一、Claude Code Security技术分析

1. 代码仓库级自动审计
开发者可通过连接代码仓库,要求AI对整个代码库进行代码审计工作。
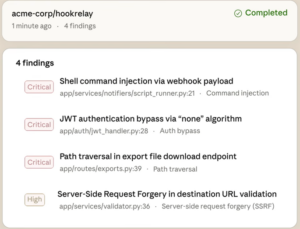
其所呈现的漏洞报告包含以下4个部分:
● 详情 (Detail): 对漏洞成因、攻击面及潜在影响的深度文本解释。
● 数据流追踪 (Data Flow): 像人类研究员一样追踪不可信输入(Taint)在程序组件间的传递路径,识别复杂的业务逻辑错误。
● 位置标注 (Location): 精确指明漏洞发生的具体代码行、文件及受影响的模块 。
● 影响(Impact):漏洞度量评估,攻击复杂性、攻击向量、权限要求、用户交互和影响范围等。

AI 会自动生成针对性的补丁建议, 开发者可预览修复代码,并实现“一键 Pull Request”。从功能上来说,Claude Code Security已经能够像人类安全研究员一样,逐行阅读代码、追踪数据在应用程序中的流动、理解不同组件之间的交互逻辑,并识别出业务逻辑缺陷、访问控制失效等复杂的安全问题。

● 差异感知扫描: 受限于上下文限制,仅针对 PR 中的变更进行深度审计,结合相关CI/CD流提高集成效率。
● 多阶段验证流程: 发现漏洞后,模型会启动过滤模块。该模块利用模型进行二次“反驳推理”,自动过滤掉无实际影响的告警。
● 属性基测试 (Property-based Testing): 这个技术在agentic-pbt提出,红队专用Agent能够从大项目中推断出应有的代码属性(Properties),并自动生成测试用例来探测逻辑边界,目前已成功发现和修复多个 Python 顶级包的漏洞。
同样,模型的更新带来的提升不可小觑。现今发布的Claude Code Security引入了Claude 4.6系列模型,实现了更强大的能力。根据研究报告,在早期测试中,Claude 需要红队开发的Incalmo定制工具集来简化复杂性。然而,到 Claude 4.6 版本,模型已能直接利用标准的Bash、Kali等开源工具在复杂网络中进行自主侦察和漏洞挖掘。
Claude 4.6 引入的自适应思考 (Adaptive Thinking)技术对漏洞挖掘具备一定的效果提升。自适应思考指的是模型能够根据任务复杂度自主决定推理深度。简单漏洞快速响应,复杂逻辑错误则触发“Max Effort”模式,分配更多思维token进行深挖。同时,Claude 4.6模型提供了百万级上下文窗口,最大支持1,000,000 token(1M)数量,能够一次性理解包含历史补丁、架构文档和依赖项在内的超大型代码库。
二、LLM应用与代码审计技术分析
传统SAST工具(如SonarQube、CodeQL等)依赖于预定义的规则库和模式匹配机制,通过构建抽象语法树(AST)、数据流图(DFG)和控制流图(CFG)来分析代码安全性。这种方法在检测硬编码凭据、弱加密算法识别、简单注入漏洞等已知模式方面表现稳定,但难以理解复杂业务逻辑,对跨组件交互的分析能力有限,且完全依赖人工定义的规则库。
相比之下,LLM驱动的代码审计基于语义理解和推理能力。例如,Claude Code Security 依托 Claude Opus 4.6 模型,能够像人类安全专家一样理解代码的业务意图和逻辑关系。这种“推理审计”模式使其在多个维度上实现突破:能够识别传统工具难以定义的业务逻辑漏洞和越权访问缺陷;通过多阶段验证机制显著降低误报率;生成准确且可直接应用的修复补丁;具备语言无关性,大幅降低部署和维护成本。
从技术架构角度看,传统SAST是“规则驱动”的确定性分析,而LLM审计是“语义驱动”的概率性推理。这种差异决定了二者在应用场景上的互补关系:传统工具在合规检查、已知漏洞模式扫描以及检测效率方面仍具优势,而LLM在复杂逻辑分析、0day漏洞发现方面展现出独特价值。
● 适用场景:
1. 复杂业务逻辑漏洞的深度识别: 传统 SAST 工具基于硬性规则,难以理解代码背后的业务意图。LLM 的核心优势在于其预训练过程中获得的语义理解能力,能够分析“访问控制缺陷”、“业务逻辑绕过”等逻辑类风险。在“订单信息获取”场景中,LLM 能够自主识别代码是否包含对订单属主的越权校验,并根据上下文补全校验逻辑。这种基于业务语义的推断能力,是传统工具无法触达的维度。
2. 跨文件与跨组件的复杂链路分析: 现代软件架构中,漏洞往往隐藏在多模块、多服务的交互链中。传统工具在进行过程间分析时,常面临“路径爆炸”问题,导致分析中断。LLM 凭借抽象推理能力,能够在不穷举所有路径的前提下,识别高风险交互模式。如 RepoAudit 采用的智能体机制,利用模型区分相关与无关路径,大幅提升了大型代码库的审计效率。
3. 未知0day漏洞挖掘:传统工具依赖预定义的漏洞库,对未知模式缺乏感知。LLM 基于海量代码模式的学习,能够识别出与已知威胁结构相似、但具体类型未定义的潜在风险。
● 不适用场景:
大规模代码库的全量扫描是LLM当前面临的重大挑战。尽管LLM具有强大的代码理解能力,但其处理长上下文的能力存在固有限制。即使是支持超长上下文的最新模型,在面对数百万行代码的大型项目时也难以一次性处理全部代码。RepoAudit等项目通过智能体的按需探索和记忆机制部分缓解了这一问题,但仍无法达到传统SAST工具在处理超大规模代码库时的效率。对于需要对整个代码库进行定期全面扫描的企业级应用场景,LLM目前更适合作为传统工具检测盲区的补充,而非替代。

表 传统SAST工具和LLM Agentic方法的对比分析
2.4 关键技术挑战与未来突破方向
● 上下文压缩与动态代码加载: 针对长代码路径,未来的研究重点在于如何通过动态加载相关代码片段与保留关键数据流骨架,实现推理精度与计算成本的平衡。
● 结果验证与幻觉抑制: 为解决模型可能生成的虚假漏洞路径,将 LLM 的概率输出与确定性的形式化方法结合,利用有效的漏洞验证等机制确保审计结果的正确性。
● 私有化部署与数据合规: 源代码作为企业核心资产,如何在保证隐私的前提下,在边缘侧实现“小模型+高精度”的审计能力,是企业级落地的关键攻坚点。
● 针对审计工具的防御增强: 随着自动化审计的普及,针对 LLM 提示词注入的代码侧对抗性攻击将愈发频繁。建立鲁棒的防御机制,确保审计模型不被恶意代码诱导或蒙蔽,将是下一代安全工具的标配。
三、AI时代攻防格局的演变
多智能体架构驱动的复杂任务解构
在网络安全领域,单一模型往往难以平衡“效率”与“深度验证”的矛盾,而多智能体系统(MAS)通过角色解构,模拟了人类专家团队的工作模式。我们先于Claude Code Tasks近一年时间实现了基于任务阶段的多智能体协同框架。在该架构中,系统由负责不同任务阶段和不同专用任务的多个专家智能体协同工作。系统的稳健性不再依赖于单一模型的最优性,而是取决于各智能体之间信息交换的质量和反馈循环的效率,有效抑制了 LLM 在复杂攻防分析中的“幻觉”问题。这种架构能够将复杂的渗透测试任务分解为可执行的原子步骤,使得 AI 在处理跨协议、跨语言的组合漏洞时,成功率较单智能体有明显提升。
长上下文动态编排与注意力优化
代码审计与网络攻防本质上都是超长序列任务。即使 Claude 4.6 拥有百万级上下文,但在处理大量命令输出或任务日志时,依然面临注意力分散的挑战。绿盟科技智能化攻防团队在对 LLM 注意力机制的深度观测中发现,上下文的编排顺序与信息密度直接影响模型对攻击链路的推理精度。为此,我们开发了一套高效的动态上下文管理引擎:
● 精细化压缩与冗余剔除:针对安全任务,利用语义依赖分析剔除 80% 的非关键逻辑代码,仅保留与数据流、控制流相关的核心骨架。
● 上下文重组技术:采用“滑动窗口+关键信息置顶”策略,确保模型在推理执行过程中始终保持对关键特征的高敏感度,保障了任务执行的连贯性与准确性。
动态知识注入与工具链的高可靠调用
随着 MCP(Model Context Protocol)等协议的普及,AI 接入安全工具的门槛降低,但随之而来的是“工具过载”与“参数漂移”问题。当智能体面对数百个渗透测试工具时,调用准确率会随工具数量增加而呈指数级下降。绿盟科技智能化攻防团队在动态知识注入与按需工具加载领域取得关键成果:
● 动态路由机制:系统根据当前任务意图,实时从工具库中检索并注入相关的知识内容。
● 复杂参数自动校准:引入了针对安全专用工具的参数约束验证层,使 AI 在调用如 SQLmap、Nmap 等具备复杂命令行参数的工具时,稳定性提升至 95% 以上,实现了真正的“开箱即用”。
Anthropic发布Claude Code Security所引发的网络安全股大幅下跌,不仅揭示了资本市场在面对AI技术变革时的敏感与焦虑,更折射出市场对AI时代安全范式深刻转型的集体认知重构。从技术演进的角度审视,AI正在从根本上重塑网络安全的攻防格局:以每六个月翻一番的速度增长的AI驱动攻击能力,使得传统防御手段逐渐失效,唯有以AI对抗AI,才能在持续升级的对抗中维持基本的安全水位。换言之,AI时代的安全革命已不再是未来议题,而是正在加速展开的现实重构。
Claude Code Security的问世,或许象征着一个更深远的转折点——它代表的并非单一产品的技术突破,而是整体防御体系向智能化、自主化发展的历史性跃迁,需要我们借助AI能力更好地推进主动发现和持续验证的主动式安全高质量落地。只有认识到这一范式转换的本质,才能真正把握AI时代网络安全的本质和未来。