙色、金黄色和黄色,分别表示了关联字节特征对最终预测的贡献程度,颜色越深重要性越高。
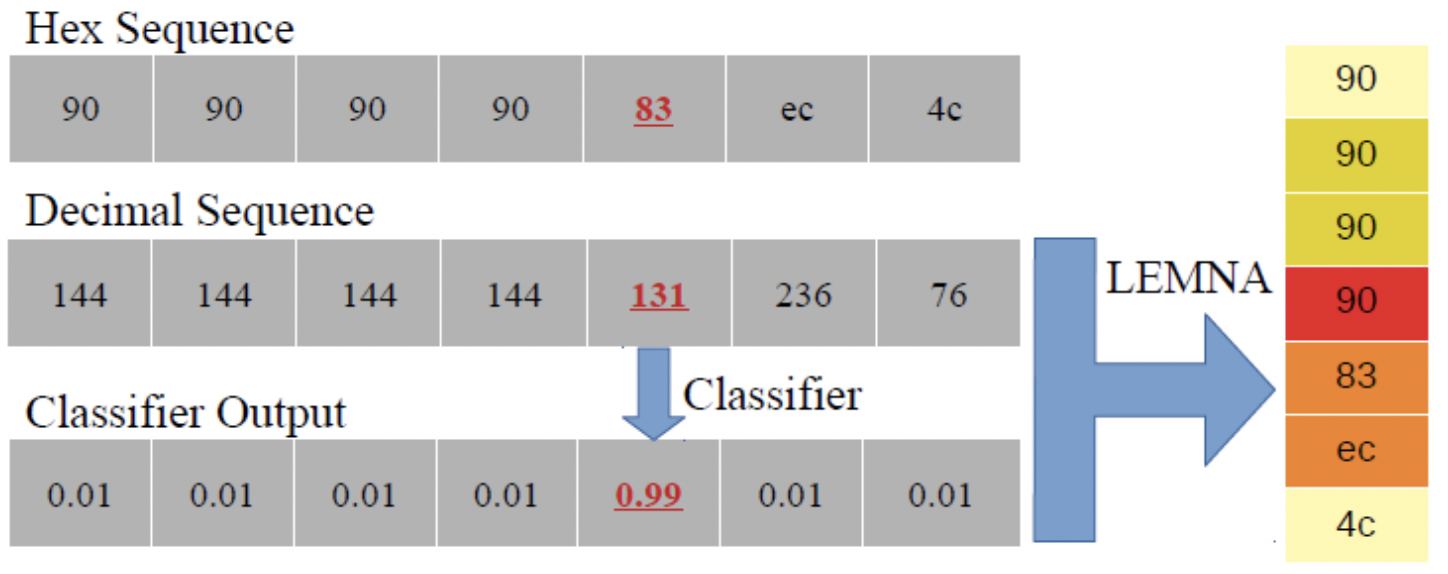
图14 LEMNA解释RNN模型预测结果
C.Backward Propagation
ICML2017上研究者提出的DeepLift[15],为避免类似LIME等方法计算中的正向传播的效率和饱和问题,通过反向传播的方法,提供一种特征对深度而学习模型预测输出的重要性度量计算方法。该方法的一个局限性是需要用户提供指定的参照(Reference),而该参照样本的选择目前没有系统的选择方法。而不同的参照对最终的特征重要性计算影响非常大。
除了DeepLift,还有多种面向深度学习框架的可解释技术实现方案。下图展示了包括DeepLift在内的多种基于梯度计算的特征归因方法,着色的像素点即展示了特征像素的归因图谱(attribution maps)。
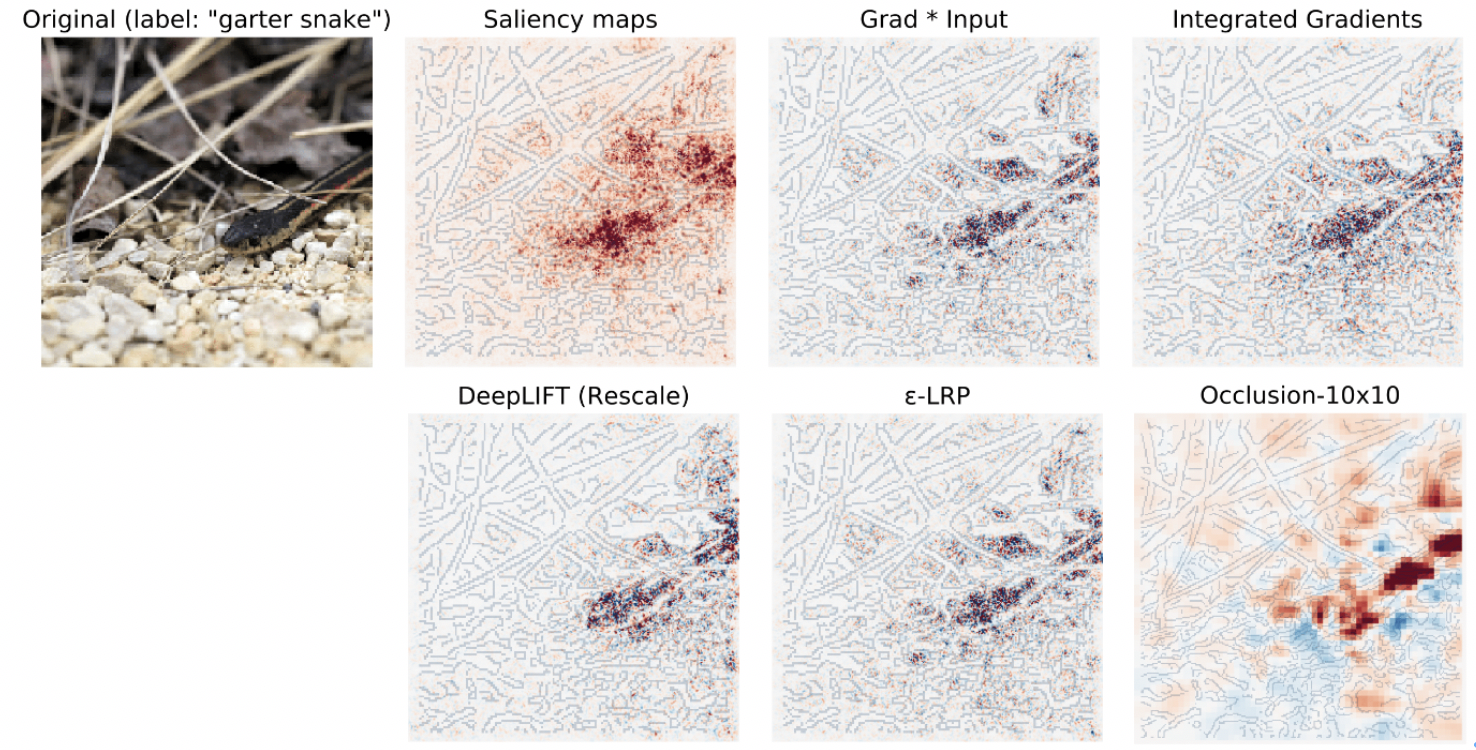
图15 多种基于梯度计算的深度可解释方法[16]
D.Shapley Values
Shapley值方法是博弈论中解决合作对策问题的一种方法,能够根据一个利益集团中各成员对联盟所得的贡献程度来进行集团的利益分配。将Shapley值方法应用到模型解释性的特征重要性分析中,就是将模型预测类比为多个特征成员的合作问题,将最终预测结果类比合作中的总收益,而特征的贡献程度将决定其最终分配到的收益——重要性评估值。有多种基于Shapley Values估计的方法,其中SHAP (SHapley Additive exPlanations)是一项NIPS 2017上提出的研究[17]。该研究提出的SHAP方法也是一种局部可解释性方法,与前述的局部模型代理(LIME、LEMNA等)相比,该方法具有数学理论的严格证明,理论上保证其特征重要性结果的与人的直觉的跟具一致性。SHAP架构提供的特征重要性解释如下所示,该结果显示了将模型预测从基准值(训练数据集中的平均模型输出)推进到待解释样本的模型预测,每个特征的贡献,将预测值推高的特征用红色表示,将预测值推低的特征用蓝色表示。SHAP方法对传统Shapley Values的计算进行了优化,但有研究表明该算法计算效率仍然较低。

图16 SHAP特征贡献可视化图
1.2.3 全局代理模型(Global Surrogate Models)
不同于LIME等局部代理模型,全局代理模型能够提供整个模型的可解释性,而不仅仅是针对某个或某些个样本实例的解释。一种朴素的思路是,将原始数据集中的实际标签替换为黑盒模型的预测标签,生成新的样本集,在该样本集上,训练一个内在可解释的模型。显然该方法能够直观的解释复杂模型的决策流程,但是不可避免的丢失模型的预测性能,因为代理模型直接学习的是关于黑盒模型的知识,而不是原始数据本身的知识。
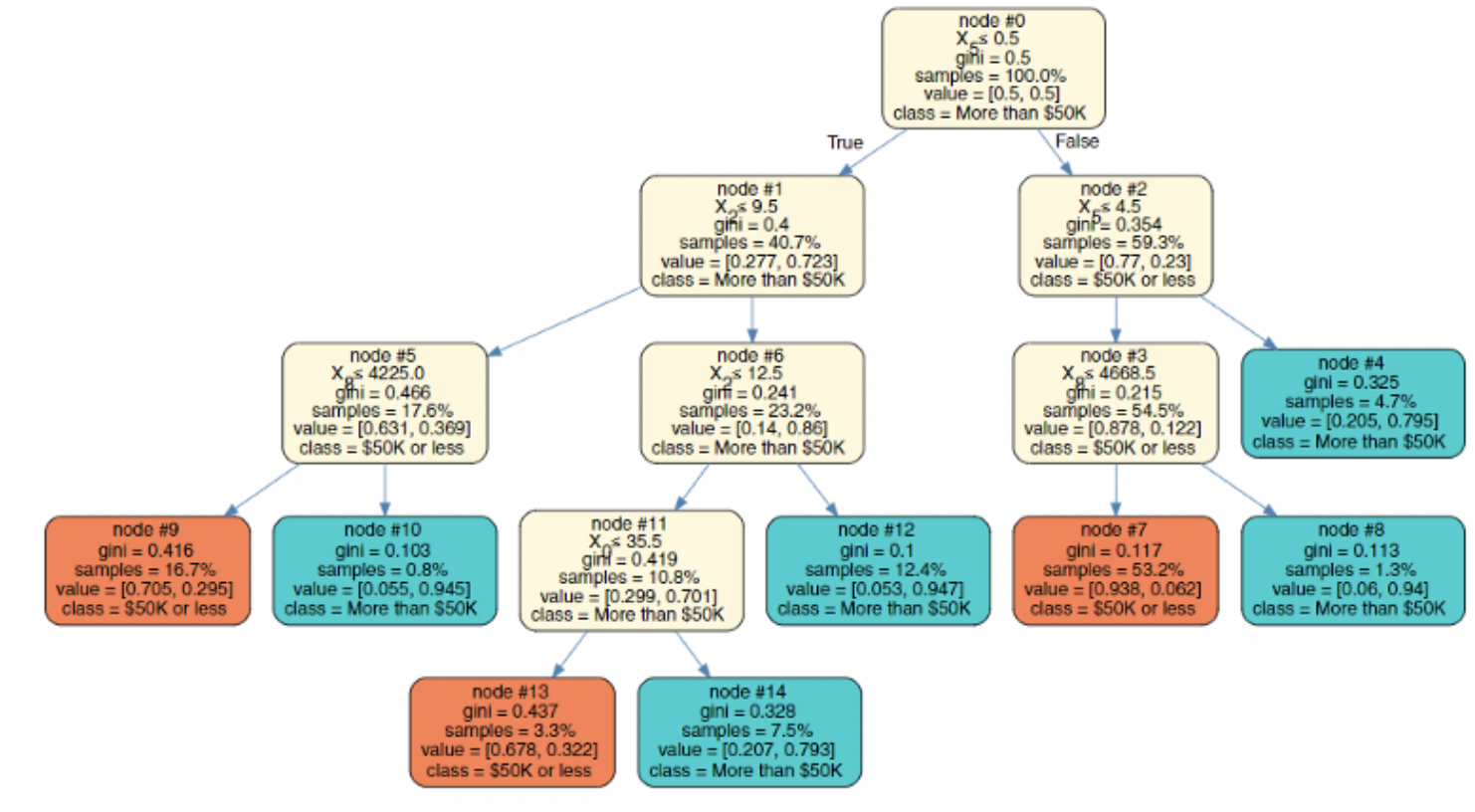
图17 使用决策树作为全局解释代理[18]
代理模型的核心思想可以概括为:使用简单可解释的模型模拟复杂模型的行为,即学习一种模型的可解释压缩表示。深度学习中模型蒸馏(Distilling)等压缩技术,也是生成代理模型的可用方法,关键是如何限制模型架构,保证最终代理模型的可解释性。
2. 可解释性技术分类维度
以上,我们从可解释性引入的阶段这一维度进行了划分,初步介绍了多种XAI领域中的可解释性的技术实现。关于机器学习模型可解释性以及其他XAI技术的研究虽然还处在研究的早期阶段,但研究的热度持续上升,相关研究众多,本文很难覆盖所有技术点。下表从解释阶段、解释域、模型相关性三个维度对本文涉及的主要可解释技术的特性进行了小结,以区分不同技术在不同场景需求下的可用性。
| 技术 | 解释阶段/方式 | 解释域 | 模型相关性 | |||
| 原生可解释
(Intrinstic) |
建模后解释
(Post-hoc) |
全局解释性
(Global) |
局部解释性
(Local) |
模型相关
(Model-specific) |
模型无关
(Model-agnostic) |
|
| Decision trees | √ | √ | √ | |||
| Graph-based | √ | √ | √ | √ | ||
| LIME | √ | √ | √ | |||
| SHAP | √ | √ | √ | √ | ||
| DeepLift | √ | √ | √ | |||
| Global surrogate models | √ | √ | √ | √ | ||
| Partial Dependence Plot(PDP) | √ | √ | √ | √ | ||
| Model distillation | √ | √ | √ | |||
总体而言,建模后(Post-hoc)及模型无关(Model-agnostic)的可解释性技术在不同的应用场景下适应性较强,可作为独立的可解释层构建在现有的AI系统之上,无论是在研究中还是实际使用场景使用中都颇受欢迎;全局可解释性能够反映模型的整体运行机制,例如分析对整个模型来说,最关键的特征是什么,但是想要回答某个具体决策结果、预测结果的背后逻辑,还是需要依赖局部可解释性方法;作为主流的AI实现方案,针对深度学习技术的深度可解释性的同样受到广泛的关注;基于图及图算法的可解释应用在诸多领域都有应用落地,同样是XAI技术的重要一环。
三、 XAI与可信任安全智能
AI在许多领域发挥了实现高度自动化、大规模解放人力的功能,但在军事、金融、网安、医疗、法律等多个需要高质量决策的场景下,还难以放心的大规模、深度应用AI。如今,探讨如何将人工智能与人类智能有机的结合,形成优势互补的良性闭环,已成为各界的共识。传统高性能、黑盒智能系统,已经难以满足“人-机”融合的需求。当人们意识到不能完全依赖AI独立、自动化的制定决策、完成行动时,可信任的智能系统就成为合作共赢的关键。信任的建立,依赖于AI系统本身的安全性、AI系统提供的不可取代的产能以及AI系统的透明程度、可理解程度等多个方面,而XAI所提供的可解释性正是这些信任基础的核心支撑技术之一。
就安全场景而言,流量分析、用户实体行为分析、样本分析、威胁关联、自动化响应等等安全能力逐渐集成更高级的机器学习算法、图算法,但要实现高度智能化、自动化的安全系统的成熟,我们还有很长的路要走。为现有的和未来的AI技术增强可解释性,建立可信任安全智能,是实现安全智能大规模应用落地的必由之路。
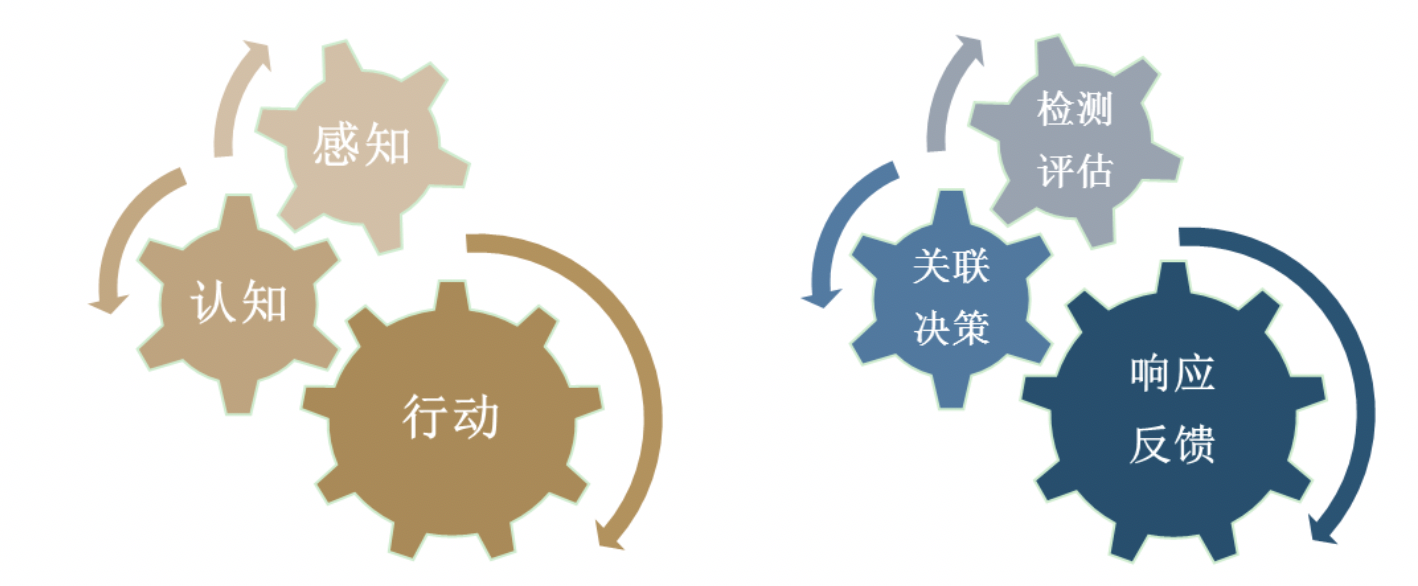
图18 AI技术与安全能力的层次划分
构建可信任的安全智能,核心问题不是研究XAI技术本身,而是如何将XAI技术及架构,融合到安全场景中,形成机器效率与专家经验融合的闭环,以辅助提升AI在安全研究、安全运维、攻防实战中的可用性。如果我们将人工智能的能力划分为感知-认知-行动三个层次,那么对应到安全能力,则可粗略划分成检测/评估-关联/决策-响应/反馈三个层次和阶段。在检测/评估层面,安全设备及系统完成相对独立的威胁检测、风险评估;在关联/决策层面,多源异构数据,包括机器检测、威胁情报与专家经验的全面融合关联,进而形成可行动的决策输出;在响应/反馈层面,融合的决策被执行,威胁事件、情报信息被处置处理,并获取环境或人的反馈。以上安全能力的划分概念性的描述了安全能力自动化建设的基本生命周期。为保证以上动力齿轮的持续、高效运转,XAI技术需要嵌入每个关键环节,提供可解释性接口与界面,打造可信任安全智能的基础。下表列举了几个典型的AI-安全能力及对应可补充的XAI技术。
| 安全能力阶段 | 技术点 | 核心解释能力补充 |
| 检测/评估 | 流量威胁检测 | 模型无关的解释性、深度可解释性 |
| 检测/评估 | 恶意样本分析 | 模型无关的解释性、深度可解释性 |
| 检测/评估 | 误报对抗 | 建模前数据分析、模型无关的解释性 |
| 检测/评估 | AI对抗安全 | 深度可解释性 |
| 关联/决策 | 威胁关联及溯源 | 基于图的可解释性 |
| 关联/决策 | 攻击团伙分析 | 建模前数据分析、基于图的可解释性、深度可解释性 |
| 关联/决策 | 自动化指纹提取 | 模型无关的解释性 |
| 关联/决策 | 智能自动化决策 | 基于图的可解释性、深度可解释性 |
| 响应/反馈 | 自动化响应 | 模型无关的解释性、深度可解释性、人机交互界面 |
| 响应/反馈 | 行动推荐 | 基于图的可解释性、深度可解释性 |
以上列举的多种安全应用场景,走向高度智能化、自动化的道路还很漫长。XAI作为AI系统落地的必要条件之一,无论是构建安全的AI还是AI辅助的安全自动化的过程中,可解释性都应该成为透明的、可信任的机器智能安全的标配,融合到技术设计、实现的框架内。
四、 总结
为AI系统提供可解释性,是建立人对机器智能信任的关键,也是构建人-机智能融合闭环的重要工作。在网络信息安全领域,我们也愈发需要可信任的安全智能,以实现高度自动化、智能化的系统,来延伸安全能力的触角。XAI技术尚在研究和应用的早期,针对可解释性的量化评估、高可解释性技术、高可用人机交互模式、针对特定场景的可解释性系统等角度的研究有待突破。但可解释性的强化将逐渐推动人工智能系统迈向通用智能,并促进关键决策领域的自动化技术突破。XAI+Security能够如何促进技术迭代、革新行业面貌,让我们拭目以待。
参考文献
- Adadi A , Berrada M . Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI)[J]. IEEE Access, 2018:1-1.
- https://towardsdatascience.com/human-interpretable-machine-learning-part-1-the-need-and-importance-of-model-interpretation-2ed758f5f476
- Gunning D. Explainable artificial intelligence (xai)[J]. Defense Advanced Research Projects Agency (DARPA), 2017.
- https://christophm.github.io/interpretable-ml-book/
- Zhang Q, Nian Wu Y, Zhu S-C. Interpretable convolutional neural networks[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 8827-8836.
- Gao J, Wang X, Wang Y, et al. Explainable Recommendation Through Attentive Multi-View Learning[C]. AAAI, 2019.
- Noel S, Harley E, Tam K H, et al. CyGraph: Graph-Based Analytics and Visualization for Cybersecurity. Cognitive Computing: Theory and Applications Elsevier , 2016.
- Shu X, Araujo F, Schales D L, et al. Threat Intelligence Computing[C]. Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, 2018: 1883-1898.
- Hassan W U, Guo S, Li D, et al. NoDoze: Combatting Threat Alert Fatigue with Automated Provenance Triage[C]. NDSS, 2019.
- Milajerdi S M, Gjomemo R, Eshete B, et al. HOLMES: real-time APT detection through correlation of suspicious information flows[J]. arXiv preprint arXiv:1810.01594, 2018.
- Adadi A, Berrada M. Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI)[J]. IEEE Access, 2018, 6: 52138-52160.
- https://ww2.mathworks.cn/help/stats/regressiontree.plotpartialdependence.html
- Ribeiro M T, Singh S, Guestrin C. Why should i trust you?: Explaining the predictions of any classifier[C]. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 2016: 1135-1144.
- Guo W, Mu D, Xu J, et al. Lemna: Explaining deep learning based security applications[C]. Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, 2018: 364-379.
- Shrikumar A, Greenside P, Kundaje A. Learning important features through propagating activation differences[C]. Proceedings of the 34th International Conference on Machine Learning-Volume 70, 2017: 3145-3153.
- https://github.com/marcoancona/DeepExplain
- Lundberg S M, Lee S-I. A unified approach to interpreting model predictions[C]. Advances in Neural Information Processing Systems, 2017: 4765-4774.
- https://towardsdatascience.com/explainable-artificial-intelligence-part-2-model-interpretation-strategies-75d4afa6b739