在对一个站进行渗透测试的过程中,信息收集是非常重要的。信息收集的详细与否可能决定着此次渗透测试的成功与否。本文详细介绍信息收集的八大方法,快来Get吧
《渗透测试最强秘籍》系列文章将会按以下主题陆续分享给大家,欢迎大家持续关注绿盟科技博客!
- 信息收集
- 配置和部署管理测试
- 身份管理测试
- 认证测试
- 授权测试
- 会话管理测试
- 输入验证测试
- 错误处理测试
- 弱密码测试
- 业务逻辑测试
- 客户端测试
1. 利用搜索引擎发现和侦察信息泄露
测试对象:testphp.vulnweb.com
尝试在谷歌中搜索:“site: testphp.vulnweb.com”,得到基本的爬虫结果如下:
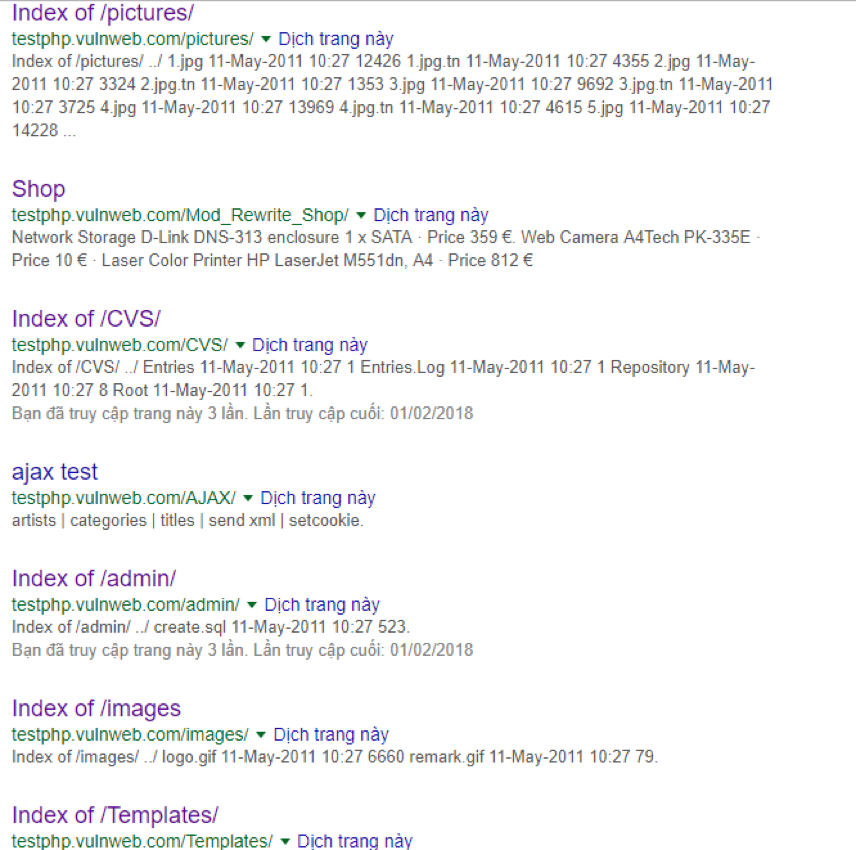
使用查询发现了更多有用的信息:
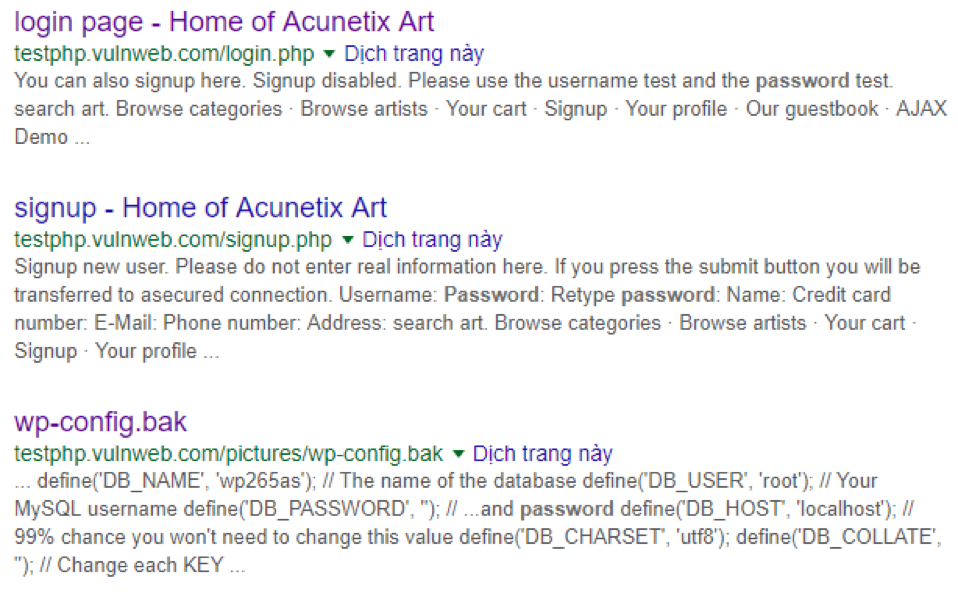
参考:
http://www.mrjoeyjohnson.com/Google.Hacking.Filters.pdf
2. web服务器指纹
Web 服务器指纹是渗透测试的关键任务。了解正在运行的 web 服务器的版本和类型能够让测试人员确定已知的漏洞以及在测试过程中使用适当的方法。
a)黑盒测试:
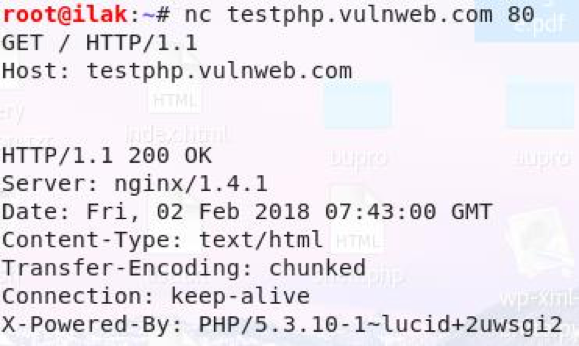
确认web 服务器身份的最简单最基本的方式是利用netcat查看 HTTP 响应报头中的服务器字段。
b)测试对象:
nc google.com 80
GET
/ HTTP/1.1
Host: google.com
enter
enter
c)自动测试工具:
httprint, Burpsuite
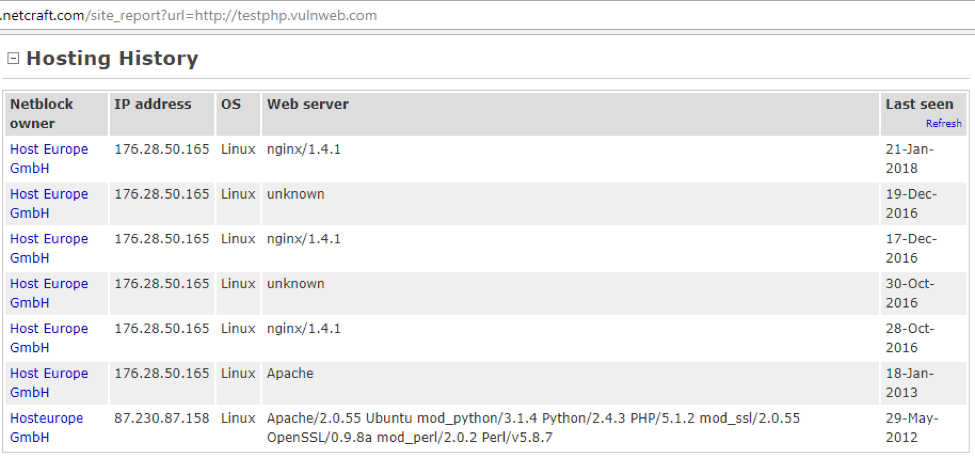
d)在线测试:
https://www.netcraft.com/
e)示例:
- netcat结果如下:
- 当然,我们也可以使用浏览器的一些拓展:

- 在线解决方案:
参考:
- http://www.terminally-incoherent.com/blog/2007/08/07/few-useful-netcat-tricks/
- https://www.sans.org/security-resources/sec560/netcat_cheat_sheet_v1.pdf
- http://netcat.sourceforge.net.
- https://www.darknet.org.uk/2007/09/httprint-v301-web-server-fingerprinting-tool-download/
- http://www.net-square.com/httprint.html
3. 查看web 服务器元文件发现信息泄漏
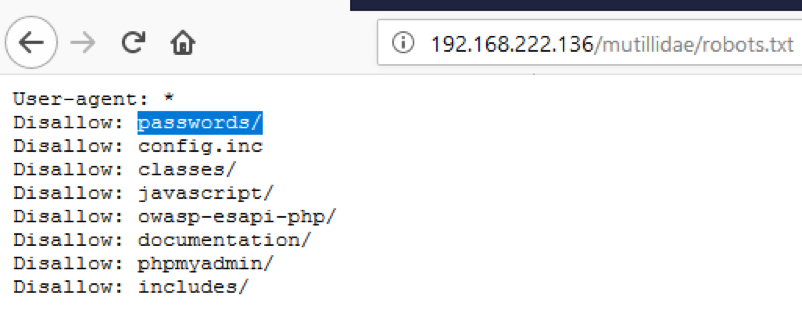
测试方法1:Robots.txt
网络蜘蛛/机器人/爬虫检索 (访问) 一个网页, 然后递归遍历超链接, 以检索进一步的 web 内容。他们的行为是由web根目录中robots.txt文件的Robots Exclusion Protocol指定的。
测试对象:abc.com/robots.txt
工具: 利用wget(例如: wget http://google.com/robots.txt)
参考:http://www.robotstxt.org/
示例:http://local/mutillidae/robots.txt
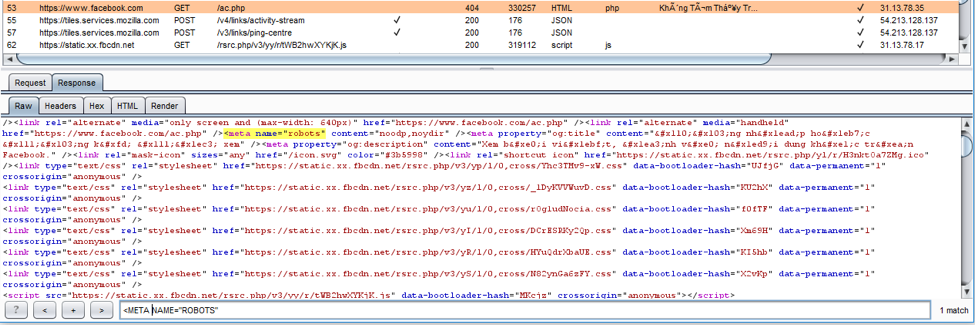
测试方法2:meta tag
Tag位于每个 HTML 文档的 HEAD 部分, 并且应该在一个 web 站点上的下述事件中保持一致:机器人/蜘蛛/爬虫的起始点不是从 webroot 以外的文档链接开始的。
网络蜘蛛/机器人/爬虫可以故意忽略 “<META NAME=”ROBOTS”>” tag。
工具: BurpSuite
4.枚举web 服务器上的应用程序
a) url:
b) 端口:
最基本和最简单的方法是使用端口扫描仪 (如 nmap)。例如:
nmap 0-65535 192.168.1.1
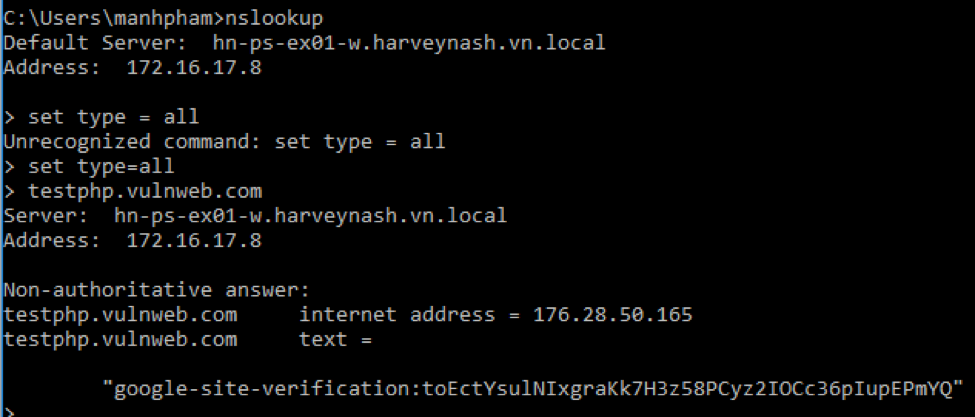
c) 域名:
- 有许多方法可以用来确定DNS名称给给定的IP, 其中一个是nslookup。
cmd
nslookup
all
set type=all
example.com
- 基于Web的 DNS 搜索:
http://searchdns.netcraft.com/?host
- Reverse IP
-Domain tools reverse IP: http://www.domaintools.com/reverse-ip/ (require free
membership)
– MSN search: http://search.msn.com syntax: “ip:x.x.x.x” (without the quotes) o webhosting info: http://whois.webhosting.info/
-DNSstuff: http://www.dnsstuff.com/
d) 谷歌hack技术
示例:
- nmap:

- nslookup
e) 工具
- nslookup, dig
- Port scanner: nmap http://www.insecure.org
- Nessus Vulnerability Scanner. http://www.nessus.org
- Search engine: shodan.io, google.
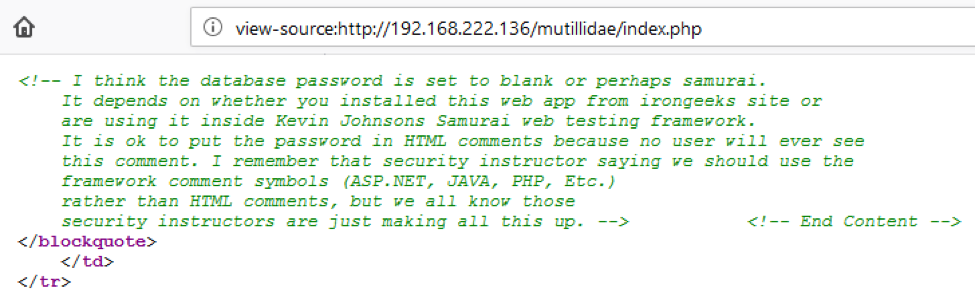
5. 审查网页评论和信息泄露的元数据
对于程序员来说, 在源代码中添加详细注释和元数据是非常普遍的,甚至是推荐的。但是, HTML 代码中包含的注释和元数据可能会对潜在攻击者暴露内部信息。应对源代码中的注释和元数据进行审查以确定是否泄露了任何信息。
工具:
- Wget
- 任何浏览器
6. 确认程序入口
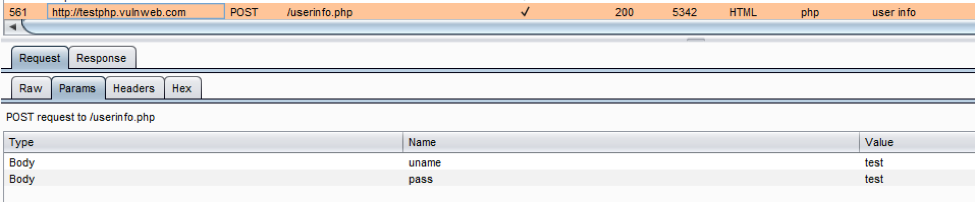
请求:
- 确认GETs和POST的位置
- 确认POST 请求中使用的所有参数(包括隐藏参数和非隐藏参数)
- 确认GETs请求中使用的所有参(通常在?之后)
- 确认查询字符串的所有参数
- 注意参数, 即使编码或加密, 并确定哪些帐户由哪些应用程序处理。
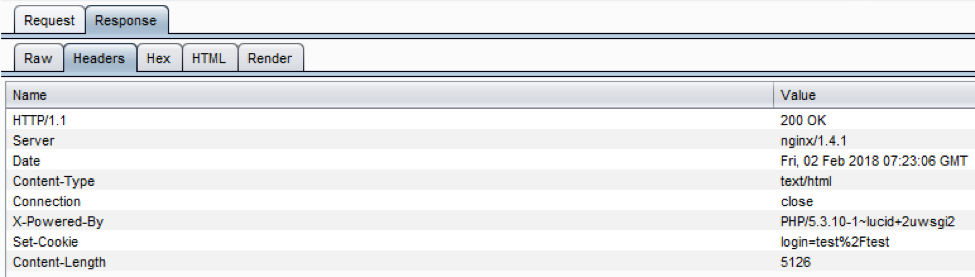
响应:
- 确认并记下任何header
- 确认哪里有重定向(300 HTTP 状态代码),400 状态代码, 403 禁用和500内部服务器错误。
工具:
- 拦截代理: Burpsuite, paros, webscarab,…
- 浏览器插件: Tamper data on firefox,…
一些注意事项:
- 为了发现隐藏的参数, 可以使用Burpsuit的以下选项:


- 使用Burpsuite 和状态代码来查找它们

- 使用Burpsuit捕获请求参数和响应头
7. 通过应用程序映射执行路径
在开始安全测试之前, 了解应用程序的结构是至关重要的。如果不彻底了解应用程序的布局, 就不可能对其进行彻底的测试。
a)测试目的
- 映射目标应用程序并了解主要工作流
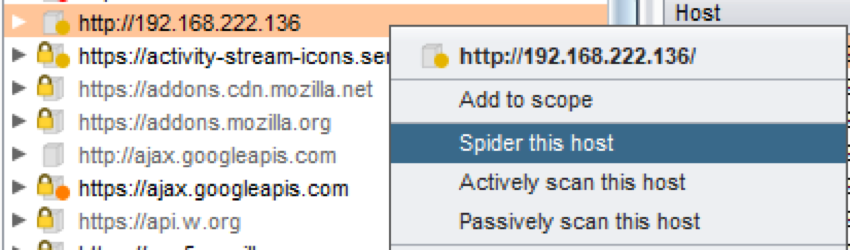
b)自动蜘蛛工具
- Burpsuit
- ZAP
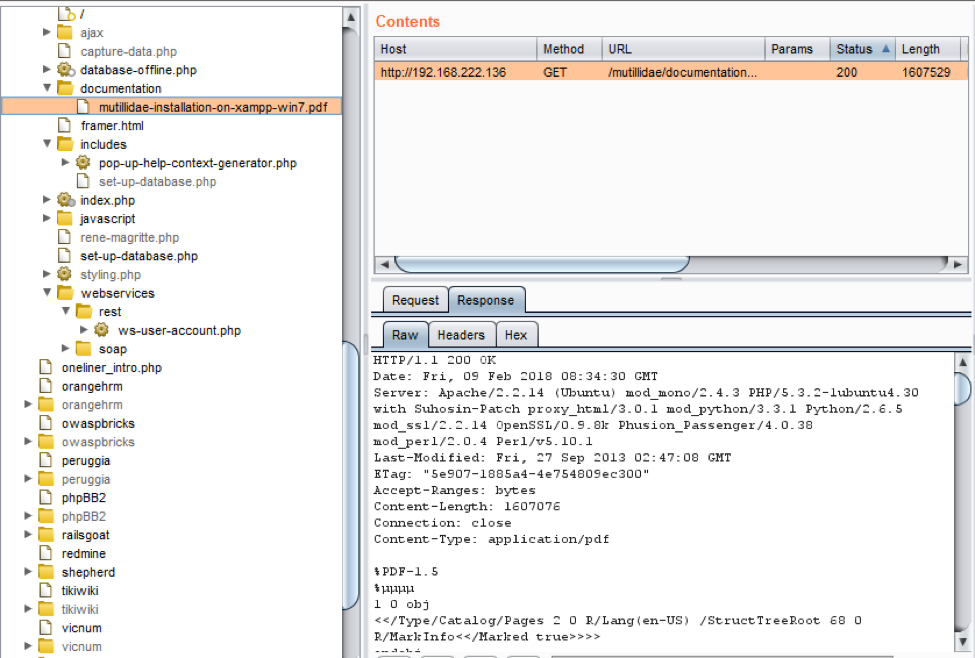
c)自动化蜘蛛示例
8. web 应用程序指纹和web 应用程序框架
Web 框架指纹是信息采集过程中的一个重要子任务。了解框架的类型会有很大的优势,特别是当这种类型已经被渗透测试过。不仅是版本中已知的漏洞使得指纹处理如此重要, 框架以及已知文件结构中的特定错误同样如此。
a) 黑盒测试
为了定义当前框架, 有几个最常见的位置可供查找
- HTTP 标头
- cookie
- HTML 源代码
- 特定文件和文件夹
b) HTTP 标头
- 标识 web 应用程序框架的最基本形式是查看 HTTP 响应标头中的 X-Powered-By 字段。
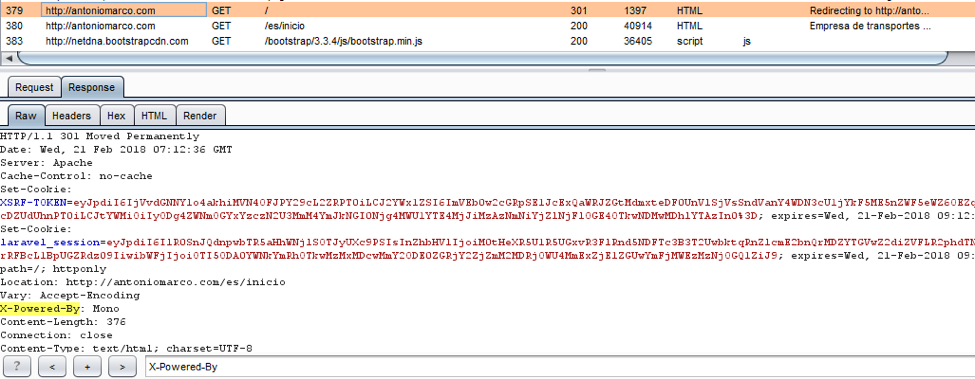
c) Cookies
确定当前 web 框架的另一个类似的、更可靠的方法是特定框架的 cookie。
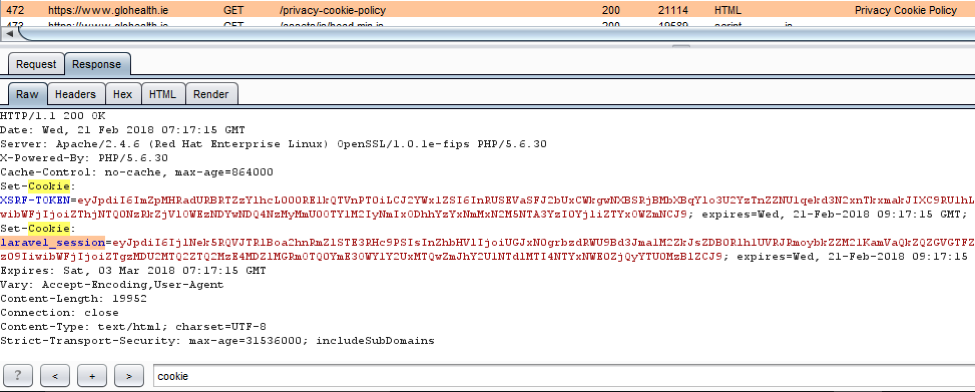
d) HTML 源代码
此技术基于在 HTML 页面源代码中查找某些模式。我们可以找到很多信息, 帮助测试人员识别特定的 web 应用程序。
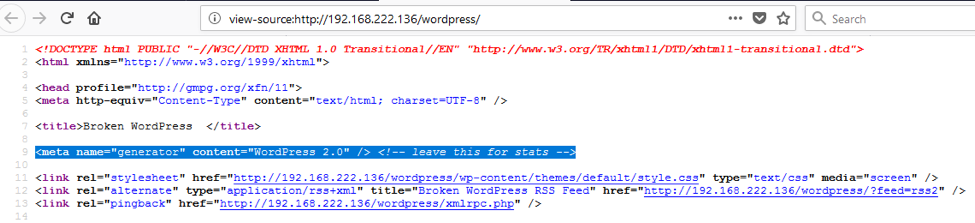
e)特定文件和文件夹
每个应用程序在服务器上都有自己的特定文件和文件夹结构。我们可以使用工具或手动访问它们。
f)Dirbusting 示例
- 谷歌黑客技术
https://www.exploit-db.com/ghdb/4675/
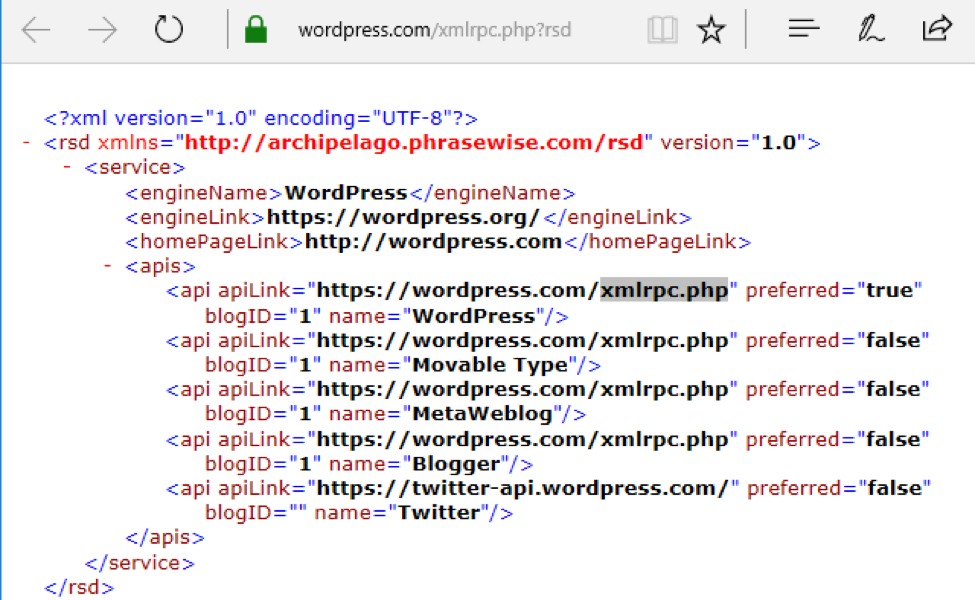
- BurpSuite 入侵
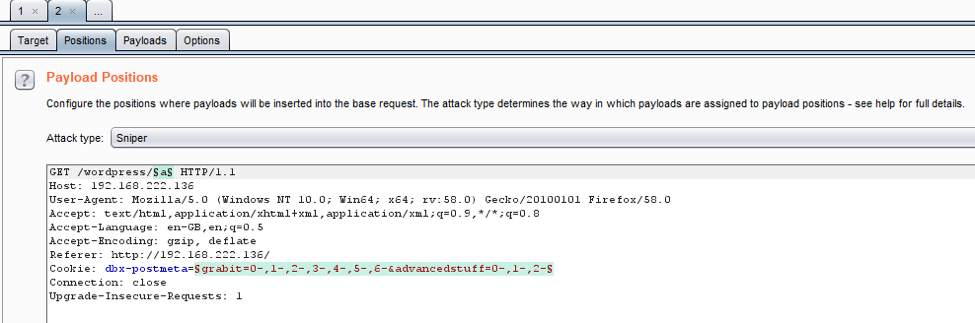
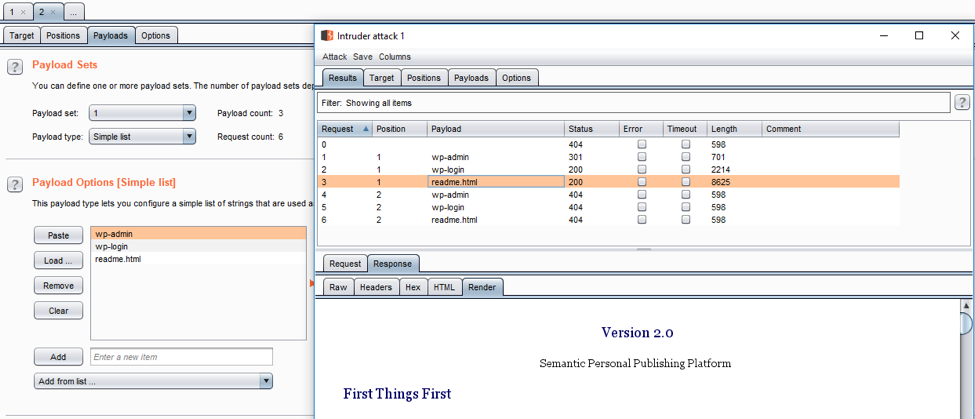
g)常见应用程序标识符
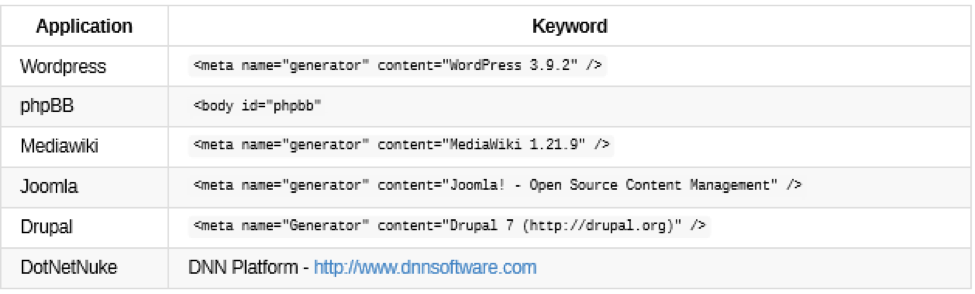
h)Nikto

i)Whatweb

原文链接
https://packetstormsecurity.com/files/download/146830/web-application-security-testing.pdf