一、 前情提要
前一篇文章中初步探讨了通过评估攻击意图确定告警实际危害程度的可行性,并明确了特征提取方法(输入)和标签结构(输出),已经具备了应用数据分析方法的基础。那么接下来的问题,就是建模和验证了。
二、为何是监督学习方法
我们在长达数月的实验中尝试了各种各样的分析方法,试图在告警载荷特征向量与攻击意图向量之间找到映射关系。这些方法涵盖了多种全监督、半监督、无监督方法。
2.1 无监督方法尝试
在攻防领域的真实攻击事件可遇而不可求,专家人工标注的成本也很高昂。而无监督方法不需要标注样本,自然成为首选。
由于原始问题是要找出大量样本中的少数特殊样本,我们在多个维度上运行了多种异常检测方法,并将TopN最异常的告警交由人类专家进行研判确认,从而评估模型的准确率。
从结果来看,异常检测方法确实具有一定效果,尤其以行为集合关联图结构信息的异常检测效果良好。但尽管如此,在实战测试中,绝大多数异常检测方法的准确率都很难稳定超过50%~60%。
究其原因,我们很难找到一个特征维度,使得关键攻击导致的告警从中孤立,而业务波动导致的告警却不会孤立。
实践看来,很多恶意行为,诸如扫描、蠕虫活动等,其告警数量相当大,已经远远超过了很多合法业务导致的告警量。想要通过纯无监督方法将其区分出来,从原理上是非常困难的。
2.2 半监督方法尝试
至此,无监督方法的准确率陷入了瓶颈。但由于此前人类专家的研判步骤,我们取得了少量标注样本,于是转而尝试通过半监督方法对告警进行评估。
在实验中,我们首先尝试使用各种降维/聚类方法,对输入的原始告警载荷特征向量进行变换,从而提取其中隐含的分布规律。随后,将变换后的特征向量作为输入,利用标注样本的标签值作为输出,训练各种回归模型并进行人工验证。
得益于专家标注,上述半监督方法的准确率相比于纯无监督方法有显著提高(部分实验中接近80%)。尽管如此,模型表现仍然很不稳定。
由于训练样本太少,大多数模型都在过拟合与欠拟合之间反复摇摆,常规正则化方法几乎无效。此外,在专家研判结果的过程中,仍然发现了很多“明显的低级错误”,这表明模型多半未能深入理解告警载荷与攻击意图之间的关联。
我们在这个阶段尝试了许多参数优化方法,但最终也未能达到令人满意的实战效果。
2.3 有监督方法尝试
幸运的是,大量的实验尝试还是得到了回报:
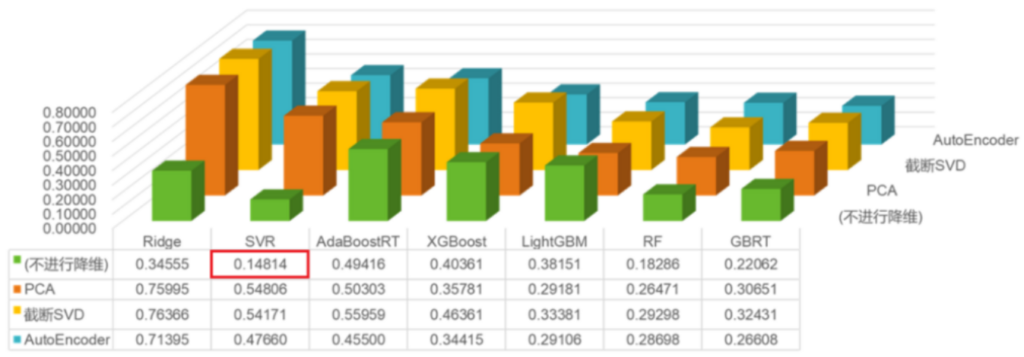
上图为某次实验中降维-回归组合方法的交叉验证损失。此次实验中,我们意外地发现:
- 降维步骤似乎并不总是有益的。除少数模型外,降维步骤甚至可能是有害的。
- 对于原始告警载荷特征向量直接使用SVR(支持向量回归)的效果压倒性地好于其它组合方法。
对于这样的实验结果,我们推测,由于原始告警中绝大多数告警信息都是低价值的,降维/聚类方法更多地学习了这些低价值数据的分布,却未能有效地区分出真实攻击导致的异常告警和业务波动导致的异常告警。因此,数据经过降维步骤后反而损失了关键信息,导致回归效果不佳。此外,我们也不得不对支持向量机模型在小样本学习问题中的优异性能表示惊叹。
由于SVR模型训练速度极快,且超参数很少(需要调整的基本只有惩罚系数C,以及RBF核参数γ),参数优化过程可以直接运行网格搜索,模型的最终研判准确率很快便稳定达到了80%以上。
三、如何取得标注样本
实际上,上述有监督方法的效果也只能算是差强人意。但进一步实验表明,模型的准确率瓶颈已经从模型本身转移到了特征提取和标注数据量上。
特征提取规则主要来自于专家编写,需要持续优化,并非一朝一夕之功成。而为了取得更多、更准确、更有代表性的标注样本,我们主要采用了以下数据来源:
3.1 已知攻击
原始告警中通常会包含很多已知攻击,主要以各类常见扫描器、各类常见蠕虫活动为主。相关告警只要编写简单的特征即可轻松匹配出来。
由于是已知攻击,这些告警可以直接确定其攻击意图。例如,非进攻性漏洞扫描器应属于高试探性、低利用性;而蠕虫活动通常应属于高试探性、高利用性等。
但由于此类告警数量非常多,直接加入训练集会造成样本失衡,需要进行一些去重和下采样后方可使用。
3.2 聚类采样+人工标注
取得高质量标注样本,最直接的方法莫过于让人类专家提供标注。但如果从所有告警中随机采样,大概率会反复抽取到相同或相似的样本,标注价值很低。
因此,可以尝试进行一些聚类采样,从而获得一些比较有代表性的样本,再进行人工标注。
下图为使用LDA(潜在狄利克雷分配)方法对特征向量进行聚类后的攻击意图向量分布(横轴为试探性,纵轴为利用性),与特征向量的整体分布相比要均匀很多:

3.3 异常检测采样+人工标注
在聚类采样中,我们发现绝大多数采样结果都不是真实攻击告警,导致最终标注样本集中正负样本严重不均衡。为了解决这个问题,我们重新翻出了前面提到的纯无监督异常检测方法,将异常检测结果交由人类专家进行标注。
实践表明,虽然异常检测方法本身难以直接用于告警评估,但在生成训练样本集的过程中仍然能够发挥作用。通过对异常检测结果的人工标注,可以大大提高模型区分真实攻击异常和业务波动异常的能力。
3.4 上线后持续反馈
在实战测试中,我们还注意到模型的迁移能力比较低下。这是有监督学习中的常见问题,预训练模型很难满足各种不同网络环境中的需要。
为此,模型需要在上线后持续接受用户反馈,将用户反馈结果不断加入到训练样本集中,从而最终实现一个实际可用的告警评估模型。
我们最终设计并实现了一个威胁推荐系统,并将其融入到企业AISecOps流程中。但本文在此不详细探讨,如有兴趣还请继续关注公众号“绿盟科技研究通讯”。
四、结果验证
我们在一个真实的网络环境中采集了一周,约2300万条告警,并从这些告警的原始载荷中提取特征,随后导入到预先训练完毕的SVR模型中。最终使用的训练数据集共有460条告警,其中有62条属于低试探性、高利用性的关键告警。
之后找出了Top10输出值最接近左上角(攻击意图向量为低试探性、高利用性)的告警,交予人类专家进行研判,结果如下(点击放大):

可见其中至少有8条告警可以确认为关键告警。
五、 后记
本系列文章【攻击意图评估】至此基本告一段落。虽然直到最后也未能完全消除低价值告警,但相比于目前的大多数告警筛选方法,其实战效果已有很大提高。
在本系列的下一篇,也是最后一篇文章中,我们会整理总结整个模型构建过程中的关键步骤和一些注意事项,以供想要动手实践的朋友们参考。
如果您发现文中描述有不当之处,还请留言指出。在此致以真诚的感谢~