本届RSA大会“合规与风险治理”专题中大部分聚焦于网络安全风险的量化以及相关的实践案例,如Palo Alto Networks公司的Rich Howard 演讲《Superforecasting II: Risk Assessment Prognostication in the 21st century》,阐述了如何将半定量的风险评估转变为更深入的准确量化风险评估;《Math is Hard: Compliance to Continuous Risk Management》中分享构建量化风险管理的整个流程;另外在《NIST Cybersecurity Framework and PCI DSS》中介绍了PCI-DSS标准在CSF框架中的实践情况,指出标准至CSF的复杂映射关系的问题。
目前在合规与风险治理领域,面临的主要问题是非结构化和半结构化文档无法高效转换为可量化数据,导致风险管理过程缺乏对管理信息的有效评估。针对该问题,微软高级风险经理Bugra Karabey提出将机器学习工具引入到网络安全风险管理中,总体思路是使用自然语言处理(NLP)实现对非结构化文档的解析,抽取文档关键信息,同时结合数据降维算法进行风险识别。
Bugra Karabey首先指出当前网络安全风险管理的现状:
1)基于专家视角的主观风险评估,难以量化
2)有限数据驱动的风险评估方法,评估结果缺乏全面性
3)更多以定性角度而不是定量角度进行分析
4)采用五分制对风险影响程度和发生可能性进行量化
5)聚焦于识别已知风险
同时Bugra Karabey指出机器学习在网络安全领域已经十分常见:日志、流量模式分析,异常检测,行为分析,但是在识别评估潜在风险主题、风险模式以及关系中,机器学习仍然有很大的应用空间。例如:
- 处理富文本数据集(安全策略异常、内部&外部事故、风险合规安全事件);
- 自然语言驱动的风险识别;
- 管理层对风险的认知更多为处理后的信息,而非技术层面细节。
并从以下三个场景阐述机器学习如何应用到网络安全风险管理当中
主题建模(Topic Modeling)识别高风险主题
主题建模是一种发现文档摘要的统计模型,采用无监督学习从大量文档中发现代表文档主题的一组单词。常用的主题模型有:潜在语义分析(LSA)和隐狄利克雷分配模型(LDA)。采用主题建模发现高风险事件的流程如下图所示:
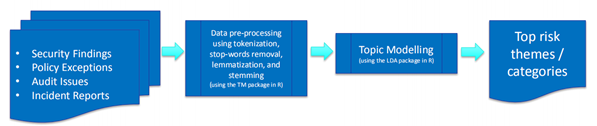
- 收集网络安全相关的富格式文档,包括安全事件、策略异常、审计时间、事故报告等;
- 数据预处理,包括分词、词性还原、词干提取等;
- 主题建模(LDA/LSA);
- 识别高风险主题/类别。
其中在流程2和流程3中,Bugra Karabey建议使用机器学习工具进行实践落地。流程2中的自然语言处理可以R语言中的文本挖掘包(TM package),流程3中的主题建模同样可以使用R语言中的LDA包(LDA package)实现。
通过以上主题建模实现文档的摘要提取,获取相关风险要素(捏造数据):
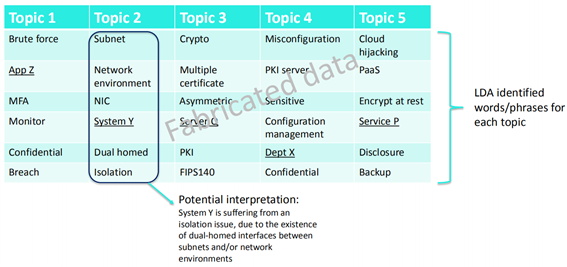
自然语言处理(NLP)识别潜在风险
Bugra Karabey采用两种方法进行潜在风险种类识别:词嵌入向量(Word Embeddings)和长时短记忆网络(LSTM-RNNs)。
词嵌入向量(Word Embeddings)
Word Embedding将一个单词转换成固定长度的向量表示,通过训练聚集共性单词。工作流程如下:
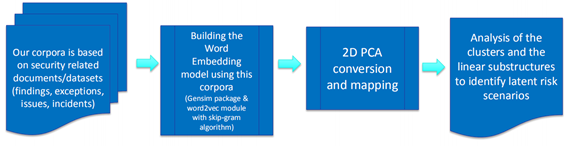
- 创建安全相关文档/数据集全集(事件、异常、事故);
- 使用全集数据建立词嵌入向量模型;
- 两维主成分分析(PCA)转换映射;
- 分析聚类和线性子结构从而识别潜在风险
其中在流程2构建词嵌入向量模型中可以使用Gensim包和word2vec的skip-gram算法。
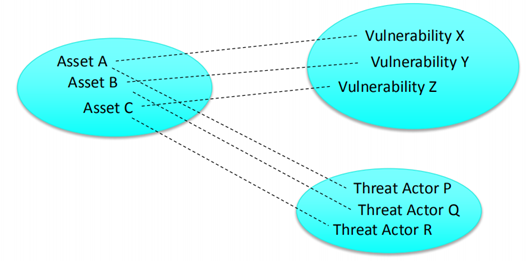
以资产为例,通过分析词嵌入向量空间(降低至二维或三维),识别资产—威胁、资产—脆弱性等关系:
长时短记忆网络(LSTM-RNNs)
LSTM-RNN是一种特殊RNN类型,解决RNN的长时依赖的问题。其主要思想是:门控单元以及线性连接的引入,使得RNN有选择性地保存和输出历史信息。LSTM应用于网络安全风险识别流程如下所示:
- 收集安全事件数据集;
- 利用全集建立LSTM-RNN模型;
- 通过“种子”短语作为模型输入参数;
- 分析模型自动生成的内容,识别潜在风险主题
其中在流程2建立LSTM-RNN模型中可使用Keras,后端采用tensorflow或CNTK。
通过向建立好的模型中输入短语,生成文本进行风险分析,样例如下:

主成分分析(PCA)聚类识别风险管理事故
主成分分析:一种数据降维算法,主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。该算法只保留包含绝大部分方差维度的特征,忽略方差近乎为零的特征维度,实现对数据维度的降低。
对于网络安全事故中的风险识别的工作流程如下:

- 收集安全事故数据集;
- 使用主成分分析将数据降低至三维;
- 分析聚类结果识别风险模式。
其中在流程2可以使用R语言中的PCA和ggplot2包。示例如下图所示,事故聚类为三个聚簇,分析聚簇内的特定模式发现不同事故之间内在风险根源。

总结及展望
美国采用FISMA方案作为政府治理体系的核心。FISMA1.0至FISMA2.0,工作重心转移到实时监控并且在总体设计中整合网络安全,而不是停留在事后的追悔。FISMA2.0的关注点从部门以及机构开发静态、基于文件的合规报告到持续的、实时监控联邦网络。为了实现FSIMA2.0近乎实时的监控,NIST制定了网络安全框架(CSF)并结合安全内容自动化协议(SCAP)以及开源安全控制评估语言(OSCAL)实现不同安全标准下的系统安全技术、管理维度的自动化监测响应。
参考网络安全框架(CSF)和建模语言,绿盟科技构建了关键信息基础设施治理体系。该体系以威胁知识图谱为核心,将结构化威胁数据(安全日志、流量等)映射为图谱中的知识本体,从而利用图谱中的专家知识实现威胁分析预警;同时也将管理维度的数据,如信息安全等级保护中的安全条例转换为知识本体,结合知识图谱中的推理关系实现技术维度信息与管理维度信息的联通。
在该治理体系下,需要持续输入技术、管理维度数据才能实现风险的实时监控。但由于非结构化或半结构化安全文档(审计报告、安全事件报告等)无法高效自动化解析为机器可读的信息,该环节成为实现体系闭环的最后一个障碍。Bugra Karabey提出将自然语言处理(NLP)引入到网络安全风险管理中,探索性地提出根据文档主题识别风险类型以及根据聚类后的文档集分析风险模式、关系,对关键信息基础设施治理体系闭环具有重要价值。