一、事件回溯:一场“看不见的字符变形记”
该风险的核心在于:安全检测链路与应用执行链路对同一输入的编码解释不一致,可能导致前置防护判定为无害,而后端执行阶段恢复为高风险语义。该问题本质属于“端到端语义不一致”而非单一组件缺陷。
1.Ghost Bits编码原理
Ghost Bits(幽灵比特)可理解为:在字符到字节的收窄转换中,被静默丢弃但影响安全语义的高位比特。
以 Java 为例:
– char 是 16 位(UTF-16 code unit)
– byte 是 8 位
– 当代码出现 (byte) ch、ch & 0xFF、write(int) 仅写低 8 位等行为时,高 8 位会被丢弃
这意味着一个 Unicode 字符在某些链路里会“退化”为另一个字节值。攻击者可利用这种差异构造“前后语义不一致”的输入:前置检测看到 A,后端执行却是 B。
2.攻击者如何利用Ghost Bits编码绕过检测
攻击者利用“高位静默丢弃”这一特性,将攻击的payload中关键ASCII字符经过精心构造的Unicode字符替换(低8位与payload保持一致),WAF看到的Unicode字符是无害的字符,而到后端Java服务器解码时高位截断只选取低位从而还原成攻击载荷,从而绕过WAF检测,并能真正执行命令。
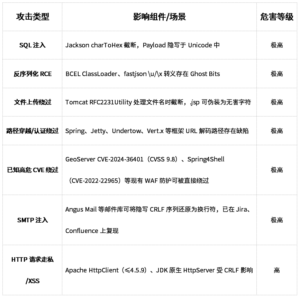
二、危害评估:从WAF绕过到全面沦陷
三、绿盟WAF解决方案:解码层语义检测,让“幽灵”无所遁形
1.产品能力现状:已默认支持Unicode Ghost Bits检测
绿盟WAF当前已支持针对 Unicode 类型 Ghost Bits 编码绕过的检测,默认配置下均已开启:
6090版本:在 Web 解码引擎中默认开启 Unicode 解码,可直接识别并告警 Ghost Bits 变形 Payload。
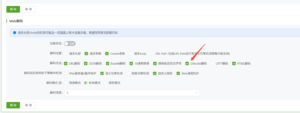
6081 & 6073版本:在语义分析引擎中开启 Unicode 解码后即可实现同等防护能力。
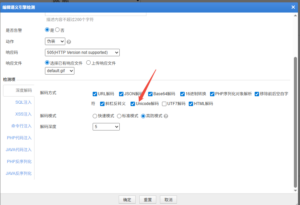
以 SQL 注入检测为例,绿盟WAF已完成针对性验证:

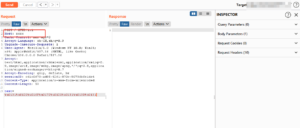
6090页面告警:
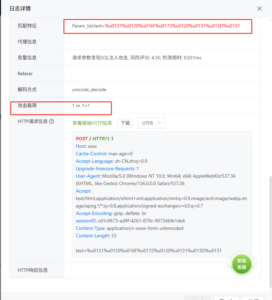
6081页面告警截图:

四、业务侧加固建议:构建纵深防御体系
1.统一输入语义:全链路固定UTF-8
全链路固定使用 UTF-8 编解码,禁止使用“自动猜编解码”。编码不一致是 Ghost Bits 攻击滋生的土壤,统一编码标准可大幅降低风险面。
2.输入规范化 + 白名单校验
- 在业务校验前做 Unicode 规范化(NFC/NFKC)。
- 对高风险字段(用户名、文件名、SQL相关参数、路径)实施字符集白名单。
- 明确拒绝不可见控制字符、异常混淆字符及超预期字符集。
3.数据库执行层:参数化兜底
参数化查询是防注入的最终保险。即使前端WAF被绕过,数据库层的参数化执行也能阻断攻击载荷的实际生效。
4.代码审计:排查高危写法
重点排查业务代码中的 Ghost Bits 典型写法:
(byte)ch
ch & 0xFF
baos.write(ch)
DataOutputStream#writeBytes()
应改为:String.getBytes(StandardCharsets.UTF_8) 等明确指定编码方式的安全写法。
5.网络层面:收缩攻击面
对暴露在公网的 Java 应用服务,限制访问来源,在完成代码修复前通过IP白名单、VPN等方式降低暴露面。