
一、背景简介
网络资产探测指的是对网络资产情况进行追踪、掌握的过程,其通常包括主机发现、操作系统识别以及服务应用识别等内容。从网络安全的角度来讲,网络资产探测能够为统一软硬件版本、更新升级软件和设备等工作提供基础信息,是进行网络安全监控、漏洞扫描上报、威胁态势感知等网络安全管理活动的重要前提。
从技术起源上讲,目前广泛使用的新型网络资产探测技术可以分为主动探测、被动探测以及基于搜索引擎的非入侵探测三种技术,其中被动探测方法是指采集目标网络的流量,对流量中应用层HTTP、FTP、SMTP等协议数据包中的特殊字段banner或IP、TCP三次握手、DHCP等协议数据包的指纹特征进行分析,从而实现对网络资产信息的被动探测 。
在被动探测技术当中,基于HTTP协议进行WEB指纹构建,对软件服务、操作系统进行识别是比较常用的一种资产探测与识别技术。而基于HTTP协议进行网络资产探测与识别的方法,又分为基于服务标识(Banner)的识别方法、基于头部字段顺序差异与语法差异的识别方法以及基于处理方式差异的识别方法等。其中基于HTTP banner信息的识别方法是目前使用较为广泛,且简单有效的一种识别方法。通过Banner信息,按照HTTP协议规定,提取诸如Server、User-Agent、Authorizatio等Response头部字段,依据这些字段,我们能够轻易探测获得目标WEB服务器的软件类型,甚至可以精确获取到版本信息及操作系统信息。但是由于Banner可以进行人为修改、伪装或模糊,这使得单纯基于Banner的字段信息进行资产探测与识别的准确率无法得到保证。
本文基于HTTP的Response信息,从Response Header与Response正文中提取了Server字段、Title字段、Authenticate字段、Content-length字段、Status字段5个特征字段,然后对HTTP的Response信息利用BOW模型与TFIDF模型进行文本向量化建模,利用TSNE算法对高维文本向量进行可视化降维。依据TSNE降维的可视化结果,对比分析提取的5个特征字段在表征资产类别,刻画资产特征方面的有效性。最后,基于BOW向量使用文本聚类方法验证聚类结果与特征字段所刻画的簇类差异之间的一致性。
通过本次的验证分析,一方面验证了Banner特征字段所包含资产信息的有效性,另一方面验证了相应文本建模技术在资产特征刻画方面的有效性,为后续进一步利用文本挖掘、NLP等技术对基于HTTP协议进行文本建模的网络资产自动探测识别技术研究奠定了基础,验证了相关技术落地的可行性。
二、相关技术介绍
2.1 文本向量化技术选择
文本向量化即将一个文本表示为一个向量的方法,其可以使用一个统一的向量空间模型(Vector Space Model,VSM)进行表示。所谓的VSM模型,其基本思想是将文本表示为向量空间当中的一个点。在进行文本的VSM构建时,有两个要点。
(1)如何确定向量的维度?
也就是说,将一个文档表示为一个向量时,向量的每个维度表示什么?目前主要有如下定义:
- 在VSM的原始定义中,并未限制每个维度的含义;
- 如果将一个维度定义为一个词、一个短语,或者特定的关键词等,在这种情况下,每个维度是有具体含义的,比较典型的是BOW模型、TF-IDF模型;
- 不对每个维度进行具体含义的定义,进行模型自适应训练获得一些词、句的向量化表示,比较典型的是word2vec词嵌入模型。
(2)如何确定每个维度的取值?
即在确定了每个维度的意义后,每个维度的取值如何确定?实际上取值方式的不同也将导致模型的不同,目前主要使用的有如下方式:
- 以0/1取值表示相应的维度(词、短语等)是否在该文本中存在,即BOW模型与Bit Vector的组合;
- 对每个维度代表的词项进行词频统计,以词频作为维度取值,如最常用的BOW模型;
- 不仅考虑单个文本中的词频,而且考虑整个文本集合当中词项出现的频率大小,通过对每个词项进行重要性评分,获得每个维度的取值,如TF-IDF模型;
- 上述表达方式都忽略了词序、词义对文本向量化的差异表达,因此忽略了每个维度的具体含义,基于词的上下文语义关系为每个词自适应训练一个词向量,进而构成文本的词向量,也就是word2vec的训练方式。
在VSM框架下,BOW不会对文本中的任何词进行编码,同时会忽略文本中的单词的次序,忽略所有语法,是对文本的整体建模,以单词出现的一致性作为文本相似性的判断基准。而基于BOW的TF-IDF则对单词与文档的相关度进行了编码,引入了逆文档频率来识别每个文本当中所具有的独特的、对本文本重要的单词。而基于主题(Topic)分布假设的LSA(Latent Semantic Analysis,潜在语义分析)、PLSA(Probabilistic Latent Semantic Analysis,概率潜在语义分析)以及LDA(Latent Dirichlet Allocation,潜在狄利克雷分配)模型,则通过基于共现矩阵的矩阵分解或者基于贝叶斯的变分推断方法,获得了文本在主题空间的向量表示。进一步,以word2vec为代表的基于浅层神经网络的词向量,在充分考虑词的上下文环境的基础上,表征了词的语义相似性,比上述模型更适合复杂的文本建模任务。
为简化分析过程,本文选择主要选择了BOW模型和TF-IDF模型作为文本向量化的分析模型。
2.2 特征降维技术选择
利用BOW模型对大量文本进行建模时,向量维度很容易就能达到上千维度乃至上万维度,对此可以使用LSA或者LDA模型、使用较低维度的主题空间对文本进行刻画,但这样会丢失一定的信息。因此本文选择了一些特征降维技术,对原始的BOW文本向量进行降维,力求在保证减少信息损失的前提下获得文本向量在较低维度的表达,以二维可视化的方法直观观测文本在向量空间中的分布。
目前使用比较广泛的特征降维技术有PCA、EFA、ICA、SVD、LDA(线性判别分析)等,但这些相对主流的方法无法维持在低维空间文本向量之间的分布关系,仅仅是从方差解释或者特征分解的角度,找出变换特征。
而为了保证高维空间中文本向量之间的分布关系在低维空间中尽可能保留,本文选择使用TSNE(t-Distributed Stochastic Neighbor Embedding)算法,尽最大可能保留了原始高维空间中的文本局部的相似性不被破坏,在二维空间原样呈现出文本向量之间的距离分布关系。这对后续采用的基于距离尺度的文本聚类分析,具有十分好的验证效果。
2.3 聚类算法选择
聚类分析是无监督机器学习算法当中的主体,是基于样本之间具有的聚类关系对原始样本进行无监督簇类划分的方法。目前广泛使用的聚类算法主要有基于距离的层次聚类、Kmean聚类,基于密度的DBSCAN聚类算法、OPTICS算法以及基于网格的聚类算法等。
其中,Kmean算法是一种简单且有效的算法,但其聚类结果受初始聚类中心的选择影响较大,且对于分布复杂的簇类情况很难进行识别;DBSCAN算法则基于样本的密度可达及样本点之间的连通关系,能够有效发现复杂的簇类分布状况,但对于样本密度不同的簇类,其发现能力较差;基于DBSCAN改进的OPTICS算法依照数据点的密度可达聚类对所有样本进行排序,进而很好能够很好地发现不同样本密度的簇类,但其计算复杂度相对较高,在本次实验中,算法计算始终很难收敛。GMM算法基于样本的高斯分布假设,通过EM算法能够很好地发现样本中的簇类分布信息,但其聚类效果同样受初始簇类参数影响较大。
本文主要选择Kmean算法、DBSCAN算法与GMM算法对文本进行聚类分析,并结合TSNE算法进行2D可视化,与相应特征所刻画的簇类情况进行对比验证。
三、实验
3.1 技术处理路线
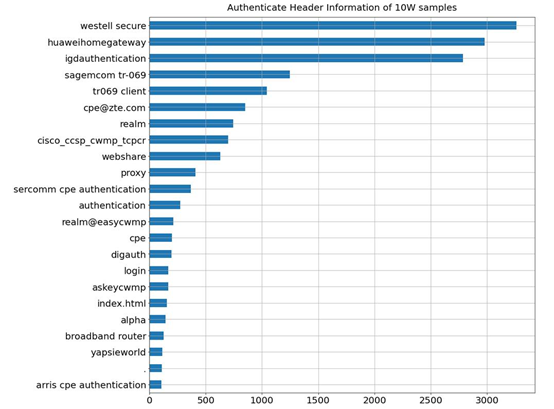
本次实验选取了NTI平台的10万条HTTP协议数据,受限于数据质量,主要从HTTP banner信息中抽取了Response Header中的Server字段、Authenticate字段、Content-length字段、Status_code字段,以及HTML文本中的Title字段、手动构建的全部Banner文本的单词长度Banner_len。
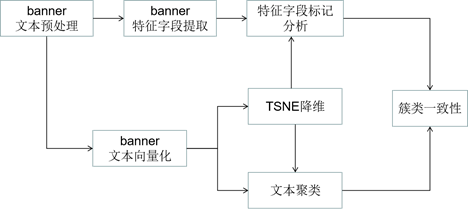
如图1所示,本实验按照如下步骤进行分析。
- 文本预处理:对原始的Banner文本进行分词、停用词删除、特殊字符移除、大小写转换等文本预处理;
- 特征字段提取:从Banner文本中提取构建Server、Authenticate、Content-length、Status_code、Title、Banner_len等特征;
- 文本向量化:使用BOW模型与TF-IDF模型对Banner文本进行向量化处理;
- 降维可视化:使用TSNE模型对文本-单词矩阵进行降维,在2D空间对文本向量进行可视化;
- 特征字段分析:将Banner中提取获得的Server、Authenticate、Title、Status字段分布作为分类响应,在TSNE刻画的2D空间中对其进行不同取值的可视化分析,与整体可视化进行对比,验证特征字段对Banner信息簇类刻画的有效性;
- 文本聚类:分别使用Kmean算法、DBSCAN算法与GMM算法对原始的文本向量进行聚类,获取每个文本的聚类标签;
- 特征字段与文本聚类的簇类一致性分析:在2D降维空间内对不同簇类进行可视化,对比聚类算法的聚类结果与特征字段所刻画簇类之间的一致性,验证聚类算法在该问题场景下的可行性。
3.2 基于TSNE的降维可视化
10万条样本在经过BOW及TF-IDF模型向量化后,每个文本都被转换为一个2000维的向量。显然,当样本达到百万级后,转换后的向量维度会更高,因此使用TSNE算法对样本进行降维后,两种模型所刻画的文本空间分布如图2所示。
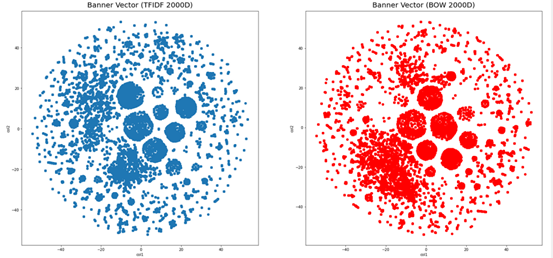
对比来看,基于BOW与TF-IDF的向量化文本在2D空间中均具有明显的簇类分布特征,其差异如图3所示。

总体来讲,两种模型的文本向量化差异不大,后续的特征字段分析将采用BOW向量化文本数据进行处理。
3.3 特征字段的可视化对比
不同的特征字段当中可能还有丰富的网络资产信息,具有相同取值的特征字段直观上讲被作为同一类资产。
而为了探究含有相同取值的字段在实际文本向量空间中的分布是否具有明显的簇类分布规律,我们主要对Server、Authenticate、Title、Status等字段进行了分析。
- Server字段
在10万条数据当中,含有Server字段的约为5万,其字段取值分布频次统计如图4所示(取频次大于100的取值):

我们选取前9个簇类进行可视化,其与全部样本的簇类分布对比如图5所示。
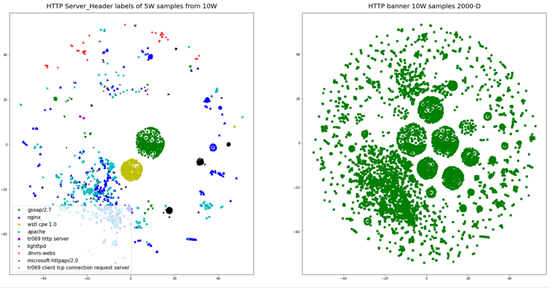
显然,对于取值为gsoap/2.7、与wstl cpe 1.0的资产,其分布簇类明显,在原始分布中具有明显的对应簇类。图6是包含与不包含Server字段之间的簇类分布对比图,显然两者分布具有较大差异。
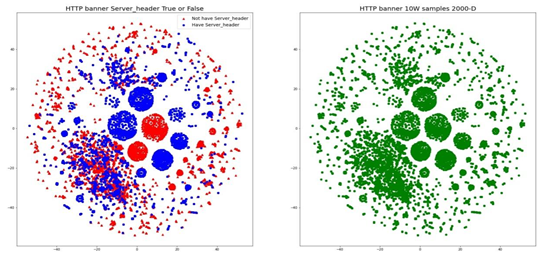
- Status字段
即对HTTP响应的状态码进行分析,发现其也具有明显的簇类分布特性,这里选取了HTTP/1.1协议的200、401、404状态码以及所有的400特征码进行分析,其簇类分布结果如图7所示。
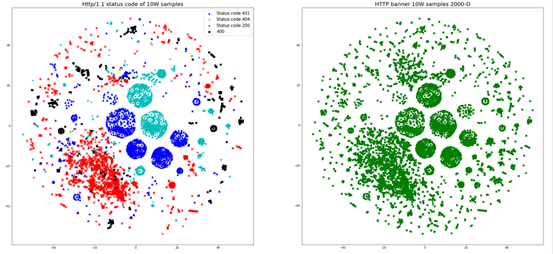
- Title字段
Title字段不属于HTTP的响应头字段,是响应正文中HTML格式文本的Title属性字段,在一些情况下,该字段也包含了丰富的资产信息。就当前样本集分析来看,不存在Title字段的为47418条样本,而在大于1000条统计取值的34440条样本中,绝大多数信息也是与状态码相关的信息。但这也给了我们一个方向,即关注取值频次较少的字段取值,这也可能含有有别于其他资产的特异性文本信息。
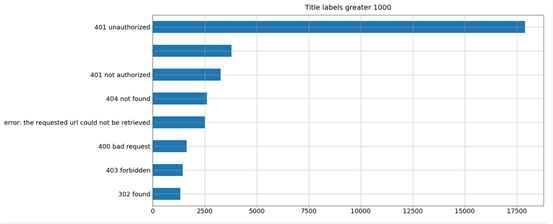
对Title字段当中的信息按照包含信息、不包含信息以及包含信息但取值为空的类别进行可视化簇类对比,其结果如图9所示。
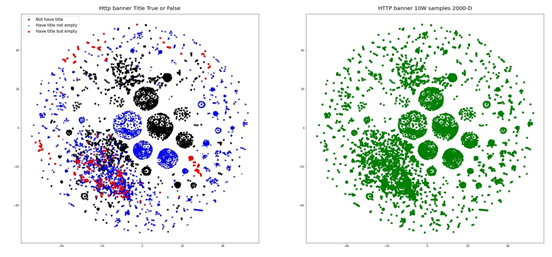
- Authenticate字段
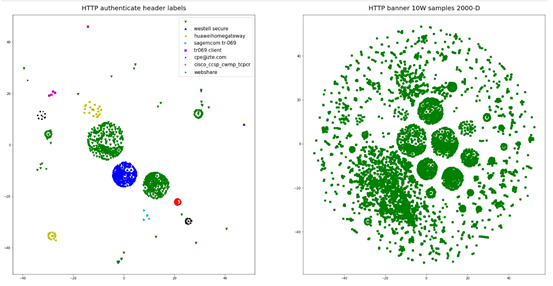
Authenticate包含WEB访问的认证信息,分为WWW-Authenticate与Proxy-Authenticate两种字段。在10条数据当中,存在该字段信息的有34142条样本,而其中又有15011条为空字符,对其剩余字段取值进行簇类分析,取值分布状况如图10所示,其含有丰富的资产信息。
其与原始簇类的分布对比图如图11所示,显然取值具有明显的簇类分布。
3.4 聚类结果验证
通过上述特征字段的簇类分布分析发现,一些特征字段对网络资产特征的刻画具有明显的差异,基于BOW模型的文本向量化可以有效表征不同字段取值的差异。为此,我们采用了基于距离尺度的Kmean聚类、DBSCAN聚类算法,并使用GMM(混合高斯聚类)模型作为对比,其结果如下:
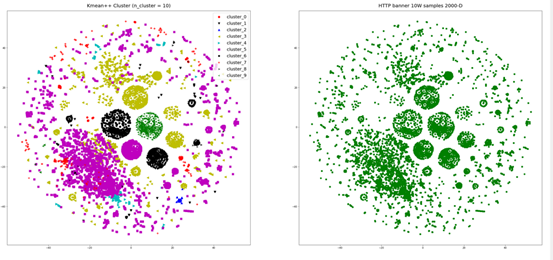
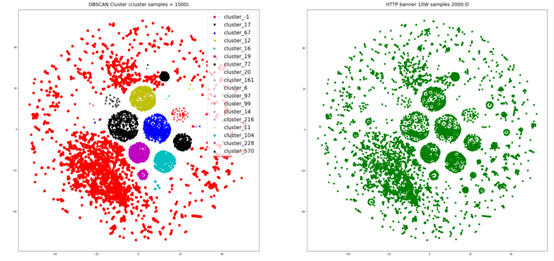
对比发现,两种聚类算法都能发现较为明显的簇类样本,但在细节上,DBSCAN趋向于发现具有同一密度的簇类,对于密度较低的簇类,较容易判为噪声点。相比之下,GMM算法可以将低维空间紧邻的两个簇类识别标识为一个簇类,其簇类分布与之前特征字段的簇类分布具有较高的一致性,这是由于TSNE算法下,低维空间中数据的T分布近似高维空间中的样本的高斯分布距离,低维中较近的两个簇类对应到高维当中将使簇类中心很容易受到边界点的干扰。
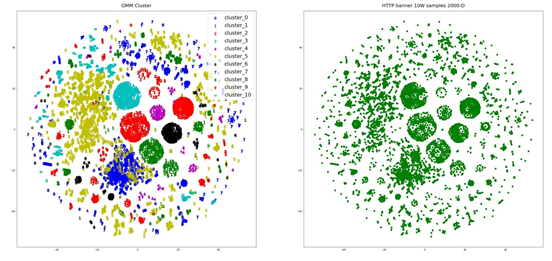
不过这些缺陷对目前的粗略分析影响不大,我们依旧可以通过多种算法聚类结果与特征字段分布簇类的对比,得到一些技术分析的指导信息。
四、总结及下一步工作方向
总体来讲,目前的工作主要有如下结论:
(1)基于BOW模型及TF-IDF变换的HTTP文本向量化,能够有效地捕捉到文本当中包含的资产特征,通过几种聚类算法的自动聚类结果分析,可以验证聚类结果与不同特征字段取值在向量空间中簇类分布的一致性。
(2)侧面验证了特征字段本身包含的资产信息的有效性,可以将基于HTTP协议字段提取的资产信息作为HTTP文本算法分析的辅助标注信息,进一步提升有监督算法训练的有效性。
当然,当前从特征字段当中获取的信息还太过粗糙,基于聚类获得的不同簇类结果还需要进行大量的人工分析与筛选之后,才能确定是否发现了新的资产指纹。这其中存在以下问题。
(1)进行有监督算法学习时,如何确保标注信息的有效性——即便使用最粗糙的二分类判断,确保标签信息本身与文本内容的信息一致性依旧是十分大的挑战。
(2)如果只采用有确定标注信息的数据进行训练,目前可考虑的技术路线有两种:一是只基于有效标注信息训练异常检查算法,对无效文本进行过滤识别,但这种方法很难发现新的资产信息;二是为每类资产指纹训练单独的识别模型,但由于不同的资产指纹可能覆盖了多种不同的乃至相互冲突的文本向量模式,这就使得模型的构建变得十分复杂。
以上这些问题需要我们探索更多的解决方法,以提高我们在资产发现与识别方面的能力。下一步,我们将首先使用word2vec、textCNN等相对更复杂一些的方法进行基于HTTP文本的资产探测与自动发现的技术研究。
参考文献
[1] 王宸东, 郭渊博, 甄帅辉,等. 网络资产探测技术研究[J]. 计算机科学, 2018, 45(12):31-38.
[2] 易运晖, 刘海峰, 朱振显. 基于决策树的被动操作系统识别技术研究[J]. 计算机科学, 2016, 043(008):79-83.
[3] 刘翔元. 基于网络流量分析的网络设备类型识别关键技术研究[D]. 南京邮电大学,2020.
[4] 赵建军. 网络空间终端设备识别技术研究[D]. 兰州理工大学, 2016.
[5] 曹来成, 赵建军, 崔翔,等. 基于余弦测度下K-means的网络空间终端设备识别[J]. 中国科学院大学学报, 2016, 33(004):562-569.
[6] Shah S. An Introduction to HTTP Fingerprinting[J]. Net-Square Solutions, 2004: 1-21.
[7] AHMED ABDOAZIZ AHMED ABDULLA. 击败HTTP指纹识别技术[D]. 吉林大学,2012.
[8] https://blog.csdn.net/flying_all/article/details/77152409
[9] http://lvdmaaten.github.io/publications/papers/JMLR_2008.pdf
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。
留言