还在自己写爬虫吗?省省力吧!今天介绍一款爬虫利器——火车采集器。它是一款互联网数据抓取、处理、分析和挖掘软件。可以灵活迅速地抓取网页上的信息,并通过内置处理功能,准确抓取出所需数据。
项目背景:支持某项目对互联网提供的大量的具有特征信息的内容进行爬取,并对信息进行分析研究。收集提供了220左右个网站的网址,每个网址按照16个关键字进行信息检索和信息爬取。
第一步那就是要爬取信息了,自己写爬虫?还是别了吧,有个工具叫火车采集器(原来叫火车头采集器)在这个前提下能满足我们需求了哦,下面就简单介绍下如何使用,方便后来的同学有类似需求提供一个解决问题的工具。
火车采集器的采集流程

1. 创建分组和任务
- 可以把将要采集的网站按网站名称创建分组名。
- 在改分组下创建按关键字命名的任务名。
2. 设置采集源
此步最为关键,我们用http://www.bjkw.gov.cn(北京市科学技术委员会)这个网站为例。
一般网站的页面结构分为:
| 页面结构名称 | 说明 |
| 网站首页 | 该网站综合信息及重要信息展示的集合 |
| 栏目页(列表页/栏目主页) | 该栏目下所有的信息集合 |
| 单页 | 单独的页面,类似于企业简介,联系我们这类页面 |
| 内容页 | 消息/新闻内容的正文页面 |
| 搜索页 | 大至门户小至个人博客,一般都会提供该站的内容检索功能 |
| 标签页(关键字列表页) | 类似搜索页 |
| 功能页面 | 比如登录页、信息提交页面等 |
我们一般设置的采集入口网址为,栏目页、搜索页、标签页具有信息集合的页面。
例如我们要在“北京科技委”这个网站上按关键字搜索出来含关键字“智慧城市”所有信息。
- 输入关键字跳转至搜索结果页面地址栏中的URL如下:
http://www.bjkw.gov.cn/jrobot/search.do?webid=1&pg=12&p=1&tpl=&category=&q=智慧城市&pos=&od=&date=&date=
- 同时该网站还提供高级检索功能我们仅搜索一年内的数据,URL如下:
http://www.bjkw.gov.cn/jrobot/search.do?webid=1&pg=12&p=1&tpl=&category=&q=智慧城市&pos=&od=&date=20170523&date=20180523
URL中不难看出一个是开始时间一个是结束时间我们采用第二个地址做为入口采集地址
- PS:搜索结果好多页怎么办?
我们随便点一页查看URL的变化
http://www.bjkw.gov.cn/jrobot/search.do?webid=1&pg=12&p=4&tpl=&category=&q=智慧城市&pos=&od=&date=20170523&date=20180523
参数中的p=4就是我们的页码,如果没有特殊情况,至此入口地址准备一切就绪了。
配置如下图:
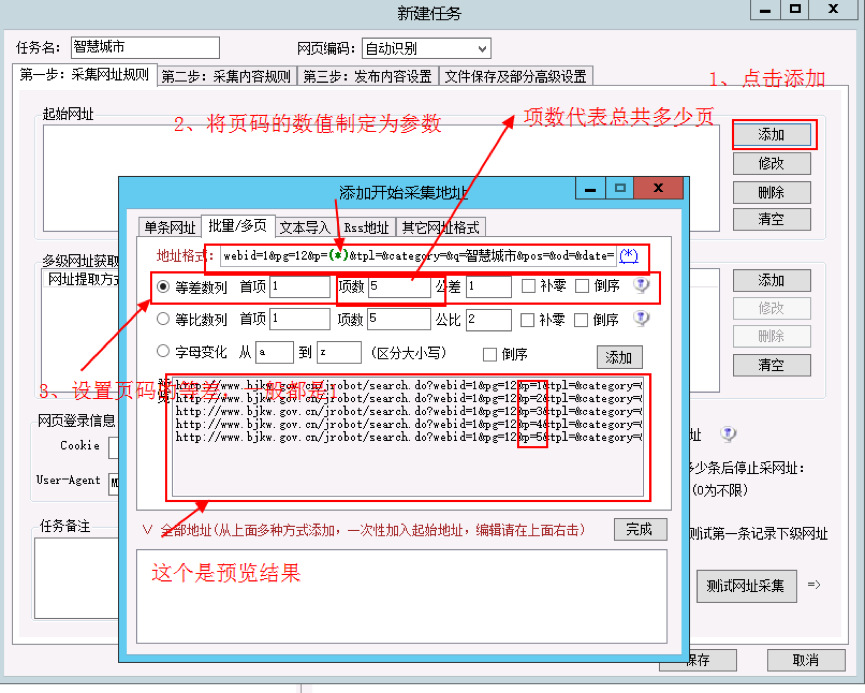
配置完记得点击【添加】->【完成】。
注意:
- 这里的配置还支持单条网址、文本导入、RSS地址、其他网址格式,根据自己的需要自行设置即可,此文不再说明。
- 入口地址可以同时添加多个。
3. 设置采集地址
采集源设置成功后,我们需要设置在源中需要采集的地址。分析该网站的展示形式不难观察出页面中已经提供了制定信息的地址,如下图红框标识
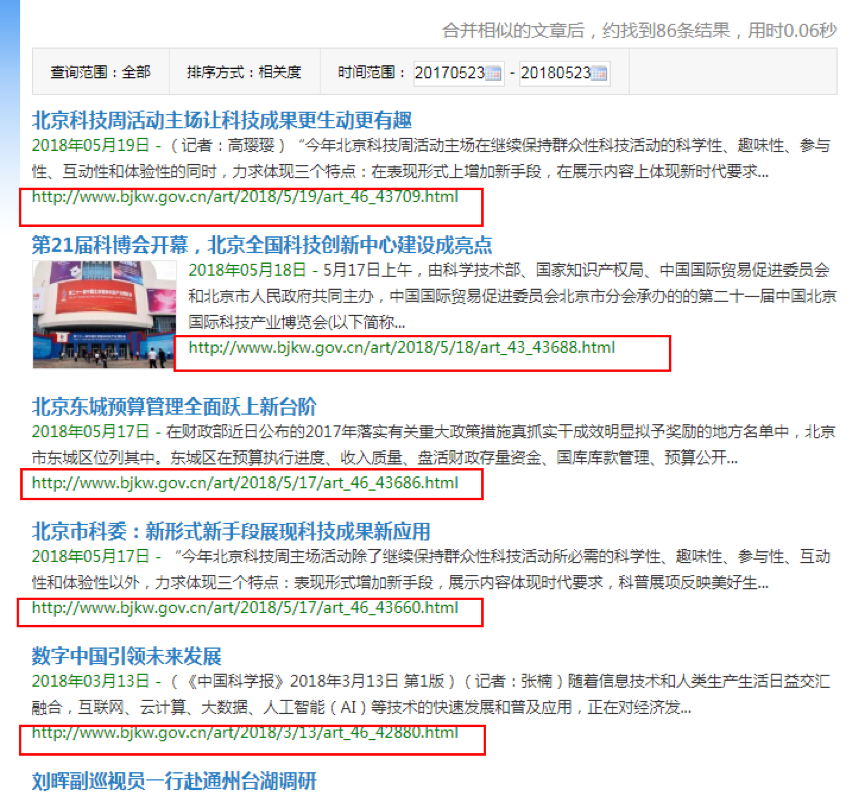
怎么提取出来呢,我们需要查看网页的源码,以chrome举例如下图,我们将对应的div标签中所有内容复制(右键Edit as HTML)。

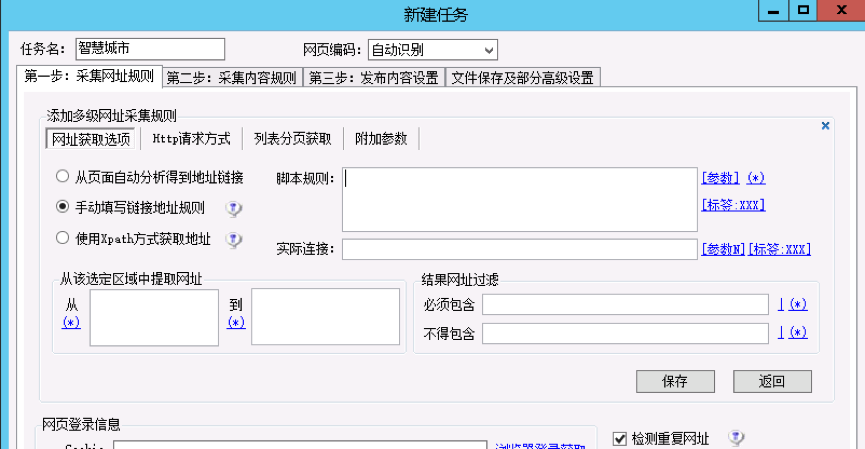
回到操作界面点击【添加】

因为自动分析地址,该源页面上的一堆不是我们想要的地址,所有我们选择手动填写链接规则,当然也支持Xpath的方式,此步可按照自己的需求选择。
将我们在chrome中复制出来的a标签的内容粘贴至脚本规则中,将其中内容会变化的全部设置成参数(选中内容点击右侧的“参数”链接)。
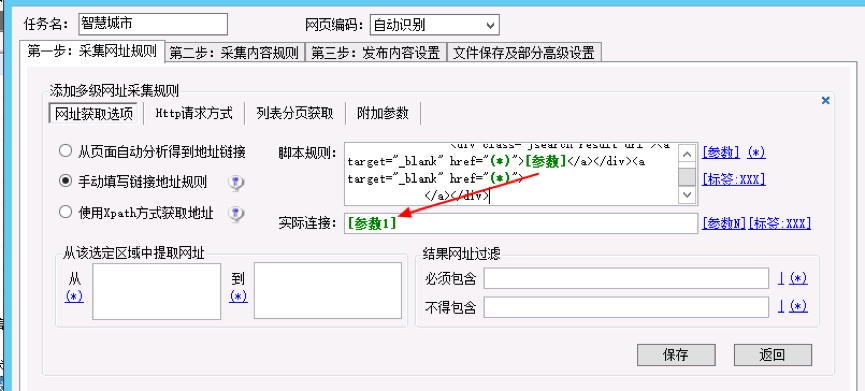
注意,脚本规则中的参数没有加序号,需要我们人工判断是第几个参数,实际链接中填写参数要加上序号。然后点击【保存】即可。测试下我们的采集网址。

这是我们想要的~~
注意:
- 该项配置还支持多种方法选取实际链接地址,需要根据需求及该页面上的数据结构自己试验实际的链接地址。
- 该配置支持修改http请求方式、Cookie信息、user-agent等信息配置。
- 脚本规则获取的源码必须和网页源代码的代码结构一模一样,否则可能导致采集实际链接不正确,chrome只是演示获取源码部分的一种方式。
- 此处需要对页面的代码结构进行认真分析(分析代码过程该文档暂时忽略)
4. 设置采集内容规则
如果你经历了第一步的操作那么接下来的这一步就会很easy,内容都是从网页的源码中采集,我们已经配置好了源码采集的地址,这一步就是从源码中提取出来我们想要的内容,简单的说就是字符串的提取,字符串的替换。

这里的操作支持正则表达式提取、支持图片的下载、支持提取内容的过滤等等,就是界面不太友好,什么什么的操作还要自己多试几次才能搞清楚。
此步就不做多的介绍了,作为大牛的你是不是开始嫌弃我说的都是废话了~~~
5. 发布内容设置
以上的操作我们都做完了,采集下来的内容到哪儿了呢?能不能直接入库呢?答案是可以的!
采集下来的内容可以直接写出对应的sql直接导入到我们的数据库中,数据库支持access、mysql、sqlserver、oracle,还支持生产文件形式word、excel、text、html格式

设置任务的时候我们还可以设置一些附加的条件如下图,其他功能大家可自行发掘。

6. 任务运行
直接上图,记得一定要把任务后面三步对应的勾勾上,要不程序不会执行那一步的。
问答:
问:已经跑完的任务,在第二天跑的时候,会从头开始全新执行吗?
答:不会的,跑下来的数据系统按照你的配置记录到了本地的access数据中,再次运行的时候只追加了。其实还有另外一个问题,即使我们第三步发布内容的时候不做配置,我们仅配置和运行前两步,数据也已经存到我们本地了。按操作打开目录你会发现有一个SpiderResult.mdb的文件。Windows如果装了access直接双击就能打开了。里面记录的就是爬虫运行后的结果数据。在此也建议不直接存入我们的数据库,即第三步不做任何操作仅运行前两步,通过对SpiderResult.mdb中的数据处理后在作出进一步处理。因为小编运行的时候发现直接跑出来的结果不是完全正确的,可能和网站源有直接关系。最好先对数据检验处理一下。
问:所有网站都能爬吗?
答:有做反爬的,也能爬,但是需要做好多规则。
问:安全吗?
答:这就是模拟网站的正常访问,是对人家网站的ddos哦,频率别太快特别是除了爬别人内容外,你还爬别人的图片,人家会有可能把你IP或者你的IP段封了不让你访问。