致谢
在此特别感谢 ESM 技术部的杨钦同学在攻击数据模拟采集方面给予的支持,使得研究和实验工作顺利开展。
一、前言
webshell是黑客进行网站攻击的一种恶意脚本,识别出webshell文件或通信流量可以有效地阻止黑客进一步的攻击行为。目前webshell的检测方法主要分为三大类:静态检测、动态检测和日志检测[1]。静态检测通过分析webshell文件并提取其编写规则来检测webshell文件,是目前最为常用的方法,国内外的webshell识别软件如卡巴斯基、D盾、安全狗、河马webshell等都是采用静态检测的方法,但由于webshell会不断地演化从而绕过检测[2],所以静态检测最大的问题在于无法对抗混淆、加密的webshell以及识别未知的webshell[3];动态检测通过监控代码中的敏感函数执行情况来检测是否存在webshell文件[4],但由于涉及到扩展、Hook技术,性能损耗以及兼容性都存在很大的问题,所以难以大规模推广应用;日志检测主要通过webshell的通信行为做判断[5],相对于以上两种检测方法来说,不仅检测效果好也不存在兼容性问题。
无论是静态检测还是动态检测都是针对webshell文件的检测,最终也都是对特定字符串的检测,难免涉及到字符串混淆、加密等造成漏报或误报,而日志检测属于流量检测方法的一种,所以本文主要基于流量来实现webshell的检测。目前基于流量的检测仍然面临一些问题。一方面,现存的一些webshell连接工具,比如冰蝎[6]、哥斯拉[7]、蚁剑[8]等,都使用了混淆或加密机制,通过加密通信流量的方式来绕过传统安全设备的检测,所以字符串匹配的检测方法[9]已经很难适用于加密的场景;另一方面,随着人们网络安全意识的提升,对于数据保护的意识也逐渐增强,越来越多的流量被加密,网站流量中HTTPS的占比逐年攀升,但是HTTPS中的webshell检测仍然没有较好的解决方案。
在《【冰蝎全系列有效】针对HTTPS加密流量的webshell检测研究》一文中,我们针对HTTPS中的webshell特别是冰蝎的检测进行了探索,本文进一步针对常见的几种加密型webshell进行研究,分别基于HTTP和HTTPS流量,通过提取内容特征和统计特征的方式,对webshell连接工具的通信流量进行识别并提出了可行的检测方案。
二、HTTP中的加密webshell检测
比起正常访问网站的流量,HTTP中加密型webshell客户端的通信流量会有一些不同,比如webshell的特征指数会比较大,信息熵也相对较大,post_data的长度相对长一些但重合指数较低,也会对局部字符串进行base64编码等,根据这些区别,我们就可以提取对应的特征,从HTTP中检测出加密型webshell的通信流量。
我们针对HTTP中的加密型webshell连接,通过攻击模拟的方式[10]收集了webshell客户端通信流量和正常访问的流量,预处理之后根据webshell通信流量的特点提取了文本特征和统计特征,输入到随机森林模型中进行训练,最后使用交叉验证的方法证明了模型的有效性。
2.1 数据预处理
通过攻击模拟的方式产生冰蝎,蚁剑,哥斯拉的通信数据进行数据类型和数量扩充,共得到9280个样本数据,其中每一条样本数据都是与网站通信产生的请求包数据,数据样例为:

样本数据由三部分组成,每个部分使用tab键隔开,第一部分是当前数据的分类,用0或1表示,值为1表示是webshell,第二部分是uri,第三部分是post_data。
为了得到比较规整的数据集,对其进行无效数据过滤、uri解码、对post_data进行base64解码等预处理操作。
2.2 特征提取
使用机器学习方法构建基于流量的检测模型,其中较为关键的步骤就是进行特征提取。我们结合webshell连接所产生流量的特点和专家经验知识,选取了8维特征,包含4维文本特征和4维统计特征,如表1所示。
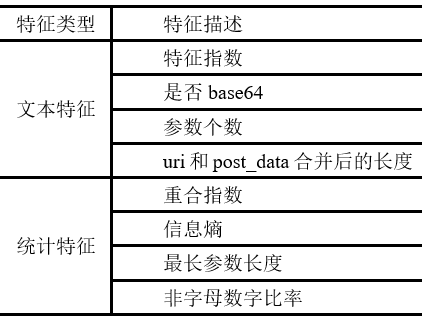
表1 HTTP中webshell检测模型所提取的特征
2.3 模型训练与测试
完成对样本的特征提取后,分别将特征矩阵和标注结果作为输入和预期输出训练分类器,本文选择随机森林模型对样本特征数据进行学习。随机森林是利用多颗决策树进行训练的分类算法,具有分析复杂特征的能力,对于噪声数据具有很好的鲁棒性,具有一定的可解释性,并且学习速度较快。
为了验证随机森林分类模型的有效性,使用三折交叉验证方法进行数据仿真,并采用准确率、召回率和F1值评估模型的性能。在3520个webshell流量样本和5760个正常访问流量样本上进行随机森林分类实验,实验结果如表2所示。
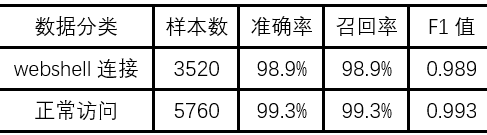
表2 HTTP中webshell检测模型交叉验证结果
三、HTTPS中的加密webshell检测
观察不同类型webshell客户端产生的流量,在包长度、双向流的长度以及超时重连等方面表现出一定的特征和差异。比如蚁剑只有在操作时才会产生流量,并且每次操作都会另起端口,所以导致其一条流内的数据包数量不会太多,但是冰蝎3.0则是在不操作的情况下,每隔一段时间会自动发起连接,并且两次操作相隔时间较短时不会另起端口。
我们针对HTTPS中的加密型webshell,首先通过靶场模拟的方式收集不同类型webshell客户端的连接数据,也收集了正常访问的真实数据,并对其进行预处理操作,然后根据黑白流量之间以及不同类型webshell之间的差异提取内容特征和统计特征,输入到LightGBM流量识别分类模型中进行训练,并将训练好的模型保存下来,最后用测试集验证模型的检测能力,实验结果表明了方法的有效性。
3.1 数据预处理
训练一个好的模型,需要构建一个尽可能反应真实环境的数据集。由于HTTPS的webshell攻击流量获取难度大,所以我们构建靶场环境并设计实现了自动化的模拟攻击脚本,分别针对JSP和PHP网页后门,使用多种类型的webshell客户端进行连接,设计并采集了包括Windows下和Linux下的各种常见的攻击操作和恶意指令所产生的通信流量,最终采集了2.6G的流量数据。
为了对数据进行有效的特征提取,对其进行数据过滤后,使用Cisco开源的网络流量分析工具Joy对收集的流量进行解析,得到json格式的解析结果。最后我们得到的黑白样本的数据量如表3所示,数据量的单位为数据包经过解析之后双向网络流的数量。
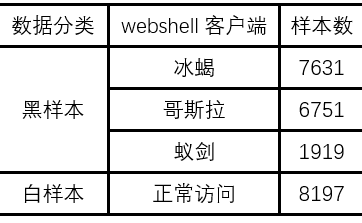
表3 数据统计列表
3.2 特征提取
由于加密流量的载荷是随机且加密的,所以根据观察到的特征以及在加密流量中特征提取的经验,提取了四种主要的无法加密的数据元素,包含四百多维特征,分别是:
(1)数据流元特征;
(2)数据包包长特征;
(3)数据包时间间隔特征;
(4)数据包字节分布特征。
3.3 模型训练与测试
使用LightGBM作为webshell流量识别分类模型,它是轻量级的基于梯度提升算法的学习器,具有训练效率高、内存占用少、准确率高、支持并行化学习、可处理大规模数据等优点。
因为不同类型的webshell客户端的数据量差距较大,所以做了数据平衡,即每种类型的数据剔除掉一部分作为训练集来保证各个类型之间的均衡,这部分数据也可以预留出来作为测试集。随机选出数据集的20%作为测试集,剩余的随机选出20%作为验证集,其他80%作为训练集。如表4所示,展示了平衡之后的数据量和在测试集上运行的结果。
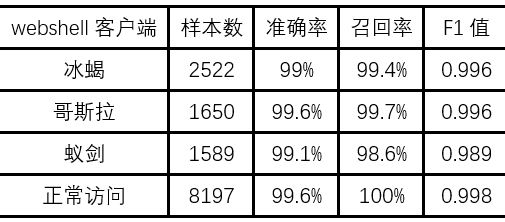
表4 测试集上的效果
将训练好的模型保存下来,测试预留出的那一部分数据,测试效果如表5所示。可以看出,提取出的特征对于不同类型的webshell和白流量具有较好的区分度,也说明了方法的有效性。其中冰蝎3.0的数据只参与了这次测试,训练集中只有冰蝎2.0的数据,而准确度较低的哥斯拉,是因为测试集中包含的哥斯拉Linux下的恶意指令也没有出现在训练集,训练集中只包含了Windows下的恶意指令,说明Linux下和Windows下的攻击操作和恶意指令所产生的流量特征不完全相同,所以在训练集中需要增加样本的丰富程度去提升模型的泛化能力。
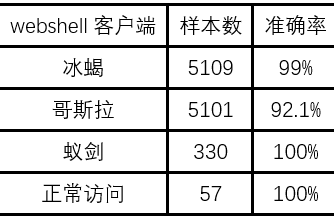
表5 在预留数据集上的测试效果
五、结语
本文针对HTTP中的加密型webshell和HTTPS中的加密型webshell提出了可行的检测方案,后期会通过丰富训练集、增加TLS特征等方式对模型进行优化,不断提升模型对webshell的检测能力和泛化能力,最终与公司不同产品进行融合并实现落地。
参考文献:
[1] https://cdmd.cnki.com.cn/Article/CDMD-10486-1018173805.htm
[2] https://core.ac.uk/download/pdf/82746168.pdf
[3] https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7546497
[4] https://www.sec.cs.tu-bs.de/pubs/2017b-eurosp.pdf
[5] https://link.springer.com/chapter/10.1007/978-3-319-89500-0_54
[6] https://github.com/rebeyond/Behinder
[7] https://github.com/BeichenDream/Godzilla
[8] https://github.com/AntSwordProject
[9] https://www.freebuf.com/column/204796.html
[10] https://www.freebuf.com/articles/web/123779.html
作者: 王萌、余丽辉