一、摘要
图模型因其强大的表示能力在现实中有着广泛的应用,如欺诈检测、生物医学、社交网络等。由于图结构不具有平移不变性,每一个节点的上下文结构有较大的差异,因此传统的深度学习模型就无法直接应用到图模型上。图神经网络(GNN)可以从图数据中提取相应特征,在尽可能的保证图结构特征的情况下把图数据映射到向量空间中。随着GNN的应用越来越广泛,其安全性也越来越被关注。比如说在信用评分系统中,欺诈者可以伪造与几个高信用客户的联系以逃避欺诈检测模型;垃圾邮件发送者可以轻松地创建虚假的关注者,向社交网络添加错误的信息,以增加推荐和传播重大新闻的机会,或是操控在线评论和产品网站。
GNN模型本身的安全性可粗略的分为两大块:对抗样本与后门攻击。本文针对GNN的后门攻击进行了介绍。
后门(backdoor)在传统软件中比较常见。所谓的后门就是一个隐藏的,不易被发现的一个通道,在某些特殊情况下,这个通道就会显露出来。关于深度学习模型中的后门攻击已有一些研究工作,而关于图模型的后门攻击与防御的相关研究工作还刚起步。GNN模型的后门攻击是希望通过某种方式在GNN模型中埋藏后门,埋藏好的后门通过攻击者预先设定的触发器(trigger)激活。后门未被激活时,被攻击的GNN模型具有和正常GNN模型相同的表现,而当GNN模型中后门被攻击者通过触发器激活时,GNN模型的输出将变成攻击者预期的结果,以此来达到恶意目的。因为图模型本身的特性,通常GNN的训练时间较长,很多下游的应用都会直接使用预训练的GNN模型。这也给后门攻击提供了更多的机会。
二、GNN后门攻击概述
为了详细说明,下面具体的介绍一下图神经网络的后门攻击。
- GNN后门攻击
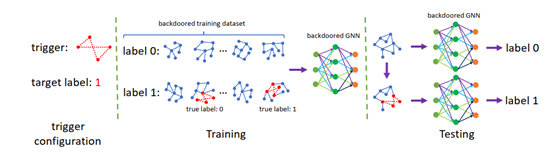
GNN后门攻击是希望在GNN模型的训练过程中或是在迁移过程中在模型中埋入后门,埋藏好后门的模型通过攻击者预先设定的触发器激活。在后门未被激活时,被攻击的GNN模型具有和正常模型类似的表现。而当模型中埋藏的后门被攻击者激活时,模型的输出攻击者预期的结果以达到恶意的目的。GNN后门攻击的过程如图1所示。GNN后门攻击可以发生在训练过程非完全受控的场景中,如使用第三方数据集、使用第三方平台进行训练、直接调用第三方模型等,因此会对GNN模型的安全性造成了巨大的威胁。
后门攻击主要包括三个主要过程:触发器配置、训练过程和测试过程。通常GNN的后门触发器是一个子图,假定该子图包含有t个节点。触发器配置就是以某种方式把触发器子图映射到图数据中,触发器的选择与映射是GNN后门攻击的关键。在训练过程中,攻击者向训练数据中注入触发器(子图),使得训练结果按攻击者的要求进行改变,最后学习得到了个带有后门的GNN模型。该模型可以被占应用到了下游应用中,在没有激活触发器的情况下模型输出正常结果,如果触发器被激活的话将按攻击者的意愿输出结果。
2. GNN后门攻击的形式化描述
GNN后门攻击主要有两个关键部分:触发器与后门模型。对于一个预训练GNN模型,攻击者的目的是通过技术手段对GNN模型
进行修改,在下游应用中针对带有触发器的图数据能按攻击者的意图输出攻击者想要的结果,而对于没有触发器的数据则正常输出结果。因此,GNN后门攻击的目标函数可写成如下形式:
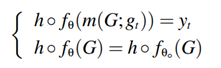

三、已有的GNN后门攻击方法
本节针对已有GNN后门攻击的研究工作进行了介绍。当前针对GNN后门的研究工作还较少,主要有三个工作。文献[1]要报深度学习的后门攻击方法提出了一种基于子图的GNN后门攻击。文献[2]系统的阐述了GNN后门攻击的特点,提出了一种可以根据应用动态调成的GNN后门攻击方法。文献[3]从GNN可解释性的角度探索了不同触发器对GNN后门攻击的影响。下面分别详细介绍这三个工作。
- 基于子图的GNN后门攻击
文献[1]主要是提出了一种基于子图的GNN后门攻击,针对图分类任务。针对GNN触发器的特点,提出了一种描述触发器的子图模式。触发器的子图模式由四种参数描述:触发器大小、触发器稠密度、触发器合成方法、投毒密度。触发器大小与稠密度是指表示触发器的子图的节点与边数目与该图的稠密度。触发器的合成方法是指给定节点与边数、图的稠密度生成图的方法。投毒密度是指触发器占训练数据的大小。
整个攻击过程如图1所示。其中关键是触发器的计算过程,由于构建一个完全子图作为触发器很容易被检测到,该文献采用随机采样的方法生成触发器子图。
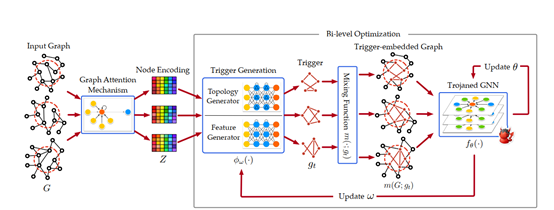
2. GTA 攻击
文献[1]提出的GNN后门攻击方法只能针对图分类任务,无法应用到其他应用中,同时触发器是固定的无法按要求进行动态的调整。针对这些问题,文献[2]提出了一种更有效的GNN后门攻击方法-GTA。GTA的触发器是一个特殊的子图,该子图包含了拓扑结构与离散特征。GTA方法可以根据输入动态调整触发器。原有的深度学习后门攻击的触发器是固定的无法根据输入动态调整,这就导致触发器无法适用于所有输入数据。触发器动态调整可以大大提高后门攻击的有效性。假定攻击者没有关于下游模型或是微调策略的知识,GTA优化了后门GNN的中间表示,可以面对不同的系统设计。GTA是一个图攻击框架,可以针对不同的应用场景如(图分类,节点分类)等,其对这些应用会产生严重的威胁。该工作如图2所示。
3. 基于可解释的GNN后门攻击
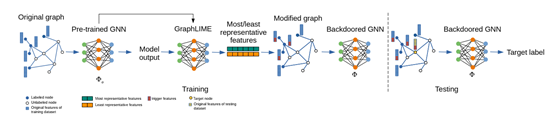
针对GNN的后门攻击为GNN的应用带来的巨大的安全性上的挑战。其实GNN后门攻击中触发器的选择是关键。文献[3]通过GNN可解释来探索触发器的最优选择策略。并针对图分类与节点分类两种应用进行了探索分析。
图3 为GNN后门攻击在图分类上的应用,采用的解释器是GNNExplainer[4]。使用GNNExplainer分析每个触发器位置对图分类的影响,并基于可解释器的影响评分提出有一种有效的触发器生成策略。

图4 为GNN后门攻击在节点分类上的应用,由于GNNExplainer无法直接应用到节点分类上,本文还提出了一种新的解释方法GraphLIME。基于GraphLIM分析了GNN节点分类的结果,计算其中n个最具代表的特征,通过调整这些特征来找到相应的触发器。
四、GNN后门攻击的防御
通常针对深度学习系统的攻击有两种防御方法:经验防御与验证防御。经验防御通常是为针对特定的攻击设计的,随着攻击手段的变化防御方法也可更新,这将会导致攻击者与防御之间的竟逐。例如,对于图像识别领域的后门攻击来说,文献[5]提出的动态后门攻击可以很容易的绕过当前的经验防御措施。因此,GNN后门攻击的防御主要是验证防御。
- 图对抗训练
对抗训练是增强神经网络鲁棒性的重要方式。在对抗训练的过程中,训练数据会被混合一些微小的扰动,使神经网络适用这种改变,从而提高GNN对输入数据的鲁棒性。可以采用如下策略来提高GNN模型的鲁棒性,从而提高GNN后门攻击的代价。

该公式的详情参考文献[6]。
2. 图纯化技术
图纯化防御方法主要侧重于防御GNN的中毒攻击,同时也可以用于提高GNN对后门攻击的防御能力。由于GNN后门是需要在模型中插入触发器子图,图纯化方法可以提高GNN模型就对扰动数据的能力。通过这种方法,可以在干净的图数据上训练GNN模型,从而避免GNN后门攻击的触发器激活。文献[7]提出了一种基于攻击方法的两个经验观察结果的提纯方法:(1)攻击者通常更喜欢添加边而不是去除边或修改特征;(2)攻击者倾向于连接不同的节点。结果,他们提出了一种防御方法,即通过消除两个末端节点的Jaccard相似度较小的边。因为这两个节点是不同的,并且实际上不可能连接在一起,所以它们之间的边可能是对抗性的。
3. 随机子采样
随机平滑是当前建立强健机器学习模型的有效方法。由于图数据是一个二元数据,随机平滑方法也可以称为随机子采样[8]。下面简单介绍随机子采样方法。假定有一个s维的输入x和一个分类器h。随机子采样方法是对于输入x随机保留一部分特征并把其他特征置0。因为这种子采样是随机的,其分类器h的输出也是随机的。随机子采样可以得到一个如下的平滑的分类器 使得分类器得到的标签j的概率最大。
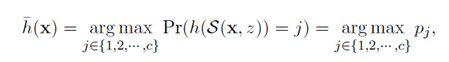
如果一个攻击者对GNN的输入注入一些扰动,当扰动的范式不超过阈值R的话平滑分类器可以高效能到相关的标签。因此,平滑子采样可以应用于GNN的后门攻击防御。
五、总结
本文对图神经网络的后门攻击与防御技术进行了系统的阐述。研究了GNN后门攻击的一般流程以及当前GNN后门攻击的方法。此外,对于GNN的后门攻击防御策略进行了探讨。
图神经网络是现在图挖掘应用的一个基础工具,而随着GNN的广泛使用,其安全性问题成为了企业必须考虑的问题。当前针对GNN后门攻防领域的研究一直在不断探索中,但是依然有以下方面的不足和需要探讨的方面:
- 通用的GNN后门攻击
当前已有的针对GNN模型的后门都是针对固定的应用,如图分类、节点分类。缺少一处通用的GNN后门攻击方法。
- 运行机制
后门的生成机制、出发器激活后门的机制并不透明,这也涉及到GNN的可解释性问题,如果这些机制可以被深入研究清楚,那么未来后门领域的攻防将会更有效、更精彩。
3)防御措施
目前的防御措施都是针对特定的攻击手段进行防御的,并不存在一种通用的解决方案,究竟有没有这种方案,如果有的话应该怎么实现目前来看都是未知的。
4)trigger的设计
图模型因其复杂性,导致触发器的选择是一个难点,尽管已有工作对于GNN的出发器进行了研究,但是依然缺少有效的方法。
参考文献
[1] Zhang Z , Jia J , Wang B , et al. Backdoor Attacks to Graph Neural Networks[C]// SACMAT ’21: The 26th ACM Symposium on Access Control Models and Technologies. ACM, 2021.
[2] Zhaohan Xi,Ren Pang,Shouling Ji,Ting Wang. Graph Backdoor.USENIX Security Symposium 2021
[3] Xu J , Minhui, Xue, et al. Explainability-based Backdoor Attacks Against Graph Neural Networks[J]. 2021..
[4] Ying R , Bourgeois D , You J , et al. GNNExplainer: Generating Explanations for Graph Neural Networks[J]. Advances in neural information processing systems, 2019, 32:9240-9251..
[5] Ahmed Salem, Rui Wen, Michael Backes, Shiqing Ma, and Yang Zhang. Dynamic backdoor attacks against machine learning models. arXiv, 2020.
[6] J. Chen, Z. Shi, Y. Wu, X. Xu, and H. Zheng. Link prediction adversarial attack. arXiv preprint arXiv:1810.01110, 2018.
[7] H. Wu, C. Wang, Y. Tyshetskiy, A. Docherty, K. Lu, and L. Zhu. Adversarial examples for graph data: deep insights into attack and defense. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, pages 4816–4823. AAAI Press, 2019.
[8] Alexander Levine and Soheil Feizi. Robustness certificates for sparse adversarial attacks by randomized ablation. In AAAI, 2020..
[9] Zheng Leong Chua, Shiqi Shen, Prateek Saxena, and Zhenkai Liang. Neural nets can learn function type signatures from binaries. In USENIX Security Symposium, 2017
[10] Hassan W U, Guo S, Li D, et al. NoDoze: Combatting Threat Alert Fatigue with Automated Provenance Triage[C]. NDSS, 2019.
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。