RSA 2021如期在线上举行,大会主题为:Resilience(弹性),强调可恢复性和健壮性。该主题在如今世界疫情导致的混乱大背景下非常贴切,这或许也是黑客&威胁、风险管理相关内容在本届主题中占比最大的原因之一。当然,作为具有世界影响力的信息安全大会,传统安全所关注的一系列相关问题仍是讨论热点。很多参展厂商针对安全领域持续关注的课题提出了自己的思路,其中大部分是再次强调过去实践验证有效的成功经验和方法,另一部分则是创新尝试。
大数据场景下,威胁数据分析和威胁狩猎一直是国家相关监管部门和企业主要的安全应用场景,也是RSA一定会涉及的主题。内容往往涵盖宏观的威胁框架和业务流,以及具体的行之有效的算法应用和数据处理方法等。绿盟君通过梳理本届参展厂商汇报演讲内容,对海量数据背景下部分厂商的数据处理分析和威胁模型构建思路进行总结。
一、 海量多模态数据的处理方法
大数据场景下,威胁安全分析一开始需要面对的问题就是如何有效处理接入的海量告警。在一个典型的大数据场景下,接入的数据往往是海量且异构的。

这一阶段的核心诉求在于,一方面希望接入一切能够接入的数据以保证威胁特征的完整性,这些数据通常包括终端数据、各种网络流量探针数据、威胁情报甚至研判人员发出的相关日志等。而另一方面,又希望接入的数据能够得到有效整合和筛选,凸显出真正值得关注的少量数据,从而保证威胁特征的有效性。一定程度上这两个需求互相矛盾,但利用行之有效的范式化方法和特征关联筛选之后,仍然可以同时被满足。
来自Fortinet 的Roy Katmor和Udi Yavo在演讲中列出他们在数据处理阶段的一些关键步骤,包括数据范式化、特征提取、关联和富化。

IBM的Xiaokui Shu和Jiyong Jang在介绍他们的开源项目Kestrel时,将他们的威胁狩猎业务流定义为2个关键环节:多模态告警数据的模式化,以及基于该模式的分析模型。
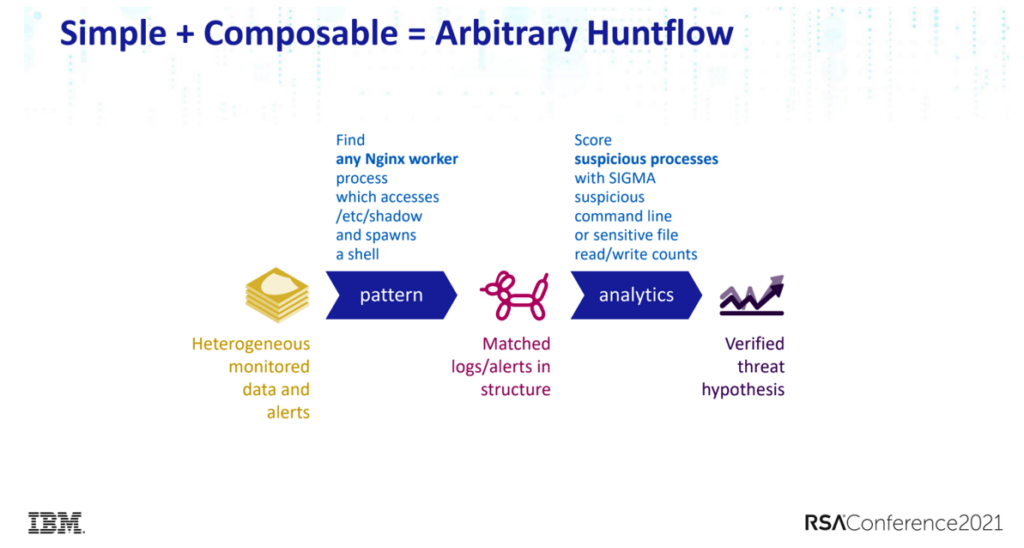
需要指出的是,Xiaokui Shu所说的多模态数据的模式化是基于威胁特征层面的模式化,而非是简单的数据(record)层面,这是他们后续进行基于实体(entity based)的威胁分析模型构建的基础。
此外,基于初始数据进行有效的关联扩展(Scoping)和上下文的富化(conetxt enrich)可以有效补充更多的威胁特征,以支撑后续威胁模型的训练和推理。
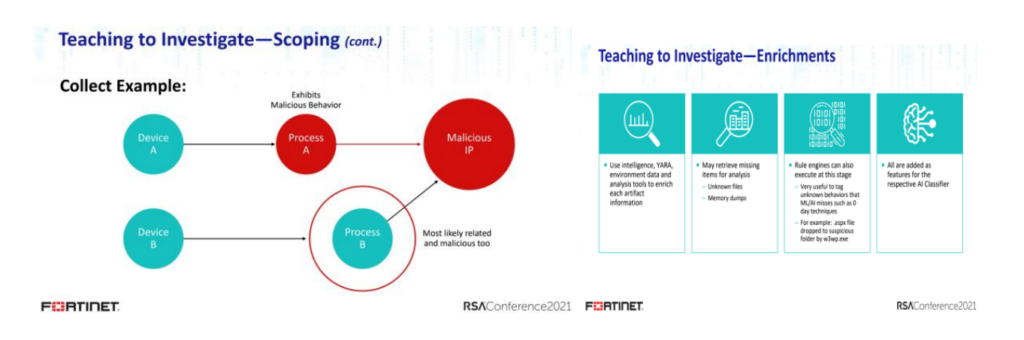
在如何有效聚焦和筛选数据方面,Stamus Networks的两位专家给出了他们的思路。
首先,他们认为可以基于真实的具体威胁源、C&C等类型,或者一系列TTP层面的要素组合方式进行筛选,而非简单根据量化的危险程度筛选。另外,从目标资产视角来进行筛选也是不错的思路。
综上所述,大数据场景下的海量多模态数据处理思路可以总结为几个关键环节:多源数据的采集、数据的范式化、数据的特征富化以及基于特征的筛选。每一个关键环节的具体做法往往依赖于具体安全业务场景和需求,更取决于后续威胁模型的具体数据要求。
二、 威胁模型构建方法
大数据场景下的威胁模型构建往往绕不开各种人工智能算法的参与,但与当年机器学习(尤其是深度学习)刚取得突破性进展时“机器学习无所不能”的氛围不同,近年来,包括信息安全在内的各个行业对于人工智能,特别是机器学习的局限性等问题越来越清晰,Fortinet 的两位专家在他们的《Applying Artificial Intelligence to the Incident Response Function》中就指出,在事件响应方面AI不能完全取代人工。

因此,目前绝大多数研究人员不再盲目相信智能算法,而是转而寻求人工深度参与的“半智能”方法,将专家知识和智能算法进行结合,从而提升算法的可控性和可解释性。
Fortinet的两位专家通过在分类模型的训练数据中引入模拟攻击数据来进一步加强对分类模型的人工干预,并基于细化的威胁特征场景来进一步构建不同的分类模型,降低对分类模型的过度依赖,提升分类模型的可控性。
而IBM的Xiaokui Shu和Jiyong Jang则提出了另一个相对较为新颖的思路:基于行为特征构建的威胁实体,结合专家构建分析模型进行推理。
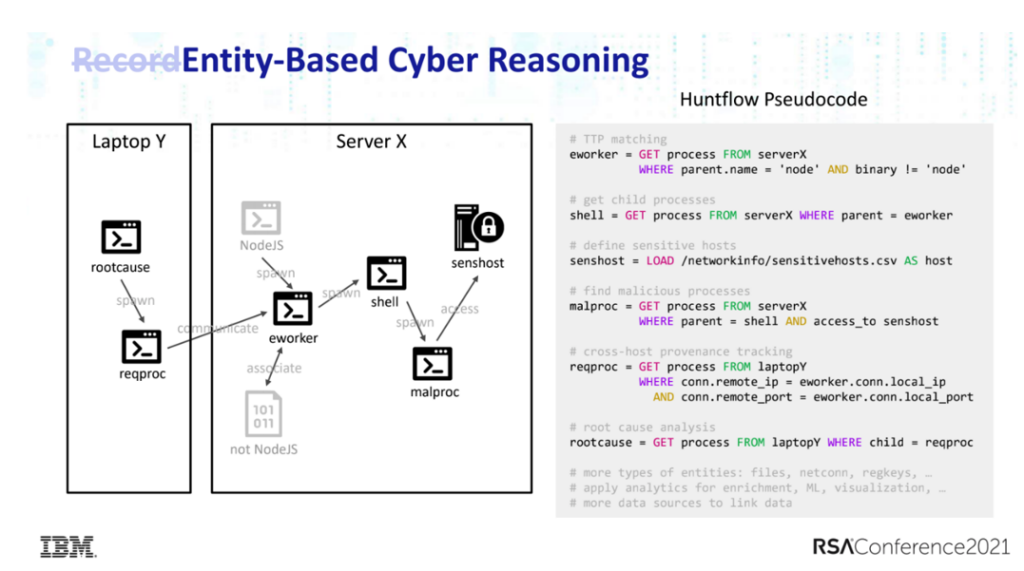
这个方法有一个前提,就是前文提到的利用行为特征模式化多模态数据,将海量多源异构数据转化为威胁实体,从而能从接近行为的层面进行关联推理。
他们还进一步提出,可以参照STIX的框架进行对应,将STIX中的域对象和关系对象对应威胁实体和推理生成的关联边,从而极大地提升模型的共享和导入能力。
三、 绿盟科技相关研究
绿盟科技平行实验室一直持续关注大数据场景下多模态数据的感知理解和威胁模型构建方面的研究。与上文所介绍的几个厂商的研究者方法类似,我们基于对威胁安全的认知,构建了绿盟科技威胁安全知识图谱,并基于图谱本体,将大数据平台接入的多模态数据范式化理解为威胁实体,依托知识图谱保存的威胁语义知识,在实体层面扩充并关联事件语义,结合专家知识和攻击链等模型对事件进行整合及筛选。
在威胁模型构建方面,通过抽取事件及相关上下文语义特征,与图谱中APT组织、恶意代码家族进行特征向量相似度计算,对威胁事件的攻击团伙进行归因。
此外,绿盟科技构建以威胁源为核心的特征图模型,并利用图计算进行多次迭代的聚类,从而发现隐藏于海量事件中的团伙活动。团伙特征也会在简单研判之后保存至图谱团伙知识库中,团伙知识库同样支持STIX格式的导入和导出。
四、 小结
通过梳理本届RSA中大数据场景下的数据分析和威胁模型构建相关方面的研究汇报,我们发现一些传统的思路没有改变,如尽可能接入可能包含威胁特征的多源数据,在保留威胁特征的前提下进行数据的范式化和筛选等。威胁情报引入、上下文语义的富化等处理方法也逐渐被更多厂商提及。
另外,值得一提的是,随着业界对于包括机器在内的人工智能算法的理解逐渐趋于理性,几乎不再看到单纯依靠人工智能算法支撑安全业务的情况,更多安全研究者正在考虑进一步分解安全业务,并加强专家知识的主动干预,从而在有效利用人工智能算法高效处理能力的基础上,提升算法的可控性和可解释性。
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。