近几年来,随着互联网的普及,网络安全市场份额迅速增长,其开放性、应用市场的多元化等特点,都使得智能应用的开发领域极度繁荣。道高一尺魔高一丈,恶意软件也同样有了爆炸式的增长,直接威胁到个人隐私、支付安全等方面,无疑成为网络安全防护工作的重要目标。但海量恶意样本文件,给恶意软件研判分析工作带来了巨大的压力,如何进行恶意样本分析,如何提高效率,都成为实际的问题。
第四章:静态分析
ApkTool
拆解Apk文件,反编译其中的资源文件,将它们反编译为可阅读的AndroidManifest.xml文件和res文件。
基本用法:在终端下运行命令
java -jar apktool.jar d yourApkFile.apk
// 注意apktool.jar是刚才下载后的jar的名称,d参数表示decode
// 在这个命令后面还可以添加像-o -s之类的参数,例如
// java -jar apktool.jar d yourApkFile.apk -o destiantionDir -s
// 几个主要的参数设置方法及其含义:
-f 如果目标文件夹已存在,强制删除现有文件夹
-o 指定反编译的目标文件夹的名称(默认会将文件输出到以Apk文件名命名的文件夹中)
-s 保留classes.dex文件(默认会将dex文件解码成smali文件)
-r 保留resources.arsc文件(默认会将resources.arsc解码成具体的资源文件)
下图是运行命令后的结果,会生成一个文件夹
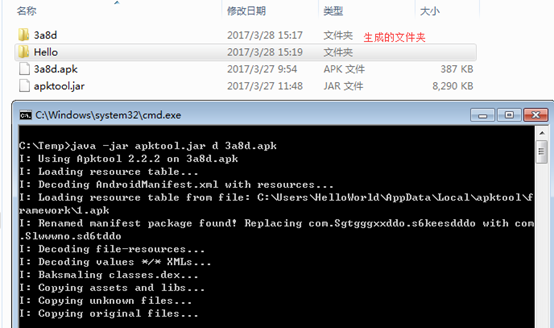
如果要指定生成的文件夹并且保留dex文件的话,可以使用命令
java –jar apktool.jar d FileName.apk –o DirectoryName -s
文件夹中的内容如下,其中的xml文件可以直接打开浏览:
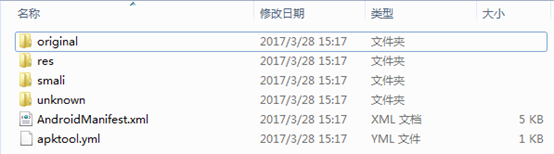
到此已经得到一个可以用文本编辑器打开的阅读的AndroidManifest.xml文件、assets文件夹、res文件夹、smali文件夹等等。original文件夹是原始的AndroidManifest.xml文件,res文件夹是反编译出来的所有资源,smali文件夹是反编译出来的代码。注意,smali文件夹下面,结构和我们的源代码的package一模一样,只不过换成了smali语言。它有点类似于汇编的语法,是Android虚拟机所使用的寄存器语言。
这时,我们已经可以文本编辑器打开AndroidManifest.xml文件和res下面的layout文件了。这样,我们就可以查看到这个Apk文件的package包名、Activity组件、程序所需要的权限、xml布局、图标等等信息
Dex2jar
将dex格式的文件,转换成jar文件。dex文件时Android虚拟机上面可以执行的文件,jar文件大家都是知道,其实就是java的class文件。
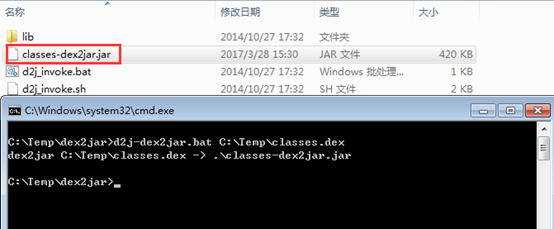
使用方法:使用终端命令定位到工具所在的目录,然后运行命令进行转换
d2j-dex2jar.bat C:\Temp\classes.dex
会在工具所在的目录下生成jar文件
Jd-gui
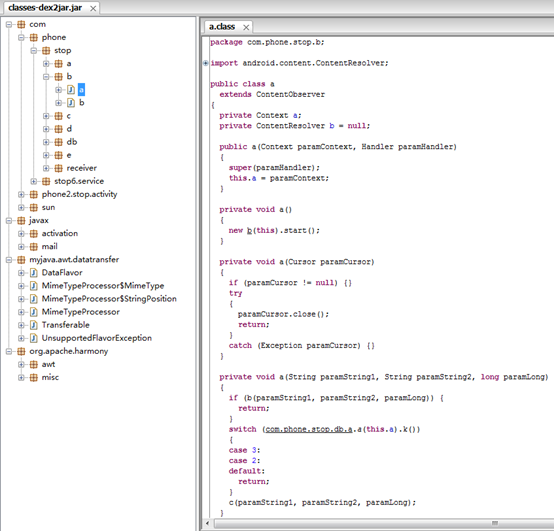
功能查看java源代码
直接双击就可以运行此程序,然后将得到的jar文件直接拖进jd-gui程序的界面就可以查看源码。
IDA
地址跳转
在分析样本时,如果要到另一个函数或者地址处分析,那么可以使用跳转命令来到特定的地址处进行分析。使用命令Jump->Jump to Address或者在反汇编窗口下按G,可以打开Jump to Address对话框
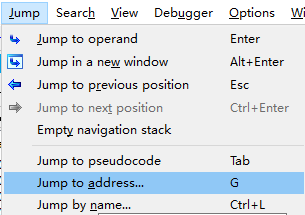
在对话框中输入要跳转的地址,然后点击OK即可。并且IDA会记住我们在这个对话框中输入的值,通过一个下拉列表显示,以方便随后使用。
导航历史记录
当我们分析样本时,通常会从一个函数跳转到另一个函数,接着再跳进其中的子函数,当看完子函数后,我们想回到原始的父函数的代码空间中去,就会用到导航历史记录。我们可以使用工具栏中的jump下的jump to previous position来跳转到前一个位置,jump to next position会跳转到后一个位置。
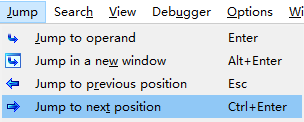
另一种方法比较简单,IDA的工具栏中有如下图所示的两个指针,可以实现同样的效果。
键盘上的esc键同样可以实现向前跳转,不过使用这个键需要谨慎,因为在其他窗口使用这个键的话,会关闭当前窗口,这时候可以使用View->Open Subview来重新打开不小心关闭的窗口。
还有一种更简便的方法,不过不是全部用户都可以使用。目前好多鼠标都有好多键,如果你的鼠标左侧有两个按键的话,也可使用这个按键来达到前进和后退的效果。
文本搜索
IDA文本搜索相当于反汇编列表窗口进行子字符串搜索。通过Search->Text(快捷键ALT+T)命令可以启动文本搜索。
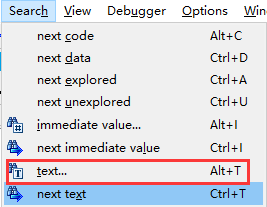

在搜索框中显示了直观的选项规定了与搜索有关的细节,可以根据自己的需要来进行选择。最后,使用CTRL+T命令或者Search->Next Text命令可重复前一项搜索,以找到下一个匹配结果。
二进制搜索
如果需要搜索特定的二进制内容,如已知的字节序列这时就不能使用文本搜索功能,而应使用IDA的二进制搜索工具。二进制搜索仅搜索十六进制视图窗口。使用Search->Sequence of Bytes或者使用快捷键ALT+B即可启动二进制搜索。
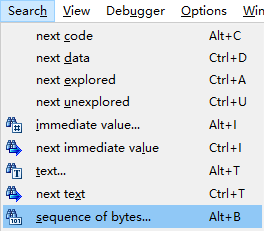
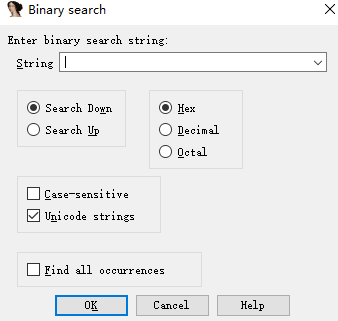
如果要搜索一个十六进制字节序列,应将搜索字符串指定为以空格分隔的两位十六进制值组成的列表。如ab cd,这与搜索AB CD的结果相同。如果要搜索内嵌的字符串数据,那么需要将搜索的字符串用引号括起来。
使用CTRL+B或Search->Next Sequence of Bytes可以搜索随后的二进制数据。最后,你没有必要在十六进制视图窗口中进行二进制搜索,IDA允许在活动的反汇编窗口中指定二进制搜索条件。如果成功找到与搜索条件相匹配的字符串,反汇编窗口将跳转到相应的位置
名称与命名
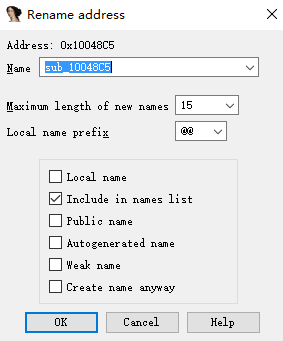
在进行样本分析时,ID A识别出来的函数名都是sub_xxxxxx,这种命名方式不适合我们阅读和分析,在我们进行分析后,知道函数或者变量的意义,那么我们可以对其进行重命名。方法是鼠标点击函数名或者变量,然后按下键盘上的N键,在弹出的窗口中写入新的名字即可。
添加注释
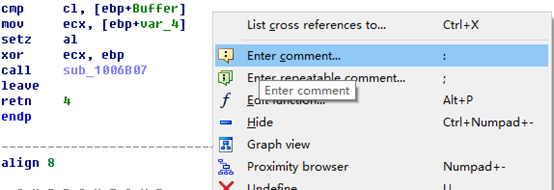
在分析样本时,添加注释特别有用,它可以帮助我们随时掌握分析进程。具体来说,注释有助于以一种更高级的方式描述汇编语言指令序列。比如可以选择使用C语言语句添加注释,来总结某个特殊函数的行为,在随后的函数分析过程中,这些注释有助于迅速回忆起该函数的作用,而不需要重新分析汇编语言语句。
在反汇编窗口中右键某一行,选择Enter comment,或者使用快捷键分号(可重复注释)或冒号(常规注释)来添加注释。
操作函数
在某些情况下,我们可能需要在没有函数的地方创建新函数。新函数可以由已经不属于某个函数的现有指令创建,或者由尚未被IDA以任何其他方式定义的原始数据字节创建。将光标放在将要包含在新函数中的第一个字节或指令上,然后选择Edit->Functions->Create Function即可创建一个新函数。在必要时,IDA会将数据转换成代码,接下来,它会向前扫描,分析函数的结构,并搜索返回语句,如果IDA能够找到正确的函数结束部分,他将生成一个新的函数名,分析栈帧,并以函数的形式重组代码。如果他无法找到函数的结束部分,或者发现任何非法指令,则这个操作将以失败告终。
可以使用Edit->Functions->Delete Function命令删除现有函数。如果认为IDA自动分析错误,就可以使用这个方式来删除这个函数。
指定数组
IDA将高级语言进行反汇编存在一个缺点,那就是它极少提供有关数组大小方面的信息。通常,数组中的其他元素并不直接引用,而是经过更加复杂的索引计算,通过其与数组开头之间的偏移量来引用。使用IDA可以将连续的数据定义结合起来,组成一个单独的数组定义。要创建数组,首先选择数组中的第一个元素,然后通过Edit->Array命令打开创建数组的对话框。如果指定位置的一个数据项已经被定义,那么,当右键该项时,上下文菜单中将显示Array选项。要创建的数据类型有我们选择作为数组第一个元素的项的数据类型决定。
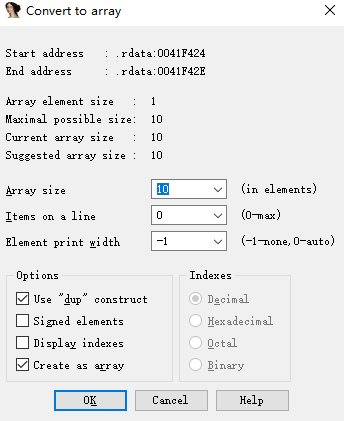
下面对该对话框中用于创建数组的字段进行解释:
- Array element Width(数组元素宽度):表示各数组元素的大小,由打开对话框时选择的数据值的大小决定。
- Maximum possible size(最大可能大小):这个值由自动计算得出,他决定在遇到领域给已经定义的数据项之前,可包含在数组中的元素的最大数目。我们可以指定一个更大的值,但是需要随后的数据项为未定义数据项,以将它们吸收到数组中。
- Number of elements(元素数量):在这里指定数组的具体大小。数组占用的总字节数可以通过“元素数量x数组元素宽度”计算得出。
- Items on a line(行中的项目):指定在每个反汇编行显示的元素的数量。通过它可以减少显示数组所需的空间
- Element width(元素宽度):这个值仅用于格式化。当一行显示多个项目时,它控制列宽。
- Use “dup” construct(使用重复结构):这个选项可将相同的数据值合并起来,用一个重复说明符组合成一项
- Signed elements(有符号元素):表示将数据显示为有符号还是无符号的值。
- Display indexed(显示索引):使数组索引以常规注释的形式显示。
- Create as array(创建为数组):该选项默认处于选中状态。如果只希望指定一定数量的连续项目,而不是将它们组合成一个数组,即可取消该选项。
创建结构体
如果样本使用了某个结构体,当时IDA并不能识别出来,这时就需要我们借助IDA提供的实用工具来设置该结构体的布局,并将新定义的结构体包含到反汇编清单中。IDA使用Structures窗口来创建新的结构体。除非结构体已经在Structures窗口中列出,否则无法将结构体包含到反汇编代码清单中。IDA将自动识别Structures窗口中列出任何它能够识别,并确定已被一个程序使用的结构体。
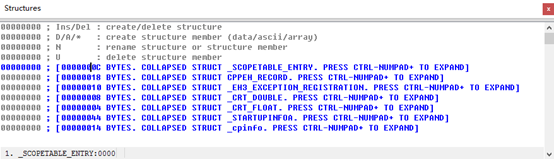
下面以创建一个Test结构体为例进行讲解。
typedef struct Test
{
int field1;
short field2;
char field3;
int field4;
double field5;
}TEST;
在Structures窗口的前4行显示了在该窗口中可能进行的操作,在这里我们使用创建一个结构体的命令Ins。按下按键“Insert”打开如下窗口

在Structure name中输入要创建的结构体名称。前两个复选框用于决定新结构体在Structures窗口中的显示位置,或者是否在窗口中显示新结构体。第三个复选框Create union(创建联合),指定定义的结构体是否为C风格联合结构体。Add standard stucture按钮用于访问IDA当前能够识别的全部结构体数据类型。输入完结构体名名称后,点击OK按钮来创建也给空结构体定义。
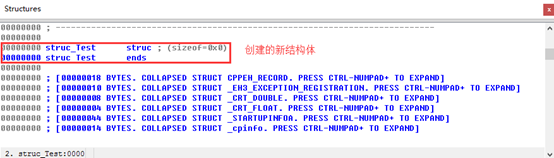
接下来对结构体中的成员进行定义。通过如下几步完成
1.将光标放在结构体定义的最后一行(包含ends的那一行)并按下D键,可以在结构体的末尾添加一个新的字段。
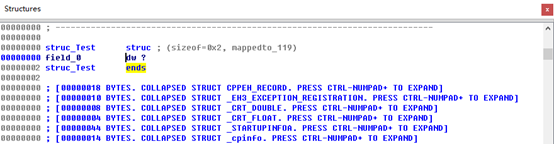
字段的大小取决于逐句转盘上选择的第一个大小。
2.如果需要修改该字段的大小,将光标放在新字段的名称上,然后重复按下D键,使数据转盘上的数据类型开始循环,从而为新字段选择正确的数据大小。还可以使用Options->Setup Data Type来指定一个在数据转盘上不存在的大小。
3.如果要更改一个结构体字段的名称,单击名称并按下N键,在弹出的对话框中输入新的名称即可。
当创建自定义的结构体时,参考下面的提示会有所帮助
- 一个字段的字节偏移量以一个8位十六进制值在structures窗口左侧显示。
- 每次添加或者删除一个结构体字段,或者更改一个现有字段的大小时,结构体的新大小都会在结构体定义的第一行反应出来。
- 可以给结构体的字段添加注释
- 只有当一个字段是结构体中的最后一个字段时,使用U键才能删除该字段。对于所有其他字段,按下U键将取消该字段的定义,这样做仅仅删除了该字段的名称,并没有删除分配给该字段的字节。
- 必须对一个结构体定义中的所有字段进行适当的对齐。
- 可以在结构体的中间添加新的字节,选择新字节后面的一个字段,然后使用Edit->Expand Struct Type可以在选中的字段前插入一定数量的字节。
- 如果知道结构体的大小而不了解它的布局,则需要创建两个字段。第一个字段为一个数组,它的大小为结构体的大小减去1个字节;第二个字段应为1个字节。创建第二个字段后,取消第一个数组字段的定义,这样结构体的大小被保留下来,随后,当进一步了解该结构体的布局后,可以再回过头来定义它的字段及大小。
通过重复应用这些步骤,就可以创建Test结构体。

第五章:动态调试
OllyDbg
Ollydbg是一款强大的动态跟踪工具,Ring3级调试器,具有可视化的界面,它上手容易功能强大,同时还支持插件扩展功能,成为了目前最强大的调试工具。接下来介绍一下OllyDbg的使用方法。
基本操作
F2:设置断点
F8:单步步过,不进入子函数
F7:单步步入进入子函数
F9:运行
F4:运行到光标所在处
CTR+F9:执行到返回,此命令在执行到一个ret指令时暂停,如果进入到一个函数中,代码量比较大,并且没有什么意义,可以使用此命令,直接运行到当前函数的结尾处。
ALT+F9:执行到用户代码。可用于从系统领空快速返回到我们调试的程序领空。
F12:暂停程序执行
窗口
当使用OllyDbg打开可执行程序时默认出现如下界面,包含反汇编,数据,寄存器,堆栈。
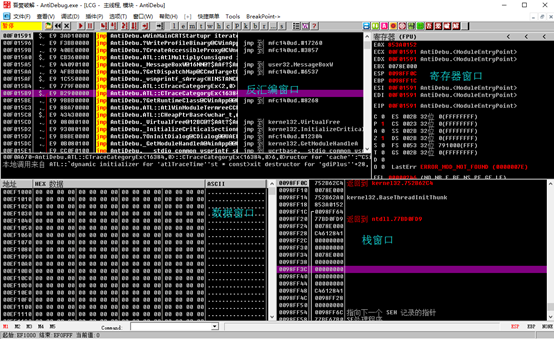
数据窗口
数据窗口用于显示内存或文件的内容。你可以从以下预处理格式[predefined formats]中选择一种显示方式:字节[byte]、文本[text]、整数[integer]、浮点数[float]、地址[address],反汇编[disassembly]、 PE头[PE Header]。
像反汇编窗口一样,数据窗口也保存了大量查看内存地址的历史记录。你可以通过“+”和“—”键来访问过去查看过的数据地址空间。要翻动一字节的数据,可以按住Ctrl+↓或Ctrl+↑。
下图为显示某地址的内存数据:

调用栈
调用栈窗口根据选定线程的栈,尝试反向跟踪函数调用顺序并将其显示出来,同时包含被调用函数的已知的或隐含的参数。
调用栈窗口包含5个栏目:地址[Address]、栈[Stack]、程序/参数[Procedure/Arguments],调用来自[Called from],框架[Frame]。分别介绍如下:
- 地址[Adress]栏包含栈地址
- 栈[Stack]栏显示了相应的返回地址或参数值。
- 程序/参数[Procedure/Arguments]显示了被调用函数的地址
- 调用来自[Called from]用于显示调用该函数的命令地址。
- 框架[Frame]这一栏默认是隐藏的,如果框架指针的值(寄存器EBP)已知的话,则该栏用于显示这个值。

断点
关于断点的原理在理论篇已经介绍过了,所以这里只介绍不同断点的作用和设置方法。
一般断点
直接按下F2键就可在光标位置处下一个一般断点,程序将在设断指令被执行之前中断下来。
条件断点
条件断点是一个带有条件表达式的一般断点,对于频繁调用的函数,仅当特定参数传给他时才中断程序执行,在这种情况下,条件软件断点很有用,可以节省调试时间。可以使用快捷键Shift+F2来添加条件断点,也可以通过右键来选择设置条件表达式。
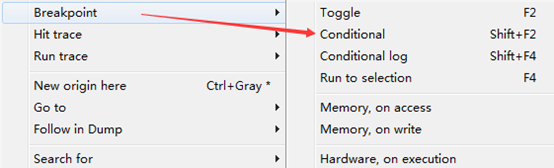
将会出现如下的窗口
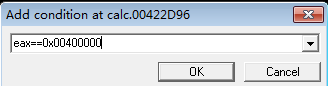
然后在窗口中输入想断下来的表达式即可。
条件记录断点
条件记录断点除了具有条件断点的作用,还能记录断点处函数表达式或参数的值,也可以设置通过断点的次数,每次符合暂停条件时,计数器减一。
比如要记录CreateFileW函数的情况,在CreateFileW函数的第一行,按Shift+4键,或右键选择。
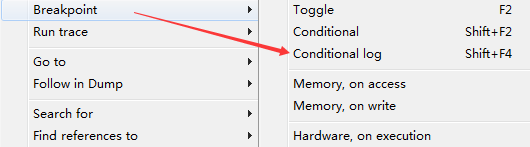
将会出现条件记录窗口,比如我们希望此函数调用时,当ShareMode==2时断下来,并且记录ShareMode的历史值,就可以按如下方式填写:
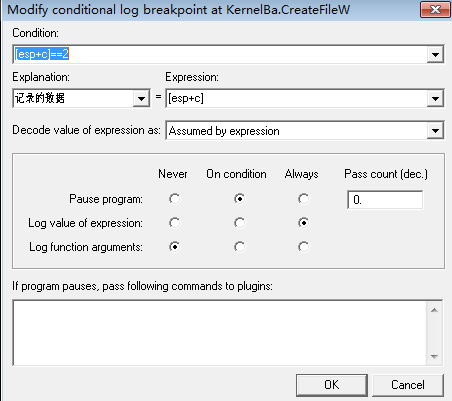
Condition中输入要设置的条件表达式,Explanation中由用户自己设置一个名称,Expression中是要记录的内容的条件,只能设置一个表达式,Pause program是指OD遇到断点时是否中断,Log value of expression是指遇到断点时是否记录表达式的值,Log function arguments是指遇到断点时记录函数参数。
当调试器断下来后,使用快捷键Alt+L查看记录:

如上图:红色部分就是我们记录的数据。
内存断点
OllyDbg每一时刻只允许使用一个内存断点。我们可以在反汇编窗口,CPU窗口,数据窗口中选择一部分内存,然后对其设置内存断点。如果有以前的内存断点,将被自动删除。我们可以设置两类内存断点:在内存访问(读,写,执行)时中断,或内存写入时中断。设置此类断点时,OllyDbg将会改变所选部分的内存块的属性。关于内存断点的原理请参考理论篇的知识。
内存断点的设置方法如下:
硬件断点
硬件断点和内存断点不同,他不会降低程序的执行速度,但是只能允许设置4个硬件断点,它可以可以在不改变代码,堆栈以及任何目标资源的前提下进行调试。
如果需要设置硬件断点,在目标地址处右键,选择BreakPoint->Hardware,on Execution。即可设置硬件断点。
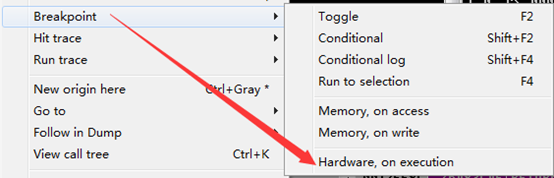
线程
OllyDbg以简单而有效的线程管理为特色。当进行单步调试、跟踪、执行到返回或者执行到所选,则线程管理器将停止除当前线程以外的所有线程。即使当前线程被挂起,它也会将其恢复。可以通过下图的操作来查看线程的状态:
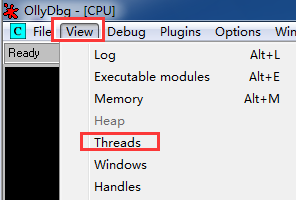
线程窗口中可能会有如下五种状态:
- 激活[Active] 线程运行中,或被调试信息暂停
- 挂起[Suspended] 线程被挂起
- 跟踪[Traced] 线程被挂起,但OllyDbg正在单步跟踪此线程
- 暂停[Paused] 线程是活动的,但OllyDbg临时将其挂起,并在跟踪其它的线程
- 结束[Finished] 线程结束
线程窗口同时也显示了最后的线程错误和该线程以用户模式和系统模式运行的时间。线程窗口还会高亮主线程的标识符。

异常处理
当异常发生时,OD会暂停运行,可以使用以下方法来决定是否将异常转到应用程序处理
- Shift+F7进入异常
- Shift+F8跳过异常
- Shift+F9:运行异常处理
在恶意代码分析期间最好忽略所有异常,因为调试的目的并不是修复这些异常。
WinDbg
简介
WinDbg是个非常强大的调试器,它设计了极其丰富的功能来支持各种调试任务,包括用户态调试、内核态调试、调试转储文件、远程调试等等。WinDBG具有非常大的灵活性和可扩展性,用来满足各种各样的调试需求,比如用户可以自由定义调试事件的处理方式,编写调试扩展模块来定制和补充WinDBG的调试功能。
命令概览
WinDbg主要以命令方式工作,主要分为三类:标准命令、元命令和扩展命令。
标准命令
标准命令通常是一两个字符或者符号,用来提供适用于各种调试目标的最基本调试功能。至今为止,Windbg已经实现了130多条标准命令,分为60多个系列。为了便于记忆,这里根据功能将标准命令分为如下18个子类:
- 控制调试目标执行,包括恢复运行的g系列命令,跟踪执行的t系列命令,单步执行的p系列命令和追踪监视的wt命令。
- 观察和修改通用寄存器的r命令,读写MSR寄存器的rdmsr和wrmsr,设置寄存器显示掩码的rm命令
- 读写IO端口的ib/iw/id和ob/ow/od命令
- 观察、编辑和所搜内存数据的d系列命令,e系列命令和s命令
- 观察栈的k系列命令
- 设置和维护断点的bp(软件断点)、ba(硬件断点)和管理断点的bl(列出所有断点)、bc/bd/be(清除、禁止和重新启用断点)命令
- 显示和控制线程的~命令
- 显示进程的|命令
- 评估表达式的?命令和评估C++表达式的??命令
- 用于汇编的a命令和用于反汇编的u命令
- 显示段选择子的dg命令
- 执行命令文件的$命令
- 设置调试事件处理方式的sx系列命令,启用或禁止静默模式的sq命令,设置内核选项的so命令,设置符号后缀的ss命令。
- 显示调试器和调试目标版本的version命令,显示调试目标所在系统信息的vertarget命令
- 检查符号的x命令
- 控制和显示源程序的ls系列命令
- 加载调试符号的ld命令,搜索相邻符号的ln命令和显示模块列表的lm命令
- 结束调试会话的q命令,包括用于远程调试的qq命令,结束调试会话并分离调试目标的qd命令
在命令行中输入一个问号(?)可以显示主要的标准命令和每个命令的简单介绍。

元命令
元命令用来提供标准命令没有提供的常用调试功能,所有元命令都是以一个点(.)开始,所以元命令也被称为点命令。按照功能,可以把元命令分为如下几类:
- 显示和设置调试会话和调试器选项,比如用于符号选项的.symopt,用于符号路径的.sympath和.symfix。用于源程序文件的.srcpath、.srcnoise和.srcfix,用于扩展命令模块路径的.extpath,用于匹配扩展命令的.extmatch,用于可执行文件的.exepath,设置反汇编选项的.asm,控制表达式评估器的.expr命令
- 控制调试会话或者调试目标,如重新开始调试会话的.restart,放弃用户态调试目标的.abandon,创建新进程的.create命令和附加到存在进程的.attach命令,打开转储文件的.opendump,分离调试目标的.detach,用于杀掉进程的.kill命令。
- 管理扩展命令模块,包括加载命令模块的.load命令,卸载用的.unload命令和.unloadall命令,显示已经加载模块的.chain命令等。
- 管理调试器日志文件,.logfile(显示信息)、.logopen(打开),lopappend(追加),.logclose(关闭)。
- 远程调试,如用于启动exe服务的.remote命令,启动调试引擎服务器的.server命令,列出可用服务器的.servers命令,用于向远程服务器发送文件的.send_file,用于结束远程进程服务器的.endpsrv,用于结束引擎服务器的.endsrv命令。
- 编写命令程序,包括一些类似C语言关键字的命令如.if、.else、.elsif,.foreach,.do,.while,.continue,.catch,.break,.leave,.printf,.block等
- 显示或转储调试目标数据,如产生转储文件的.dump命令,将原始内存数据写到文件的.writemem命令,显示调试会话事件的.time命令,显示线程时间的.ttime命令,显示任务列表的.tlist命令,以不同格式显示数字的.formats命令,输入.help可以列出所有元命令和每个命令的简单说明。

扩展命令
扩展命令用于实现针对特定调试目标的调试功能。Windbg程序包中包含了常用的扩展命令模块,存放在以下几个子目录中。
NT4CHK:调试目标为Windows NT4.0 checked版本时的扩展命令模块。
NT4FRE:调试目标为Windows NT 4.0 Free版本时的扩展命令模块。
W2KCHK:调试目标为Windows 2000 Checked版本时的扩展命令模块。
W2KFRE:调试目标为Windows 2000 Free版本时的扩展命令模块。
WINXP:调试目标为Windows XP或更高版本时的扩展命令模块。
WINEXT:适用于所有 Windows 版本的扩展命令模块。
下表列出了WINXP和WINEXT目录中的所有扩展命令模块
| 扩展模块 | 路径 | 描述 |
| ext.dll | WINEXT | 适用于各种调试目标的常用扩展命令 |
| Kext.dll | WINEXT | 内核态调试时的常用扩展命令 |
| Uext.dll | WINEXT | 用户态调试时的常用扩展命令 |
| Logexts.dll | WINEXT | 用于监视和记录API调用 |
| Sos.dll | WINEXT | 用于调试托管代码和.net程序 |
| Ks.dll | WINEXT | 用于调试内核流 |
| Wdfkd.dll | WINEXT | 调用使用wdf编写的驱动程序 |
| Acpikd.dll | WINXP | 用于调试acpi调试,追踪调用asl程序的过程,显示acpi对象 |
| Exts.dll | WINXP | 关于堆(!heap),进程/线程(!teb/!peb),安全信息(!token,!sid,!acl)和应用程序验证(!avrf)等的扩展命令 |
| Kdexts.dll | WINXP | 包含了大量用于内核调试的扩展命令 |
| Fltkd.dll | WINXP | 用于调试文件系统的过滤驱动程序 |
| Minipkd.dll | WINXP | 用于调试AIC78xx小端口驱动程序 |
| Ndiskd.dll | WINXP | 用于调试网络有关驱动程序 |
| Ntsdexts.dll | WINXP | 实现了!handle,!locks,!dp,!dreg(显示注册表)等命令 |
| Rpcexts.dll | WINXP | 用于RPC调试 |
| Scsikd.dll | WINXP | 用于调试SCSI有关的驱动程序 |
| Traceprt.dll | WINXP | 用于格式化ETW信息 |
| Vdmexts.dll | WINXP | 调试运行在VDM中的dos程序和wow程序 |
| Wow64exts.dll | WINXP | 调试运行在64位Windows系统中的32位程序 |
| Wmitrace.dll | WINXP | 显示WMI追踪有关的数据结构,缓冲区和日志文件 |
执行扩展命令时,以叹号(!)开始,完整格式是
![扩展模块名].<扩展命令名>[参数]
其中扩展模块名可以省略,如果省略,Windbg会自动在已经加载的扩展模块中搜索指定的命令。
因为扩展命令是实现在动态加载的扩展模块中,所以执行时需要加载对应的扩展模块。当调试目标激活时,Windbg会根据调试目标的类型和当前的工作空间自动加载命令空间中指定的扩展模块,同时也可以手动加载,方法如下:
使用.load命令加上扩展模块的名称或者完整路径来加载它,如果没有指定路径,那么Windbg会在扩展模块搜索路径中寻找这个文件,使用.loadby命令加上扩展模块的名称和一个已经加载的程序模块的名称。这时Windbg会在指定的程序模块文件所在目录中寻找和加载扩展命令模块。比如在调试托管程序时,可以使用.loadby sos mscorwks命令让Windbg在mscorwks模块所在的目录中加载sos扩展模块,这样可以保证加载正确版本的sos模块。
使用.chain命令可以列出当前加载的所有扩展模块,使用.unload和.unloadall命令可以卸载指定的或者全部扩展模块。大多数扩展模块都支持help命令来显示这个模块的基本信息和所包含的命令,例如执行!ext.help可以显示ext模块中的所有扩展命令。

上下文
Windows是个典型的多任务操作系统,在一个系统中可以由多个登陆会话(Logon Session),每个会话中可以运行多个进程,每个进程又可以包含多个线程。在调试这样的系统时,大多数命令操作或者执行结果都是基于一定上下文的。Windbg定义了如下几种上下文:会话上下文,进程上下文,寄存器上下文和局部变量上下文,下面讲解每种上下文的含义与切换方法。
登录会话上下文
登陆会话上下文指的是当前操作或陈述所基于的登录会话语境。例如,对于会话A的所有进程来说,会话A的状态和属性便是他们的会话上下文。使用!session扩展命令可以显示或者切换登录会话上下文。
kd> !session Sessions on machine: 3 //系统中有三个会话 Valid Sessions: 0 1 3 //有效的会话ID是0,1,3 Current Session 3 //当前的会话ID是3 kd> !session -s 0 //使用-s可以设置当前的会话ID Sessions on machine: 3 Implicit process is now 898a4da0 //同时把默认的进程切换为898a4da0 WARNING: .cache forcedecodeuser is not enabled Using session 0 //使用0号会话作为上下文
改变会话后,默认进程页随之改变成新会话中的进程,因此以前缓存的用户空间不在有效。目前会话上下文只有在内核调试时才有意义。
进程上下文
进程上下文是当前操作或者陈述所基于的进程语境。Windows系统中的内核空间是共享的,但是用户空间是独立的。
在调试内核时,如果要观察内核空间的数据,那么不用关心当前进程是哪一个,但是如果要观察用户空间的数据,就必须注意当前进程是不是要观察的进程。因为用一个用户地址在不同进程中的含义是不同的。如果要观察其他进程的用户空间,那么必须先将进程上下文切换到那一个进程。可以使用命令.process来观察和设置默认进程。
比如当前进程中有cmd进程。

使用如下命令可以将cmd设置为默认进程

其中89823320是目标进程的EPROCESS结构的地址。
寄存器上下文
寄存器上下文就是寄存器取值所基于的语境。由于CPU只有一套寄存器,所以当它轮番执行系统中的多个任务时,CPU寄存器中存放的是当前正在执行的寄存器值。对于没有执行的线程,它的寄存器值被保存在内存中,当CPU要执行这个任务时,这些寄存器值被从内存加载到物理寄存器中。
系统在以下几种情况下会将CPU的寄存器值保存到当前线程的上下文记录中
- 当系统做线程切换时,系统会将要挂起线程的寄存器取值保存起来,这个上下文常被称为线程上下文
- 当发生中断或者异常时,系统会将当时的寄存器取值保存起来,这个上下文常被称为异常上下文
使用.thread命令可以显示或者设置寄存器上下文所针对的线程,例如如下命令可以显示当前的隐含线程。
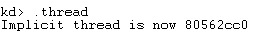
使用!process <所属进程的EPROCESS结构地址> f可以列出进程的所有线程,包括每个线程的ETHREAD结构。

把ETHREAD结构的地址作为.thread命令的参数,便可以将这个线程的上下文设置为新的线程上下文。

输入.cxr或者输入不带参数的.thread命令,可以将线程上下文恢复成以前的情况。
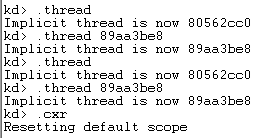
局部变量上下文
局部变量上下文指的是局部变量所基于的语境,局部变量时定义在函数内部的变量,这些变量的含义与当前的执行位置密切相关。在调试时,调试器默认显示的是当前函数所对应的局部上下文。
使用不带参数的.frame命令可以观察当前的局部上下文,例如:
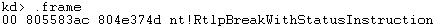
标明当前栈帧所对应的函数是RtlpBreadWithStatusInstruction。
使用.frame加上栈帧号可以将局部上下文切换到指定的栈帧。

观察模块信息
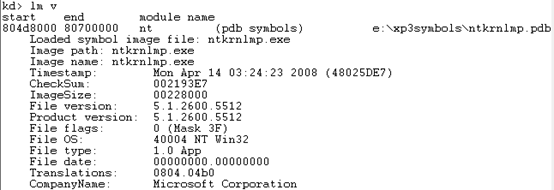
使用lm命令可以显示一个简单的列表:

其中start列和end列分别是该模块在进程空间中的起始地址和结束地址,module name是模块名称,第四列是符号文件的完整名称(如果已经加载符号文件)或者空白。
使用v选项可以显示每个模块更丰富的信息。
可以使用以下的方法来控制要显示的模块
- 使用m开关来指定对模块名的过滤模式,例如lm m k*显示模块名以k开头的模块
- 使用M开关来指定对模块路径的过滤模式
- 使用o开关只显示加载的模块(排除已经卸载的模块)
- 使用l开关只显示已经加载符号的模块
- 使用e开关只显示有符号问题的模块
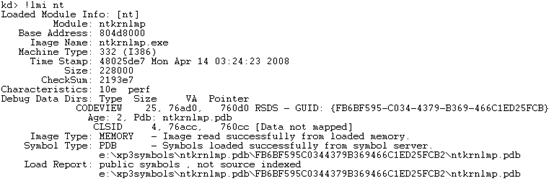
使用!lmi扩展命令可以观察模块的信息,但是这个命令每次只能观察一个模块
单步执行
如果调试时,当前的指令或者代码包含函数调用,我们可以跟踪进入要调用的函数,也可以忽略要调用的函数,让其执行完毕后在停下来。前一种方式通常称为单步进入(step into)命令为p,后一种方式称为单步越过(step over)命令为t。如果当前行不包括函数调用,那么命令p和命令t的作用一样。
除了基本功能外,可以通过向p和t命令附带参数来使用他们的附加功能。完整语法如下:
p|t [r] [=StartAddress] [Count] [“Command”]
r表示禁止自动显示寄存器的内容,默认情况下每次单步执行后,Windbg会自动显示各个寄存器的值。
默认情况下,调试器总是让程序从当前位置开始单步执行,但是也可以通过等号(=)来指定一个新的起始地址,让程序从这个新地址开始执行。需要注意的是,如果指定的地址跳过了调整栈的代码,那么栈就会失去平衡,目标程序很快会出现严重错误,所以这个功能应该谨慎使用。
Count用来指定要单步执行的次数,如果count大于1,那么执行好一次单步并更新显示后,Windbg会再发送一次单步命令,知道达到指定的次数。
[“Command”]参数用来指定每次单步执行后要执行的命令。例如 p “kb”会在单步执行后自动执行kb命令。
单步执行到指定地址
pa和ta命令用来执行到指定的代码地址,命令格式如下:
pa|ta [r] [=StartAddress] StopAddress
其中pa是step to Address的缩写,即单步执行到StopAddress参数所代表地址处的指令,如果中间有函数调用,则不进入所调用的函数。ta命令与pa命令相似,只不过遇到函数调用时会进入到函数中。
因为伪寄存器$ra总是代表当前函数的返回地址,因此可以使用pa或者ta命令加上@$ra来“步出”当前函数,也就是从当前位置返回单步直到返回上一级函数,其效果相当于gu命令(执行到上一层函数)。
单步执行到下一个函数调用
pc和tc命令用来单步执行到下一个函数调用指令(call),命令格式如下:
pc|tc [r] [=StartAddress] [Count]
pc和tc命令命令都是让调试目标从当前地址或者StartAddress指定的地址恢复执行,直到遇到函数调用指令时停下来,Count参数用来指定遇到的函数调用指令的个数,默认为1.
不同之处与p和t指令的差异一样,如果当前指令不是函数调用指令,而且Count参数为1,那么pc和tc是等价的。
单步执行到下一分支
tb命令可以一次执行到下一条分支指令。这条指令使用了CPU的硬件支持,所以tb命令与tc和pc这样反复多次执行不同,它设置好标志寄存器和MSR寄存器后,便让目标程序恢复运行,然后当cpu执行到分支指令时,报告异常停下来。从这个意义上来说,tb命令比tc和pc更高效。它的语法格式和pc与tc的格式一样:
tb [r] [=StartAddress] [Count]
在x64系统下,tb命令既可以用在内核调试,也可以用在用户态调试,但是在x86平台下这个命令只能用在内核调试中,但是我们可以使用ph和th命令来达到同样的效果,其命令格式如下:
ph|th [r] [=StartAddress] [Count]
这两个命令分别用来单步执行或者追踪到下一分支指令,处理call指令的方式不同是他们唯一的区别。
控制目标程序执行命令小结
| 命令 | 含义 | 说明 |
| p | step | 单步,如果遇到函数调用则一次执行完函数调用 |
| t | trace | 追踪,如果遇到函数调用则进入被调用函数 |
| pa | step to address | 单步到指定地址,不进入子函数 |
| ta | trace to address | 追踪到指定地址,进入子函数 |
| pc | step to next call | 单步执行到下一个函数调用(call指令) |
| tc | trace to next call | 追踪到下一个函数调用(call指令) |
| tb | trace to next branch | 追踪执行到下一条分支指令,只适用于内核调试 |
| pt | step to next return | 单步执行到下一条函数返回指令 |
| tt | trace to next return | 追踪执行到下一条函数返回指令 |
| ph | step to next branch | 单步执行到下一条分支指令 |
| th | trace to next branch | 追踪执行到下一条分支指令 |
| wt | trace and watch data | 自动追踪函数执行过程 |
| g | go | 恢复运行 |
| gh | go handled | 恢复执行,告诉系统已经处理异常 |
| gn | go not handled | 恢复执行告诉系统没有处理异常 |
| gu | go up | 执行到本函数返回 |
断点
软件断点
软件断点就是通过将指定位置的指令替换为断点指令(INT 3)而设置的断点.Windbg设计了3条命令来设置软件断点,分别是bp,bu和bm。下面对它们进行介绍:
bp是最基本的而且是最常用的,其命令格式如下:
bp [ID] [Options] [Address [Passes]] [“CommandString”]
其中ID用来指定断点编号,如果不指定,Windbg会自动选择一个编号,Options用来指定选项。Address是指断点的地址,如果不指定,那么默认使用当前程序指针所代表的地址。Passes用来指定因为这个断点而中断到命令模式所需穿越(命中)次数,默认值为1.也就是命中一次就中断到命令模式。如果这个值大于1,那么当这个断点命中时,Windbg会把穿越计数减1,然后判断其值是否等于0,如果大于0,便直接让程序恢复执行,直到等于0时才进入命令模式中断给用户看。“CommandString”用来指定一组命令,当断点中断时,Windbg自动执行这组命令,多个命令用分号隔开。例如以下bp命令可以在printf函数的入口偏移3的地址处设置一个断点,当cpu第二次“穿越”这个位置时中断给用户,并自动执行kv和da poi(ebp+8)命令。
bp MSVCR80D!printf+3 2 “kv;da poi(ebp+8)”
bu命令用来设置一个延迟的以后再落实的断点,用于对尚未加载模块中的代码设置断点。当指定的模块被加载时,Windbg会真正落实这个断点。所以bu命令对于调试动态加载模块的入口函数或初始化代码特别有用。例如,当调试即插即用设备的驱动程序时,因为驱动程序是由操作系统的IO管理器动态加载的,当我们发现它加载时,它的入口函数DriverEntry和初始化代码已经执行完了。对于这种情况,就可以使用bu命令在这个驱动加载前就对它的入口函数设置一个断点,即bu MyDriver!DriverEntry.
bm命令用来设置一批断点,相当于执行很多次bp或bu命令。比如如下命令,可以在mscvr80d模块中的所有print开头的函数设置断点:
bm msvcr80d!print*
因为在数据区设置软件断点会导致数据意外变化,所以bm命令在设置断点时会判断符号的类型,只对函数类型的符号设置断点。处于这个原因,bm命令要求目标模块的调试符号有类型信息,这通常需要私有符号文件。如果对只有公共符号文件的模块使用bm命令,就会显示如下错误:
解决这个问题的方法时使用/a开关,它会强制bm命令针对所有匹配的符号设置断点,不管这个符号对应的是数据还是代码。

bm和bu命令的格式与bp类似:
bu [ID] [Options] [Address[Passes]] [“CommandString”] bm [Options] SymbolPattern [Passes] [“CommandString”]
其中Options可以是以下内容:
- /1:如果指定此选项,那么这个断点命中一次后会被自动从断点列表中删除,这种断点被称为一次命中断点。
- /p:这个开关只能用在内核调试中,/p后跟一个EPROCESS结构的地址,作用是只有断点事件发生在指定进程时才中断到命令模式,也就是增加了一个过滤条件
- /t:与/p开关类似,只能用在内核调试中,用来指定一个ETHREAD结构,作用是只当断点事件发生在指定的线程中时才中断到命令模式
- /c和/C:这两个开关后面可以带一个数字,用来指定中断给用户的最大函数调用深度和最小函数调用深度。
硬件断点
硬件断点是通过CPU的硬件寄存器设置的断点。Windbg使用ba命令来设置硬件断点,格式如下:
ba [ID] Access Size [Options] [Address [Passes]] [“CommandString”]
其中ID用来指定断点的序号,与bp命令一样。Access用来指定触发断点的访问方式,如下:
- e:当从指定地址读取和执行指令时,触发断点,这种断点又称为访问代码硬件断点。从效果上看,这种断点与软件断点类似,但是好处是不需要做指令替换和恢复
- r:当从指定地址读取和写入数据时触发断点。
- w:当从指定地址写数据时触发断点,通过w和r设置的断点又称为数据访问断点
- i:当向指定的地址执行输入输出访问(I/O)时触发断点,这种断点又称为访问I/O断点。
Size参数用来指定访问的长度,对于访问代码硬件断点,它的值应该为1,对于其他硬件断点,允许的长度值因平台不同而不同,对于x86系统可以为1、2、4(字节),对于x64系统可以为1、2、4、8(字节)四种值。
Address参数用来指定断点的地址
Passes和CommandString参数的用法与软件断点一样
条件断点
在调试程序的时候,如果要分析的代码或变量被多次执行和访问,那么对它设置的断点会返回命中,而我们可能只关心特定条件时的命中,不关系其他情况。为了避免断点返回命中而浪费时间,可以使用条件断点,当断点发生时,调试器会检查断点条件,对于不关心的情况,立刻恢复目标执行,当关心的情况发生时中断给用户。
可以使用下面的方式设置条件断点:
bp|bu|bm|ba Address “j (Condition) ‘OptionalCommands’; ‘gc’ ”
bp|bu|bm|ba Address “.if (Condition) {OptionalCommands} .else {gc}”
其中Conditino用来定义希望中断的情况,OptionalCommands用来定义关心的情况发生中断到命令模式时顺便执行的命令。举例来说,以下是使用j命令设置的条件断点命令:
bp dbgee!wmain “j (poi(argc)>1) ‘dd argc 11;du poi(poi(argv)+4)’;’gc’”
这个命令对dbgee程序的wmain函数设置一个条件断点,只有当命令行参数的个数大于1时,才中断给用户,中断时执行两条命令,一条是dd argc 11,用来显示argc参数的值,另一条是du poi(poi(argv)+4),用来显示第一条命令行参数的字符串内容。
设置针对线程的断点
对于多线程程序,如果有多个线程都会调用某个函数,但是我们希望只在某个线程调用时才中断下来,我们可以使用~加线程号来下此类断点。例如,以下命令对msvcr80d!printf设置一个断点,这个断点是线程相关的,只有当0号线程执行到这个函数时才会中断给用户:
~0 bp msbvcr80d!printf。
这种方法适用于用户态调试,对于内核态调试可以使用/p和/t选项来指定断点的进程上下文和线程上下文。
断点管理
使用bl命令可以列出当前已经设置的所有断点,bc,bd和be分别用来删除,禁止和启用断点,格式如下:
bc|bd|be 断点号
其中断点号可以使用*来通配所有断点,使用-来表示一个范围,或者使用逗号来指定多个断点号,举例如下:
bd 0-2,4 //禁止0,1,2和4号断点 be * //启用所有断点
可以使用br命令改变某个断点的编号。例如当3号断点删除后,可以使用br 4 3将4号断点的编号改为3号。
线程控制
当可执行程序被中断到调试器时,它的所有的线程都是被挂起的,当恢复执行的时候,所有的线程都被恢复执行。但是有时我们只想调试一个线程,而让其他的线程挂起,可以参考如下介绍的方法。
方法一:通过增加线程的挂起计数来禁止线程恢复运行。
使用~命令列出进程中的所有线程

这些列含义从左到右依次是线程序号,Id,进程ID,线程ID,挂起计数,线程环境块地址(Teb)和线程的冻结状态。
可以使用命令~Thread n命令来增加Thread线程的挂起计数,比如我们输入~1 n来增加1号线程的挂起计数

与~n命令相对的是~m,用来减少线程的挂起计数
方法二:使用~f和~u命令来对线程进行冻结(Freeze)和解冻(Unfreeze)。当线程处于冻结状态时,恢复目标的执行后,处于冻结状态的线程不会执行。
使用命令~1 f将1号线程设置为冻结状态

方法三:在恢复执行的命令前通过线程限定符和线程号只恢复执行指定的线程。
使用命令~2 g只恢复2号线程运行

观察栈数据
在程序调用call命令时,会将函数的返回地址记录在栈上,通过栈顶向下遍历每个栈帧来追溯函数调用的过程称为栈回溯,使用k系列命令可以查看栈回溯。
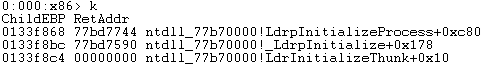
下面对上图中的栈数据进行解释:
横向来看:第一行是当前线程中断到调试器时正在执行的函数,每个函数的下一行是调用这个函数的上一级函数(父函数)。
纵向来看:第一列是栈帧的基地址,第二列是函数的返回地址,这个地址是父函数中的指令地址,通常是调用call指令的下一条指令的地址。第三列是函数名以及执行位置。
kb命令可以显示放在栈上的前三个参数。但是对于使用fastcall方式的函数调用,它们的参数是通过寄存器来传递的,此时,栈上的前三个数可能并不是真正的前三个参数。

kp命令可以把参数和参数值以函数原型的形式展示出来,但是只能用于有调试符号时才能达到这个效果。
kv命令可以在kb命令的基础上增加显示FPO信息和调用协议。
kn命令会在每行前显示栈帧的序号,如果指定f选项,Windbg会显示每两个相邻栈帧的内存距离。

dv命令可以查看栈上的局部变量

第一列prv表示这个信息是利用私有符号产生的。第二列是变量的类型,param表示函数参数,local表示局部变量,第三列是变量的内存起始地址,这个地址属于当前函数栈帧。第四列是使用EBP所表示的变量的起始地址。第五列是变量的类型,第六列是变量的名称,后面是变量取值。同样,使用这个命令需要有私有符号信息,如果没有的话,dv命令无法工作。
命令.frame可以切换栈帧,然后再使用dv命令来查看切换后的栈帧中的局部变量。
显示内存数据
在Windbg中使用d系列命令来显示指定地址的内存区域,命令格式如下:
d{a|b|c|d|D|f|p|q|u|w|W} [Options] [Range]
大括号中的字母用来指定数据的显示方式,是区分大小写的。a表示ASCII码,b表示字节和ASCII码,c表示DWORD和ASCII码,d表示DWORD,D表示双精度浮点数,f表示单精度浮点数,p表示按指针宽度显示,q表示四字(8字节),u表示UNICODE字符,w表示字,W表示字和ASCII码。Range指定显示的内存范围。
有些字符串是使用UNICODE_STRING结构和STRING结构来表示的,如果要显示这两种结构存储的字符串,可以使用dS来显示UNICODE_STRING结构,用ds命令来显示STRING结构。
dt命令用来显示数据类型和按照类型来显示内存中的数据。
使用格式为dt [模块名!] 类型名

其中的模块名可以省略,如果省略,那么调试器会自动搜索所有符号文件。如果类型名是确定的类型,那么dt便会显示这个类型的定义,如果类型中包含子类型,可以使用-b选项来递归显示所有子类型,也可以使用-r选项来指定显示深度,-r0表示不显示子类型,-r1表示显示1级子类型。如果不想显示整个结构,而是只显示某些字段,可以在类型名后使用-ny开关附加搜索选项,比如下图表示只显示_PEB中的ImageBaseAddress字段。

如果在类型后面添加内存地址,那么dtml就会按照指定的类型来显示指定的内存中的数据,比如使用dt _peb 0x89343400命令是把内存地址0x89343400处的数据按照_PEB结构显示出来。
命令e用来修改指定内存地址的内容,格式为e{a|u|za|zu} Address “String”;其中Address是要修改内存的起始地址,za代表以0结尾的ACSII字符串,zu代表以0结尾的Unicode字符串,a和u分别代表不是以0结尾的ASCII和Unicode字符串。
Dnspy
简介
dnSpy 是一款针对 .NET 程序的逆向工程工具。该项目包含了反编译器,调试器和汇编编辑器等功能组件,而且可以通过自己编写扩展插件的形式轻松实现扩展。该项目使用 dnlib读取和写入程序集,以便处理有混淆代码的程序(比如恶意程序)而不会崩溃。
使用方法
将要分析的样本直接拖进dnspy中,然后右键拖进去的样本,选择Go to Entry Point。dnspy将为你定位到函数的入口点。
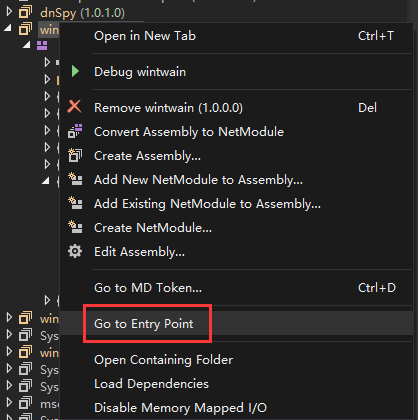
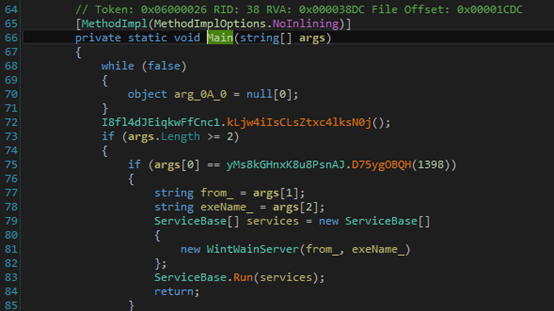
从上图中可以看到有些函数名是乱码,这是代码混淆的结果,因为一般.NET的样本都会进行混淆,可以使用网上的一些工具尝试进行反混淆。不过,将样本的混淆去除的概率比较低。
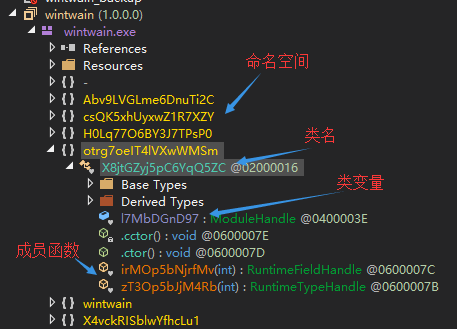
下图所示为dnspy解析出来的结构树形图,包含命名空间,类名,类中定义的变量和成员函数。
对于经过混淆的样本,如果我们经过分析,知道了函数的作用,可以对函数进行命名。在要进行命名的函数上右键,选择Edit Method。
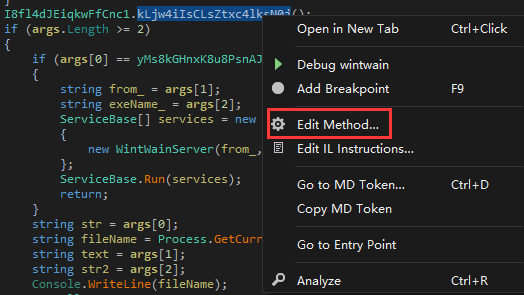
在弹出的对话框中的Name窗口输入我们构造的函数名即可。
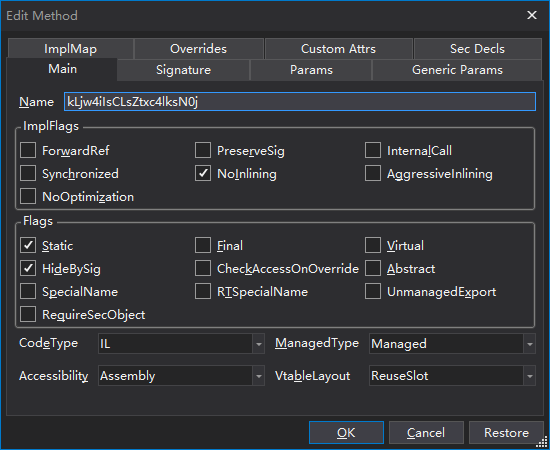
在dnspy中点击函数名即可进入到对应的函数定义中,当看完函数之后要返回时,可以使用菜单栏上的左右方向的箭头进行后退和前进。
默认情况下dnspy显示的语言类型为C#,不过我们可以对显示的语言进行选择,如下图所示,有三种语言供我们选择,分别为C#,VB,IL,可以根据自己的喜好来让dnspy显示不同的语言。
要对样本进行调试时,选择菜单栏的Debug->Debug an Executable…。在调试之前需要将目标样本的后缀名改为exe,否则dnspy无法找到样本。
弹出如下对话框,在Executable框中输入样本的路径,或者点击后面的按钮进行查找。在Arguments窗口中输入样本需要的参数,参数之间使用空格隔开,下面的选项默认即可,点击Debug按钮,dnspy会自动停在函数的入口处。
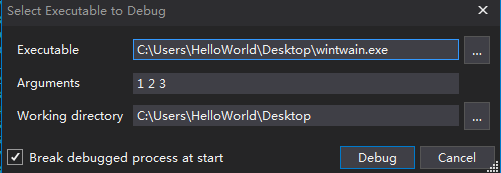
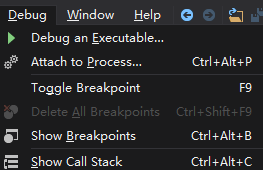
在菜单栏Debug选项下显示了调试需要使用的一些指令,F11表示单步进入,F10:单步步过,Shift+F11:退出当前函数,F9:添加或删除断点。

在调试时,如果想看某个变量的值,只需要将光标在目标变量上停留片刻就可以显示变量的值。

相关链接:
恶意样本分析手册——工具篇(上):https://blog.nsfocus.net/malicious-sample-analysis-manual-tool-1/
恶意样本分析手册——理论篇:https://blog.nsfocus.net/sample-analysis-manual-theory/
如果您需要了解更多内容,可以
加入QQ群:570982169
直接询问:010-68438880