MVCC(Multi-Version Concurrency Control,多版本并发控制):在并发操作数据库时,读操作可能会产生不一致的数据,为了避免这种情况,需要实现数据库的并发访问控制,使得每次读取到的数据都一致,最简单的方式便是加锁访问。也就是,将所有操作串行化,这样就不会出现不一致的情况。但是,串行化的读操作会被写操作阻塞,导致性能下降。
试想,“双十一”时淘宝的数据库订单读写如果采用串行化访问,如何能够保证每秒14万订单的峰值?
熟悉java的同学可能对java concurrent包中的CopyOnWrite系列的类有所了解,即写时复制机制,核心思想是读写分离,因为高并发往往是读多写少。而大多统计类项目也都是这种情况,进行读操作时,不加锁以保证读性能,写操作时加锁,以保证正确性。而MVCC机制类似,每个读操作会看到一个一致性的快照(复制),允许数据在数据库中存在多个版本,版本号当然必须是时间戳或者全局递增的事务ID,也就是保证同一时间点,不同的事务看到的数据是不同的。
而PostgreSQL的mvcc则是当一行记录被更新时,该行数据的新版本将被创建并插入表中,之前版本提供一个指针指向新版本,之前的版本则被标记为“过期”,但是还会保留在数据库中,直到垃圾收集器回收(因此也会存在空间占用问题,以及vacuum机制)。具体来讲,每个事务都会有一个叫做XID的事务ID,当一个事务开始时,postgresql递增该XID,可通过语句select txid_current()获取当前事务ID。
那么,如何根据每个事务ID保证高并发呢?这就需要谈谈几个在没行数据中隐藏的四个字段:xmin,xmax,cmin,cmax
xmin:插入的事务标识符,在insert一条记录时,记录此值为插入数据库的事务ID,如果一直操作同一条数据,则体现为递增;
xmax:删除更新的事务标识符,默认值为0,在删除数据行时,记录此值为当前事务号,如果此值为0,表示该行数据还未提交或者回滚(一般要看到此值的变化,需要使用begin-commit/rollback);
cmin,cmax:标识同一个事务中多个操作语句的序列值,从0开始,用于在同一个事务中实现版本可见性判断。
当插入一条记录时,PostgreSQL会把当前事务的XID存储在这一行中并称之为xmin。只有那些已提交而且xmin比当前事务XID小的记录才对当前事务是可见的。所以,可以在开始一个新事务插入一条记录,直到commit之前,插入的这条记录对其他事务永远是不可见的。等到提交后,其他的事务才能看到这行记录,因为满足了xmin<XID的条件,而且创建记录的事务已经完成。
即:一条记录要想可见,需要满足以下两个条件:
- xmin < XID:
- xmax > XID 或 xmax=0:
看下面的执行流程:
首先执行建表一句: create table test(id int, name varchar);

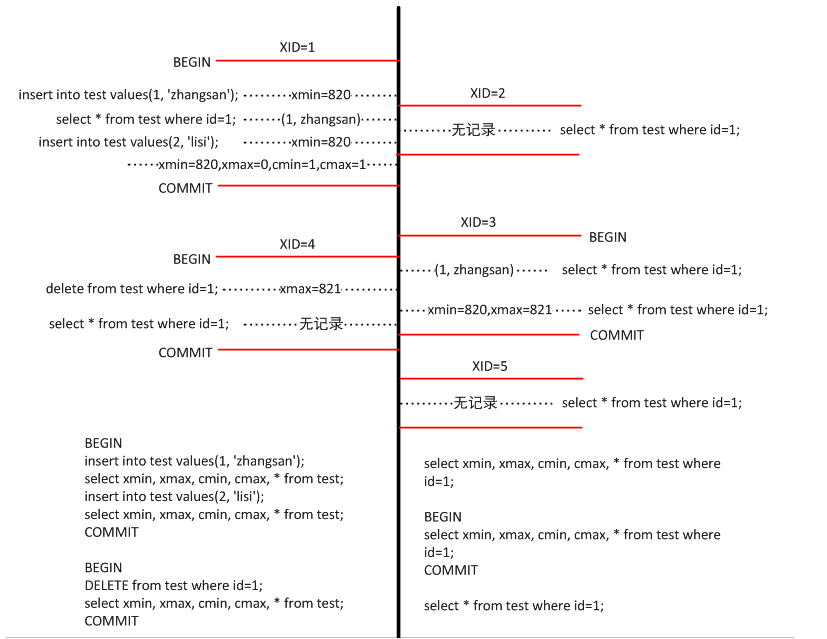
首先,需要明白上图中的事务XID是如何执行的:一套BEGIN/COMMIT作为一个事务;单独的一条SQL语句也是一个事务;事务ID的在一个数据库中是从1开始,因为上图中所在的数据库中存在其他的表,所以图中的事务XID是从820开始的。而为了简化图中事务的执行顺序,XID从1开始。执行顺序也比较简单,这里不再描述。
下面说一种复杂的情况:假设两个事务同时修改一条记录,怎么办?
这就涉及到每个数据库中都会涉及到的数据库的隔离级别(transaction isolation level):一个事务的执行不能被其他事务干扰。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(read uncommited) | |||
| 读已提交(read committed) | 避免 | ||
| 可重复读(repeatable read) | 避免 | 避免 | |
| 可串行化(serializable) | 避免 | 避免 | 避免 |
.幻读:重新执行一个查询,由于最近另一个事务的提交,导致返回的结果和刚才不同;
不可重复读:针对同一条记录,一个事务内多次查询,由于近期另一个事务的提交,导致结果不同;
脏读:一个事务读取了另一个事务还未提交的改动。
在PostgreSQL中,默认隔离级别是读已提交。当有两个事务同时修改一行数据时,后发生的事务在初始事务提交前就可以进行查找,然后不执行进行等待,待初始事务提交后retry,检查查找条件是否仍然满足,如果满足,后续操作才会被执行。删除操作类似。

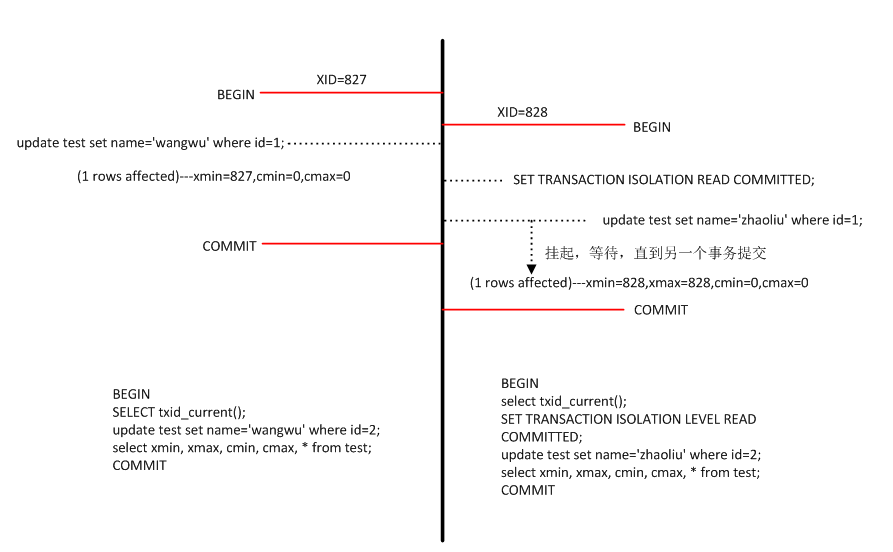
例如,上图中,在事务827提交之前,PostgreSQL机制会让事务827进入等待,直到827事务提交后才可以执行操作。如果没有MVCC机制,在执行事务828的update操作时,会直接拒绝执行,而有了MVCC机制,在事务827结束之前,就可以进入操作工作,事务828一直在retry,直到事务827提交,因此,相比于拒绝执行机制节省了等待时间。
MVCC优缺点
优点:
①由于数据库中保存着旧数据,回滚方便。
缺点:
①事务ID由32位数保存,支持大约40亿个事务,用完时,会出现wraparound问题;
②大量过期数据(dead rows)占用空间降低操作性能。
以上两个问题,都是通过VACUUM机制解决(类似java虚拟机中“标记-复制”垃圾回收方式回收磁盘空间)。