机器学习 和威胁情报在如今“数据驱动”(Data Driven)的时代依然是极为热门的概念,但是具体如何在威胁建模中采用机器学习,如何有效消费泛滥成灾的 威胁情报,在本届RSA大会中,有不少厂商也提出了自己对应的解决方案,包括:利用机器学习进行脆弱性管理预测,以及多源异构情报管理模型。
相关阅读:
【视频】TechWorld2017热点回顾 | 机器学习在安全攻防的实践
【RSA2018】创新沙盒 | Awake Security基于机器学习的安全分析平台
利用机器学习进行脆弱性管理预测
Kenna Security公司的首席数据科学家Michael Roytman在他的演讲中对他们在脆弱性管理预测中运用机器学习分类预测进行了建设性的阐述。
三种安全方式
Michael认为在目前数据驱动大背景下的安全方式主要有3种模式,分别是:回溯模式,实时模式和预测模式。

- 回溯模式主要呈现方式是基于数据进行分析之后以报告的形式进行呈现;
- 实时模式则是基于当下的数据进行实时计算出关于资产、脆弱性的相应指标之后来进行呈现;
- 预测模式则主要是利用机器学习。
机器学习算法选择
关于机器学习算法的选择,有一个简单的判断逻辑如下:
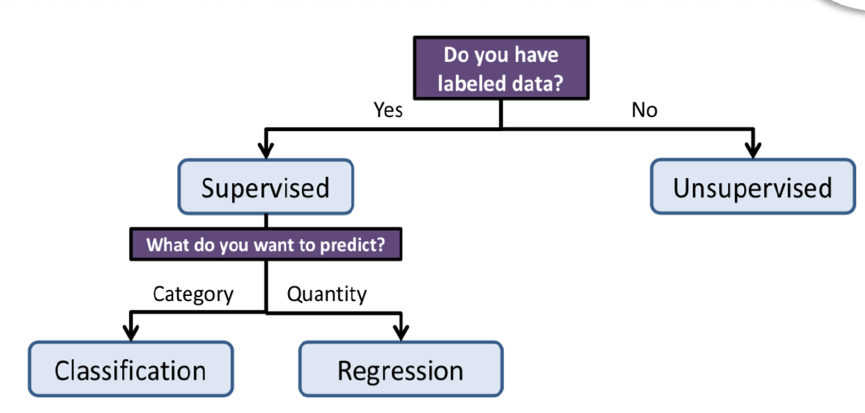
基本上算是机器学习的普遍方法:
首先根据是否具有打好标签的数据来选择监督还是非监督类算法,如果选择了监督类算法,还需要根据所需要的结果是定性还是定量来决定是采用分类算法或是回归算法。
相关阅读:
之后,Michael结合他们在进行“某漏洞是否有可能被利用”这一二分类预测问题时的具体做法来呈现分类预测实际运用时应该注意的要点:
- 样本数据的获取及标注

样本数据来源以及标签尽可能是较为权威的机构,如此保证了样本数据的质量。
- 要结合具体情况对分类结果设定适当的评估方案
当分类结果出来之后,要根据具体情况合理评估分类的实际效果,某些指标的权重应该要高于其它指标。比如对分布不平衡的数据,准确率(accuracy)低于某个值之后,分类结果的意义就不大了;此外,某些情况下精度(precise)的权重要高于查全率(recall);如果考虑到效率和时间因素,FP的权重可能要高于FN。总之,在进行算法调优的时候,需要根据具体的需要进行权衡,某些指标比其他指标更加重要。
- 考虑更多因素
Michael通过对比实验指出,对样本进行特征扩展之后比仅仅通过基本特征进行训练,分类结果要好得多。Michael在他的例子中展示了他扩展特征前后的分类效果对比:
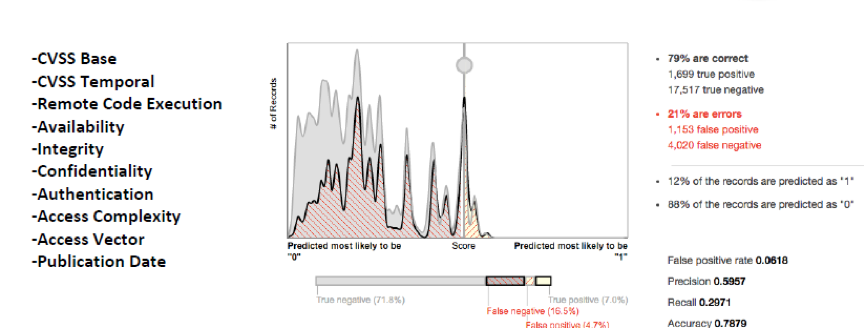


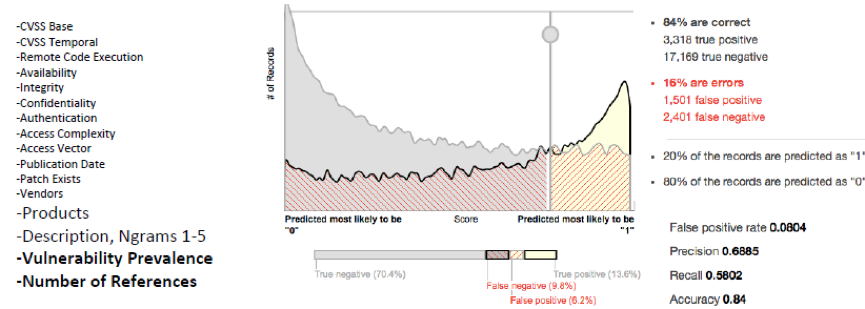
小结
在威胁建模当中运用机器学习的技巧与机器学习运用在其他领域时基本是一致的,关键的因素其实不在于算法本身,而在于数据要尽可能真实准确地反映事实情况,以及对结果进行必要的权衡。这就需要尽可能多地获取真实反映攻击路径(attack paths)的数据样本,并且明智地针对具体需求权衡那些指标是更重要的。
威胁情报泛滥解决方案
MKACyber公司的CTO Justin Monti 和CEO Mischel Kwon在他们的报告中针对目前威胁情报泛滥的问题给出了他们的解决方案。
多源异构的威胁情报难以管理
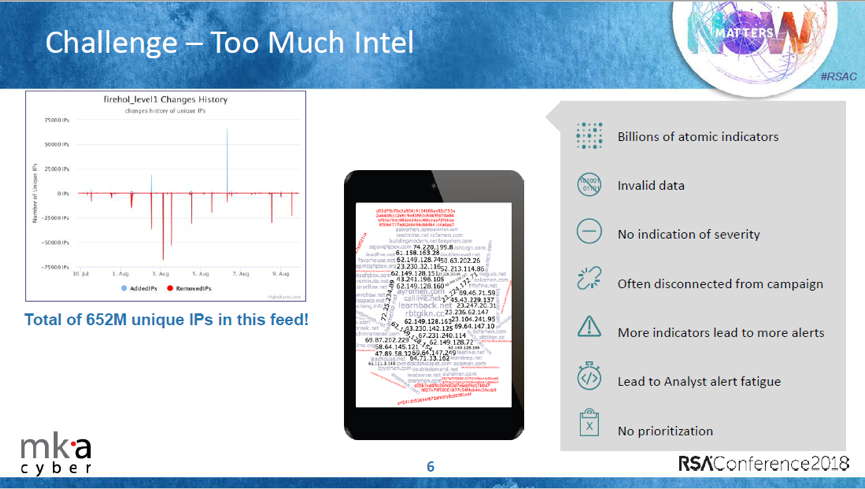
目前威胁情报的来源主要有以下的几种:

如此多源异构的情报使得分析人员难以分析、划分优先级,并进行相应的风险管理。
多源异构情报管理模型
对此,MKACyber公司提出了他们的情报管理模型:

MKACyber公司指出情报管理平台需要具备三个主要的功能:
- 情报的甄选
结合相关的业务和企业自身的架构对情报进行价值评估和选择。
- 情报的组织
让情报适配企业既有的威胁模型架构。
- 情报的管理(Triage&Curation)
包括对多源重复的情报去重,定期审查以及删除过期和不准确的情报。
MKACyber公司在报告中还具体这三个模块进行了举例阐述:

威胁情报价值评估

情报的组织和标签
小结
情报并非是越多越好,无关的情报和噪声情报只会影响情报所带来的价值,情报必须要进行妥善的管理,并且要基于相关业务对情报源及情报进行甄选,组织和管理。