摘要
当前企业安全运营实现自动化的难点在于低水平日志与高水平行为之间的语义鸿沟。本文提出了一种安全知识图谱表示方法,并提出了一种自动化的行为识别方法。
一、背景
当前企业环境面临的攻击越来越趋于隐蔽、长期性,为了更好的针对这些攻击进行有效的检测、溯源和响应,企业通常会部署大量的终端设备。安全运营人员需要通过分析这些日志来用来实现攻击检测、溯源等。利用安全知识图谱与攻击推理进行评估溯源,在相关专题文章[1,2,3]中都有介绍,其中[1]是通过挖掘日志之间的因果关系来提高威胁评估的结果,[2]利用图表示学习关联上下文提高检测与溯源的准确率,[3]主要是介绍了知识图谱在内网威胁评估中的应用。但这些工作把均是把异常日志当作攻击行为来处理。基于异常检测方法无论是在学术领域还是工业上都有了一些经典的应用如异常流量检测、UEBA(用户与实体行为分析)等。Sec2graph[4]主要是对网络流量进行建模,构建了安全对象图并利用图自编码器实现对安全对象图中的异常检测,并把异常作为可能的攻击行为进行进一步分析。Log2vec[5]通过分析终端日志的时序关系构建了异构图模型,利用图嵌入算法学习每个节点的向量表示,并利用异常检测算法检测异常行为。UNICORN[6]方法是基于终端溯源图[9]为基础提取图的概要信息,利用异常检测方法对图概要信息进行分析检测。之前的攻击推理专题中的文章[9]也是利用图异常检测算法进行攻击者威胁评估和攻击溯源。但是这些方法本质上都是基于这么一个假设:攻击行为与正常用户行为是有区别的。这些方法检测出来的结果只能是异常,异常行为与攻击行为本身有很大的语义鸿沟,同时这些异常缺少可解释性。
在安全运营的整个过程中,网络分析人员需要根据日志之间因果关系来对攻击者以及其破坏范围进行溯源分析。当前已有的技术通常是事先构建溯源图并利用之前提到的异常检测方法对溯源图进行分析,最终找到的仅仅是异常用户或是异常行为路径,这种方法的误报通常会很高。本质上当前的方法缺少一种系统日志到用户行为之间的语义映射,针对该挑战文献[8]通过安全专家构建的威胁子图作为知识图,利用图匹配算法从系统溯源图中找到相匹配的攻击。这些方法主要是事先设计一些规则库,基于这些规则检测审计日志中的相关行为[7,8]。然后,这些规则的设计严重依赖于安全专家的经验。知识图谱本身就是致力于解决这种语义鸿沟的问题,但是在安全领域知识图谱相关应用进展比较缓慢。这里借鉴了知识图谱在推荐系统上的应用方式,首先基于终端日志设计了有效的知识图谱表示形式;然后,以上下文为语义基于图表示学习方法自动的提取行为信息。
二、终端安全运营的现状
当前企业安全所面临的挑战不再是检测设备检测的准确性问题,而是涉及到更上层的攻击者的战术、技术以及过程等不同层面的分析。当前安全检测设备面临的主要问题是底层的日志与上层抽象之间的语义鸿沟问题。知识图谱的提出就是致力于解决这种语义鸿沟问题,但是在威胁检测与识别方面安全知识图谱的应用还较少,还有一段很长的路要走。
针对这种情况,本文主要探索一种可行的安全知识图谱在安全运营中的应用方法。当前安全运营面临的最大难题就是低层日志信息与高层行为之间的语义鸿沟问题。我们首先提出一种有效的知识图谱表示方法,该方法区别与当前的溯源图结构。相比较溯源图,知识图谱的表示形式能支持更复杂的异常图,同时还能包含更多实体与边的属性。然后,使用自动化的方法从审计日志中抽象出高层系统行为,并利用语义相似度聚类方法把语义上相似的行为聚合到一起,即使并不能给出合理的解释标签,其实这种聚类也是有意义的。理论上来说,相关的系统行为已经根据语义进行了聚类,安全分析人员只需要从聚类中标记有代表性的系统行为,就可以分析这些代表性系统行为来快速进行调查取证。除了能有效减少行为分析的工作量外,自动的行为抽取可以为内部或外部攻击行为模式提供前瞻性的分析。
我们把从日志信息提取行为语义的过程称为行为提取。行为提取可以完成从日志到行为的直接映射,可以看出行为提取是当前安全运营挑战的有一个有效解决方法,但它依然面临了两个挑战:事件语义的差异性和行为识别。语义差异性是指相同的日志在不同的上下文中具有不同的语义,这个语义的差异性跟自然语言中的语义差异性相似;而行为提取挑战更明显,因为终端日志的规模与高度交织性导致对其进行事件或行为划分变的异常困难。说了这么多,所谓的知识、语义在本文中是如何表示的,知识图谱技术通常是利用其实体与或边在图中的上下文来表示其语义。本文也借鉴这种表示以日志相关实体在图中的上下文表示日志的行为语义。可以通过聚合多个相关的日志来表示系统行为。基于这种表示,相似的行为可以被聚到一起。此外,可以看到通过聚类之后安全知识图谱可以提供一个关于高水平行为的边界,这种边界可以作为一种参考来通过关联多日志生成相应具有语义的行为信息。
下面场景是DARPA TC项目中的攻击场景,为了便于说明,后面的一些实例是以该场景为背景的。
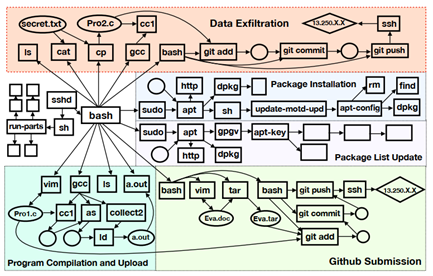
首先来简单介绍该场景。企业内部员工想利用自己的权限窃取一些敏感信息,他的工作是软件测试工程师。该员工的日常工作包括使用git同步代码,使用gcc来编译源代码,使用apt命令安全相关的测试依赖包。如果该员工想窃取敏感文件(secret.txt),为了躲避检测,他需要模拟他的日常工作行为模式。首先该员工把敏感文件复制到该员工常用的工作目录中并重命名为pro2.c文件。然后,对该文件利用gcc进行编译,当前这个文件本身不是一个有效的源文件因此编译结果是不成功的,但是这不影响。该步只是为了模拟他日常工作行为模式。最后,该把该文件上传到了github上。该企业员工试图通过这种策略来窃取敏感数据。
为了对攻击行为进行有效的因果分析,当前已有的方法主要是基于审计日志构建有效的溯源图[6]来进行分析。本质上溯源图是一个系统行为的因果关系的通用表示方式。图1 即是上面场景的溯源图。边的方法表示不同实体之间的数据流向。在攻击调查过程中,分析人员对溯源图进行分析来找到与攻击相关的信息片段。在图1的实体中,分析人员首先会根据一个确定的事件进行后向溯源来找到攻击的起源。然而,分析人员也可以利用前向溯源技术,从确定的攻击事件来确定其攻击后果。利用溯源技术,安全分析人员不仅能推断该攻击事件的根因与攻击结果,还能给出高层的抽象行为。
当前终端设备记录的日志信息不仅仅包含了攻击行为也包含了系统的正常行为。虽然溯源图提供了具有因果依赖关系的系统行为的真观表示,但对于安全分析人员调查分析来说依然是非常耗时的。从日志中提取出抽象行为对于安全分析人员来说是有效的方法。本质上来说行为信息是对系统日志的一种抽象,安全分析人员在系统行为层面的处理将会大大减少其工作量。因此从系统日志中自动化提取高水平行为信息成为智能安全运营的核心工作。
三、安全知识图谱构建
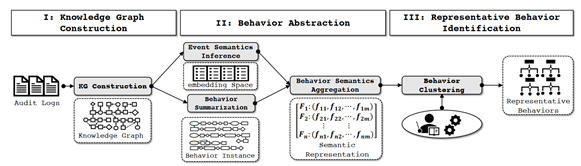
以WATSON[7]为参考该自动化攻击行为提取主要包括三个阶段,如图2所示包括知识图构建,行为提取和代表行为识别。其核心模块包含安全知识图谱、事件推理模型、行为抽象模型和行为语义聚合模型来。其中安全知识图谱是由系统日志转换成图谱的形式。事件推理模型是行为抽象过程的核心,其使用图嵌入模型来推理安全知识图谱中节点的语义,行为概要模块枚举出所有的表示行为实体的子图。最后代表行为识别是利用聚类算法对语义相似的子图进行聚类,并从每个聚类中找到最具代表性的行为。
3.1 安全知识图谱构建
为了有效地分析事件的上下文语义,需要一种能集成多种类型数据的异构数据模型。因此,本文使用了知识图谱的表示方式。相比于溯源图模型,知识图谱模型有更强的表示能力。
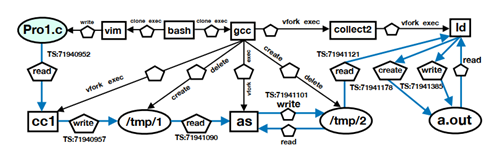
根据知识图谱[8]定义的标准,这里定义了一个基于日志的知识图谱。该安全知识图谱包含了一系列包含丰富语义的三元组,每一个三元组对应一个审计事件。如图3所示,该图显示的是上面所提到的例子中的了个子图。
3.2 行为抽象
行为抽象过程主要是由事件语义推理模型与行为概要模型。
3.2.1 事件语义推理
提取高水平行为的第一步是理解系统日志的语义。准确的语义理解是建立在合适的表示与粒度上的。已有的一些溯源分析方法是以系统事件为粒度进行分析,然后一个事件需要用三元组表示的,而三元组中不同的元素具有不同的语义。虽然,以更细粒度的元素为语义分析对象会增加计算代价,但是可以提供更准确的语义分析。同时选择有效的嵌入算法也可以从一定程度上减少计算代价。
利用图嵌入(graph embedding)[6]表示可以从审计日志的上下文信息中学习其语义表示,其中最关键的是如何把审计事件的三元组映射到同一个向量空间中,这也是嵌入模型的关键。在自然语义处理中word2vect已经是一个比较成熟的技术,基于其思想文献[6]通过分析二进制指令的上下文来表示该二进制指令的语义。在本文的场景中是否能用审计事件的上下文来表示其语义?假设现有两个审计事件三元组(cc1, read, a.c)和(cc1, read, b.c),显示a.c与b.c属于不同的审计事件,但是它们具有相同的上下文(cc1, read),这暗示着它们具有一些相似的语义信息。直观的来说就是把每个元素都转换成同一向量空间中的向量,不同元素的向量表示的距离表示其语义的相似度。例如,根据审计事件(cc1, read, a.c)和(cc1, read, b.c),我们希望a.c与b.c的向量距离尽可能的近一些。因此这里可以使用TransE模型来学习每个元素的向量表示。
嵌入模型中的嵌入空间描述的是安全知识图谱三元组中Head, Tail和Relation之间的关系。TransE模型的嵌入空间是基于以下这种理论假设:Head + Relation≈ Tail,其表示在TransE模型的嵌入空间中Head实体的向量加上Relation的向量表示等于Tail的向量表示。以(cc1, read, a.c)和(cc1, read, b.c)为例,a.c与b.c的向量表示是通过(cc1, read)表示,因此a.c与b.c向量表示是相近的。
在嵌入表示学习过程中,安全知识图谱中的每一个元素都需要进行初始。可以利用独热编码对每一个元素进行编码,然后以该向量作为训练过程的输入。训练阶段采用TransE模型本身的目标函数。
3.2.2 行为概要
行为抽象的下一步是从一个用户登录会话的行为实例进行概要分析。行为实体是一系列操作关于相关数据或是信息流的审计事件。因此,总结单一行为实例的问题可以归约为从安全知识图谱中抽取出因果相关的子图。与传统基于路径[7]的方法相比,可以在安全知识图谱中划分子图来表示行为实例。利用子图划分而不选择基于路径划分的原因是单一路径不能保留多分支数据传输的行为的完整上下文。例如,基于路径划分的方法在数据泄露行为中并不能有效的把相关行为实例关联到一起,比如程序编译与github上传可能在不同的路径中。
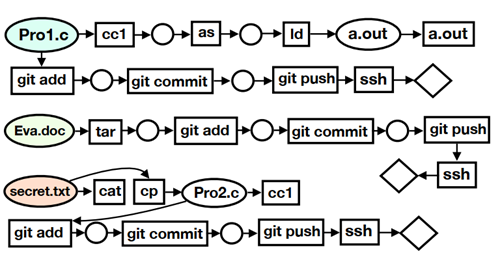
为了从安全知识图谱中抽取出描述行为实例的子图,可以采用了一种自适用的前向深度优先遍历方法。图4中给出了行为概要子图的示例。在图遍历过程中考虑了行为的时序关系,也就是后一个行为要发生在前一个行为之后。这种时间约束会过滤掉一大部分依赖关系。此外,可以看出一个系统实体的祖先通常包含了关键行为上下文,然而这种祖先节点在前向深度优先遍历中是捕获不到的,因为其属性后向依赖节点。因此,在图遍历过程中需要包含其一跳入边。
由于审计日志记录的是粗粒度的依赖关系,因此不可避免的面临依赖爆炸的问题。然而解决依赖爆炸问题并不是这里讨论的的内容。
3.3 代表行为识别
基于以上处理之后,需要基于安全知识图谱抽取出行为实例的语义信息。每个行为实例的划分都包含了一些审计事件,这些审计事件的语义信息是通过嵌入矩阵的高维向量来表示。针对行为实例的语义向量的获取,一个比较简单的方法是把该实例中所有事件的向量相加。然后,这种方法的有效性是建立在如下假设基础上的:一个行为实例所包含的所有事件对其语义的贡献都是相同的。显然这种假设在实际情况是很难满足的。
对于一个高水平任务,它可能包含了底层一系列相关操作,但是每个底层操作的重要性与必要性对于该任务来说是不同的。例如图4中的程序编译过程,用户通常不会直接编译源代码,而是先利用ls或是dir命令定位源代码。像ls和dir这种命令能表示用户的行为,但是对高层任务的语义贡献较小。因此,像这类样板操作在实际的行为表示中会给予更少的关注。关键的问题是如何自动化的给出每一个操作的相对重要度(重要性权重)。通过观察可以看到与行为不相关的事件在会话中会更普遍,因此它们在不同的行为中不为断的重复,而实际与行为相关的事件发生的频率反而较低。基于该观察,可以使用事件的频率作为事件重要度的一种度量。这里可以使用IDF(Inverse Document Frequency)来定义事件对于所有行为的重要度。为了与IDF的使用相对应,审计事件可以看成文档中的词,用户会话可以看成文档。事件的IDF计算公式表示如下:
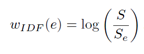
针对每个行为划分中的事件都有使用IDF计算的权重,用以表示其对于该行为语义的重要度或贡献度。
在当前场景中一个行为可以认为是一些语义相似的行为实例的集合。因此,聚类中的标签性的行为实例是具有代表性的实例(如聚类中性)。如果能够确定有效的行为标签,安全运营人员就不需要对聚类空间中所有的行为实例进行调查,而仅仅调查具有代表性的行为实例即可,这将大大提供攻击调查的自动化水平。在已知不同行为实例的向量表示后,可以使用cosine相似度来计算安们之间的语义关系:
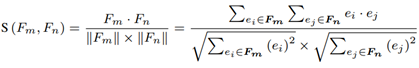
为了把具有相似语义的行为实例聚合到一起,可以采用的是凝聚层次聚类分析算法(HCA)。在对安全知识图谱进行聚类后,从每个聚类中找到一个具有代表的行为。
四、总结
当前安全知识图谱相关应用主要在威胁情报上,从知识图谱的构建,分析到推理各个阶段都有相关的应用。而在攻击识别与攻击溯源方向并没有较好的落地点。其关键还是安全知识如何来指导安全设备来进行检测与溯源,在这方面微软做了一些探索,主要还是把安全知识转化成攻击行为之间的转移概率。本文主要分析了如何利用安全知识图谱自动地提取出行为语义并对其进行分析,但是距离真正的自动化行为提取还有很长的路要走。
参考文献
[1]https://blog.nsfocus.net/attack-investigation-0907/
[2]https://mp.weixin.qq.com/s/d6fpwQlNBUlBba3spJu3wA
[3]https://blog.nsfocus.net/security-knowledge-map-helps-identify-internal-threats/
[4]Leichtnam L , Totel E , Prigent N , et al. Sec2graph: Network Attack Detection Based on Novelty Detection on Graph Structured Data[M]. 2020.
[5]Liu F , Wen Y , Zhang D , et al. Log2vec: A Heterogeneous Graph Embedding Based Approach for Detecting Cyber Threats within Enterprise[C]// the 2019 ACM SIGSAC Conference. ACM, 2019.
[6]Han X , Pasquier T , Bates A , et al. UNICORN: Runtime Provenance-Based Detector for Advanced Persistent Threats[J]. 2020.
[7]Milajerdi S M , Eshete B , Gjomemo R , et al. POIROT: Aligning Attack Behavior with Kernel Audit Records for Cyber Threat Hunting[J]. 2019.
[8]Milajerdi S M , Gjomemo R , Eshete B , et al. HOLMES: Real-time APT Detection through Correlation of Suspicious Information Flows[J]. 2018.
[9]攻击溯源-基于因果关系的攻击溯源图构建技术https://mp.weixin.qq.com/s/ofP4j2TEfNoCYqrLhMsvZA
[10]Zeng J , Zheng L C , Chen Y , et al. WATSON: Abstracting Behaviors from Audit Logs via Aggregation of Contextual Semantics[C]// Network and Distributed System Security Symposium. 2021.
[11]Michael Färber, Frederic Bartscherer, Carsten Menne, and Achim Rettinger. Linked data quality of dbpedia, freebase, opencyc, wikidata, and yago. Semantic Web, 9(1):77–129, 2018.
[12]Zheng Leong Chua, Shiqi Shen, Prateek Saxena, and Zhenkai Liang. Neural nets can learn function type signatures from binaries. In USENIX Security Symposium, 2017
[13]Hassan W U, Guo S, Li D, et al. NoDoze: Combatting Threat Alert Fatigue with Automated Provenance Triage[C]. NDSS, 2019.
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。