一、背景介绍
当前社会信息化高速发展,网络信息共享加速互通,数据呈现出规模大、流传快、类型多以及价值密度低的特点。人们可以很容易地对各类数据实现采集、发布、存储与分析,然而一旦带有敏感信息的数据被攻击者获取将会造成个人隐私的严重泄漏;所以在发布数据前,必须通过适当的隐私保护手段来隐藏敏感信息,从而达到能够发布和分析同时又保障隐私信息安全性的目的。
然而,实际中大部分数据脱敏方法(如假名化、字符屏蔽)仍存在隐私风险,经过这些脱敏处理后的数据经过发布后可能遭受一系列的攻击,包括重标识攻击、背景知识攻击、链接攻击以及隐私推理攻击。为了抵抗以上一些攻击,K-匿名、等价匿名是较为常用的匿名处理方法,对其进行合理应用能够在数据分析时减少安全隐患风险问题发生。其中K-匿名算法具有实用性,属于新型算法的一种,为了抵抗常见的链接攻击,比较科学的数据发布脱敏都会采用K-匿名的手段对数据进行处理,但该方法对敏感属性值的分布未做任何具体限制,因此就会存在背景知识攻击以及同质攻击。为了得到风险小且信息损失量小的发布数据集,需在发布脱敏数据集之前应对其进行评估,若评估后的脱敏数据集质量达到用户对数据价值要求同时攻击者很难窃取敏感信息,那么就可以发布。本文讨论的风险评估算法也是基于匿名化处理数据的风险评估,也适用于其他脱敏算法。
二、K匿名相关知识简介
根据发布数据集的内容不同,数据集存在的风险也不同;如何去量化的评估数据集存在的风险,就应该先对数据的敏感级别进行一个合理的划分。行业已经有相关的规范,如《信息安全技术个人信息去标识化效果分级评估规范》(征求意见稿)中对数据敏感级别定义了如下的划分规则:
- 个人信息标识度分级

结构化数据以表的形式表示,每一行表示一条记录(record),每一列表示一个属性(attribute)。每一个记录与一个特定用户/个体关联。这些属性可以分为四类:标识符(explicitidentifiers attribute):可以直接确定一个个体。如:身份证号,姓名等单个属性值。准标识符(Quasi-identiflerattribute,QID):可以和外部表连接来识别个体的最小属性集。如Fig1中的 { 年龄,性别,邮编 }组合。敏感属性(Sensitiveattribute):用户不希望被人知道的数据。如:电话号码、所患疾病等。可以认为数据表中有价值的数据除了标识符和准标识符之外都是敏感数据。非敏感属性(Non-sensitiveattribute):可以直接公开,无任何危险的数据,如序号。等价组(等价类):所有准标识符对应的值相同的数据划分到一个组。基于以上的概念定义,基于K-匿名的脱敏处理就是要保证准标识符集的非唯一性,即等价组中最小的个数必须大于等于K。
- 安全隐患样例

图2右图是一张某医院收集的病人信息,其中已经抹去了姓名、身份证号等信息)。但是,直接发布这样简单处理的数据并不安全。因为数据接收者(recipient)可能知道其他个人信息,比如上面表一是一张投票信息表。那么recipient就可以通过比对Birthdate、Sex 和 Zipcode的值得知 Andre 患有Flu。这种通过某些属性与外部表连接的攻击称为链接攻击。
- K-匿名样例

K-匿名思想十分朴素。它首先做了如下假设:准标识符假设:数据持有者可以识别出其所持有数据表中可能出现在外部数据中的属性,因此其可以准确的识别出准标识符集合。K-匿名要求同一个准标识符至少要有k条记录。因此观察者无法通过准标识符进行记录连接。如图3(*号遮蔽只是一种方法)。
- 等价组
把拥有相同准标识符的所有记录称为一个等价类(equivalenceclass)。K-匿名即是要求同一等价类中的记录不少于K条。把等价类的大小组成的集合称为频率集(frequencyfet)。如图4就是一个按K=3处理后的数据集,{1,2,3},{4,5,6},{7,8,9}分别为一个等价组。等价组是一个多重集(multiset),即其中可以有相同的元素。频率集应该也是多重集。K-匿名使得观察者无法以高于1/K的置信度通过准标识符来识别用户。

三、隐私的定义与度量
隐私,就是个人、机构等实体不愿意被外部世界知晓的信息。在具体应用中,隐私即为数据所有者不愿意被披露的敏感信息,包括敏感数据以及数据所表征的特性。我们常说的个人信息安全,就是保护用户的隐私安全。个人敏感数据通常也称隐私数据,这些数据包括用户姓名、电话和身份证号码及银行卡号或其他一些私人信息。这些信息只要稍微被泄露出去,往往会紧密地关联到人们的日常生活,或多或少会造成一些损失,然而要是用户数据信息影响到用户的信用问题,则又会波及用户在财务或者法律方面的一些问题,造成严重损失。随着现代化大数据的应用越来越广泛,应用到该技术的相关工作单位也同样给予了大数据足够的重视度,为的就是能够实现双方利益的共赢,互惠互利。
数据安全与隐私相关技术受到的重视程度越来越高,因此聚焦“敏感数据”,创新实践“零信任”安全理念,围绕数据产生、传输、存储、使用、共享、销毁外加数据管理的全生命周期,并结合数据安全相关的法律法规《国家安全法》《网络安全法》以及即将出台的《数据安全法》《个人信息保护法》,构建由内到外主动式纵深防御体系尤为重要;其中每个周期中核心技术能力诉求如图5所示。

一般的,从隐私所有者的角度而言,隐私可以分为两类:个体隐私(Individual Privacy)任何可以确认特定个人或可以确认个人相关,但个人不愿意被暴露的信息,都叫做个人隐私,如个人身份证号码、就诊号。共同隐私(Corporate Privacy)共同隐私不仅包含个人的隐私,还包含所有个体共同表现出,但不愿意被暴露的信息。如公司员工的平均薪资、薪资分布等信息,再如两个人之间的关系信息。隐私的度量与量化表示数据隐私的保护效果是通过攻击者披露隐私的多寡来侧面反映的。现有的隐私度量都可以统一用“披露风险”(Disclosure Risk)来描述。披露分险表示攻击者根据所发布的数据和其他背景知识(Background Knowledge),可能披露隐私的概率。通常,关于隐私数据的背景知识越多,披露风险就越大。若s表示敏感数据,事件Sk表示“攻击者在背景知识K的帮助下披露敏感数据s”,则披露风险r(s,K)表示为
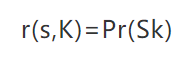
对数据集而言,若数据集所有者最终发布数据集D的所有敏感数据的披露风险都小于阈值a,aϵ[0,1],则称该数据集的披露风险为a。
四、数据风险评估方案
基于前文所述,为了防止发布数据的隐私泄露事件,所以对发布数据都会进行脱敏处理,但脱敏后仍会遭受各种攻击。被脱敏处理后的数据,主要容易遭受的攻击模型主要有三种:检察官攻击,记者攻击,营销者攻击。检察官攻击模型窃取隐私的前提是知道目标数据就在待挖掘的数据集中;记者攻击模型不知道目标数据是否在待挖掘的数据集中,但知道目标数据在公开数据集中,其中待挖掘数据集和公开数据集有两种结构关系:重叠和包含;营销者攻击模型不考虑攻击单独的数据记录,其攻击对象是大量的元组,因此不必计算处于风险中的记录数和最大风险(详细描述请参照《大数据下的隐私攻防:数据脱敏后的隐私攻击与风险评估》)。本文的隐私风险评估方案是基于k匿名后的数据进行评估;于此同时,k匿名技术也是一种比较科学的脱敏方式,因此也适用于其他脱敏处理的结果集。对以上三种模型的风险计算逻辑与公式如下:
4.1 抽样数据集和原始发布数据集一样(即同表数据集分析)
经检察官攻击模型、记者攻击模型和营销者攻击模型攻击后存在风险的记录比例,即存在风险的数据条数率:
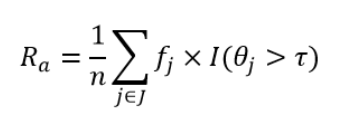
其中,n为记录的个数,fj为第j个等价类的大小,θj=1/fj ,当θj大于阈值τ时,函数I的值为1;当θj小于等于阈值τ时,函数I的值为0。最大风险Rmax和平均风险Ravg为:
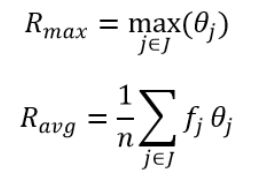
4.2 抽样数据集和原始数据集不相同(即联合攻击)
4.2.1 经记者攻击模型攻击后存在风险的记录比例jRa:

其中,Fj为取样数据集里面每个等价类的记录与原数据集的记录相同的记录数。最大风险jRmax和平均风险jRavg为:
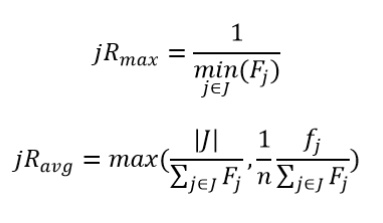
4.2.2 经营销者攻击模型攻击后存在平均风险mRavg:
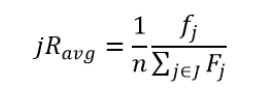
实现了三种值供用户选择,分别为0.05(高度侵犯隐私)、0.075(中度侵犯隐私)、0.1(低度侵犯隐私),从而可以灵活地适应各种用户的隐私需求。
五、总结
本文的评估方案是基于链接攻击模型进行分析与指标设计的,其能够有效地评估数据重标识风险,但未考虑到敏感数据的分布问题,所以仍然存在同质攻击、背景攻击等危险;同时,随着机器学习的越来越智能,也会存在语义的分析;因此后续应该结合机器学习相关知识,做合规检测和脱敏化,防止语义分析攻击等。此外,脱敏后数据的可用性的度量也是一个至关重要的点,所以也应该考虑对脱敏数据信息损失度做一个定量的评估。
参考文献
[1] 信息安全技术个人信息去标识化效果分级评估规范[S]. 2021, 04.
[2] 中华人民共和国数据安全法(草案)[S]. 2020, 06.
[3] 杨义先,李小勇,石瑞生等. 大数据安全与隐私保护[M]. 2019, 05.
[4] 孟雪. 保留敏感数据统计特征的数据脱敏系统的研究与实现[D]. 西安电子科技大学, 2020.
[5] 华为&工信. 数据安全白皮书[OL].
[6] Alshammari M , Simpson A .Towards an Effective Privacy Impact and Risk Assessment Methodology: RiskAssessment[C]// International Conference on Trust & Privacy in DigitalBusiness. Springer, Cham, 2018.
[7] 陈磊. 大数据下的隐私攻防:数据脱敏后的隐私攻击与风险评估[OL]. 绿盟科技研究通讯. 2020,03.
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。