网络流量分析,广泛运用于流量监控、网络安全检测、用户行为分析、计费管理或其他网络活动中。说起网络流量分析工具,很多人会想到Tcpdump和Wireshark。Tcpdump是很好用的抓包工具,Wireshark用户界面也十分友好,但是面对大规模网络环境,它们都显得很无力。
那么,大规模网络环境下,网络流量分析问题怎么破?
我们可以借助CERT NetSA开发的工具和Spark来轻松实现较大规模网络分析。
CERT NetSA工具简介
CERT NetSA Security Suite是由美国卡内基梅隆大学的网络应急响应组(CERT)开发的一套网络流量分析工具套件,用于分析大规模网络流量。我们主要讨论的是套件中的YAF和super_mediator。
SiLK工具套件支持网络流数据的高效收集、存储和分析,使网络安全分析人员能够快速查询大型历史流量集。SiLK非常适用于分析大型分布式企业的网络流量,以及中型ISP的骨干网络或边界流量。SiLK工具分为两种类型:包装系统和分析套件。包装系统中的rwflowpack,用来收集IPFIX、NetFlow v9或NetFlow v5等的流量,并将数据转换为一种节约存储空间的格式,然后记录到特定的SiLK文件中。分析套件可以读取SiLK格式文件,并执行各种查询、统计和过滤操作。

YAF工具可以处理tcpdump产出的pcap格式文件,将其打包成yaf格式文件,也可以实时捕获一个网卡的流量,将其转化为双向流,然后输出给IPFIX收集程序或基于IPFIX格式的文件。YAF的输出可以直接用SiLK的分析套件来进行分析。YAF还有深度包解析的插件,支持主流的应用层协议。

super_mediator是一个中间件,用于将YAF的输出转换为csv和json格式文件,或者存储到mysql中。
CERT NetSA工具安装与配置
以下介绍ubuntu环境下,以服务的方式安装配置相关工具,搭建一个流量采集节点。
安装依赖的库
NetSA的工具依赖glib2-dev和libpcap,直接apt-get安装:
sudo apt-get -y install libglib2.0-dev
sudo apt-get -y install libpcap-dev
libfixbuf是我们依赖的,按照以下流程安装:
wget http://tools.netsa.cert.org/releases/libfixbuf-1.7.1.tar.gz
tar -zxvf libfixbuf-1.7.1.tar.gz
cd libfixbuf-1.7.1
./configure && make
sudo make install
安装并配置YAF
YAF不需要修改过多繁杂的配置文件,直接从官方下载最新版的YAF码源,按照如下流程编译安装,注意编译配置时要添加applabel 和plugins配置项:
wget https://tools.netsa.cert.org/releases/yaf-2.8.4.tar.gz
tar -xvzf yaf-2.8.0.tar.gz
cd yaf-2.8.0
./configure –enable-applabel –enable-plugins
make
make install
然后新建日志文件路径,并将YAF安装目录下可执行文件以及配置文件拷贝至系统目录下,并修改可执行文件权限:
mkdir /var/log/yaf
cp etc/init.d/yaf /etc/init.d/
cp etc/yaf.conf /usr/local/etc/
chmod +x /etc/init.d/yaf
修改YAF配置文件如下:
#/usr/local/etc/yaf.conf
ENABLED=1
YAF_CAP_TYPE=pcap
YAF_CAP_IF=eth0
YAF_IPFIX_PROTO=tcp
YAF_IPFIX_HOST=localhost
YAF_IPFIX_PORT=18000
YAF_STATEDIR=/var/log/yaf
YAF_EXTRAFLAGS=”—silk –applabel –max-payload=2048 –plugin-name=/usr/local/lib/yaf/dpacketplugin.la”
然后我们就可以以服务的方式启动YAF了。

安装并配置super_mediator
同样从官网下载后编译安装:
wget https://tools.netsa.cert.org/releases/super_mediator-1.5.2.tar.gz
cd super_mediator-1.5.2
./configure && make
make install
修改super_mediator的默认配置文件:
#/usr/local/etc/super_mediator.conf
COLLECTOR TCP
PORT 18000
COLLECTOR END
rwflowpack
EXPORTER TCP “silk”
PORT 18001
HOST localhost
FLOW_ONLY
EXPORTER END
EXPORTER TEXT “flow”
PATH “/data/flow/flow.json”
JSON
EXPORTER END
DEDUP_CONFIG “flow”
PREFIX “useragent” [111]
PREFIX “server” DIP [110, 171]
PREFIX “host” [117]
PREFIX “dns” [179]
MAX_HIT_COUNT 10000
FLUSH_TIMEOUT 600
DEDUP_CONFIG END
LOGLEVEL DEBUG
LOG “/var/log/super_mediator.log”
PIDFILE “/data/super_mediator.pid”
以后台运行方式启动super_mediator,启动后super_mediator会监听18000端口:
super_mediator -c /usr/local/etc/super_mediator.conf –daemonize
![]()
测试各工具是否能正常工作
使用ifconfig查看本地网卡信息,确定要抓取的网卡。
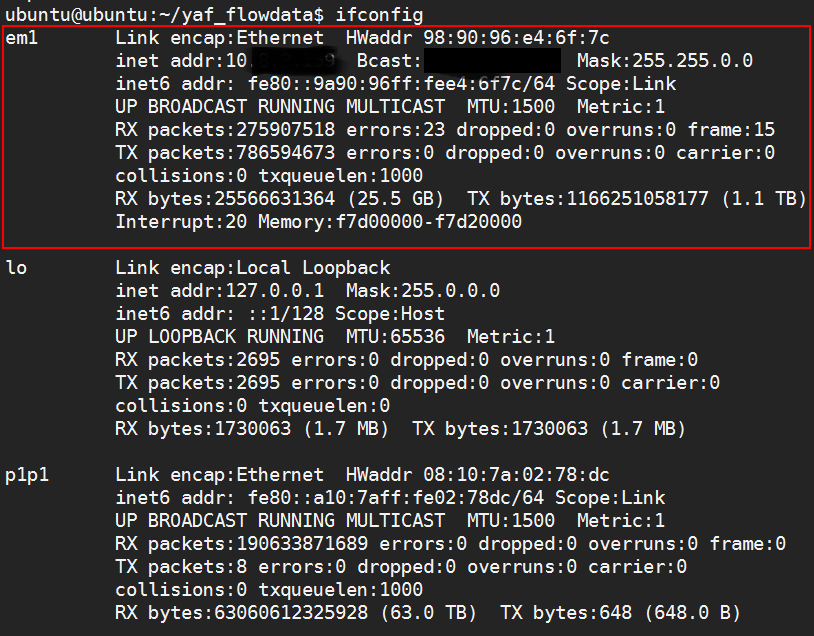
启动YAF,实时抓取网卡em1流量,并通过18001端口传输到rwflowpack,让SiLK输出处理后的流量文件。每60秒传输一次,并加上DPI解析插件,启动命令如下:
sudo yaf –in em1 –live pcap \
–ipfix tcp –out localhost\
–log /var/log/yaf/yaf.log \
–verbose –silk –verbose –ipfix-port=18001 \
–applabel –max-payload 2048 \
–applabel-rules=/usr/local/etc/yafApplabelRules.conf \
–plugin-name=/usr/local/lib/yaf/dpacketplugin.so –rotate=60
接下来将YAF抓到的流量包通过18000端口传输给super_mediator,然后super_mediator会将流量包数据转换为本地JSON文件,启动命令如下:
sudo yaf –in em1 –live pcap \
–ipfix tcp –out localhost\
–log /var/log/yaf/yaf.log \
–verbose –silk –verbose –ipfix-port=18000 \
–applabel –max-payload 2048 \
–applabel-rules=/usr/local/etc/yafApplabelRules.conf \
–plugin-name=/usr/local/lib/yaf/dpacketplugin.so –rotate=60
Super_mediator输出的json示例如下图:

CERT NetSA工具配合Spark
上文已经提到,super_mediate可以将YAF的输出转换为本地的json文件。我们可以使用flume对super_mediator输出的json文件进行监控,并将文件变化实时传输到HDFS上,整体流程如下图。

首先下载flume到本地,然后在flume文件路径的下conf目录下添加一个配置文件,这里将这个文件命名为flume_flow.conf,具体内容如下:
#example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = hdfs-sink
a1.channels = c3
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/flow/flow.json
a1.sources.r1.shell = /bin/bash -c
a1.sources.r1.restart = true
a1.sources.r1.restartThrottle=1000
# Use a channel which buffers events in memory
a1.channels.c3.type = file
a1.channels.c3.checkpointDir = ~/.flume/checkpoint/c3
a1.channels.c3.dataDirs = ~/.flume/data/c3
a1.sinks.hdfs-sink.type = hdfs
a1.sinks.hdfs-sink.channel = c3
a1.sinks.hdfs-sink.hdfs.path = hdfs://192.168.*.*:9000/flume/%y-%m-%d/
a1.sinks.hdfs-sink.hdfs.useLocalTimeStamp = true
a1.sinks.hdfs-sink.hdfs.filePrefix = flow
a1.sinks.hdfs-sink.hdfs.round = true
a1.sinks.hdfs-sink.hdfs.roundValue = 10
a1.sinks.hdfs-sink.hdfs.roundUnit = minute
a1.sinks.hdfs-sink.hdfs.writeFormat = Text
a1.sinks.hdfs-sink.hdfs.rollSize = 0
a1.sinks.hdfs-sink.hdfs.rollInterval = 60
a1.sinks.hdfs-sink.hdfs.rollCount = 0
a1.sinks.hdfs-sink.hdfs.batchSize = 10
a1.sinks.hdfs-sink.hdfs.fileSuffix = .json
a1.sinks.hdfs-sink.hdfs.fileType = DataStream
需要注意的是flume向hdfs发送数据依赖Hadoop相应的jar包。可以下载一个完成的Hadoop安装文件,然后按Hadoop的安装流程配置好环境变量。
在YAF和super_mediator成功运行的情况下,使用刚写好的flume配置文件运行flume,命令如下:
cd apache-flume-1.7.0-bin/bin/
./flume-ng agent -n a1 -c conf -f ../conf/flume-flow.conf -Dflume.root.logger=DEBUG,console
成功运行后会打印出HDFS文件写入日志。

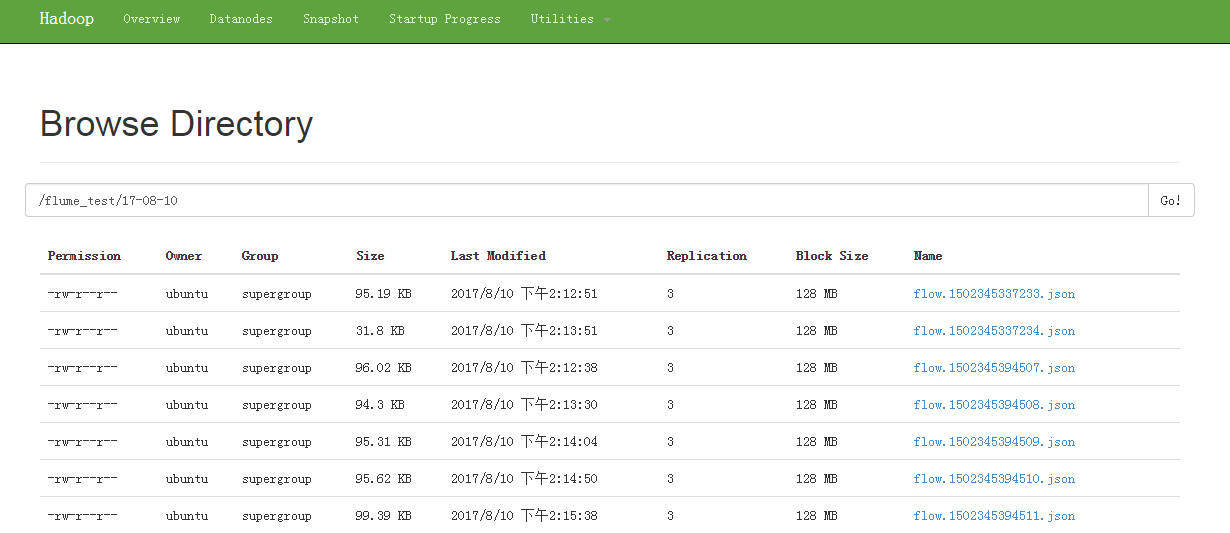
通过Hadoop的web管理界面查看数据,可以看到flume实时传过来的数据。
数据到了HDFS,我们就可以用Spark分析flume发过来的json数据,还可以用zeppelin展现。
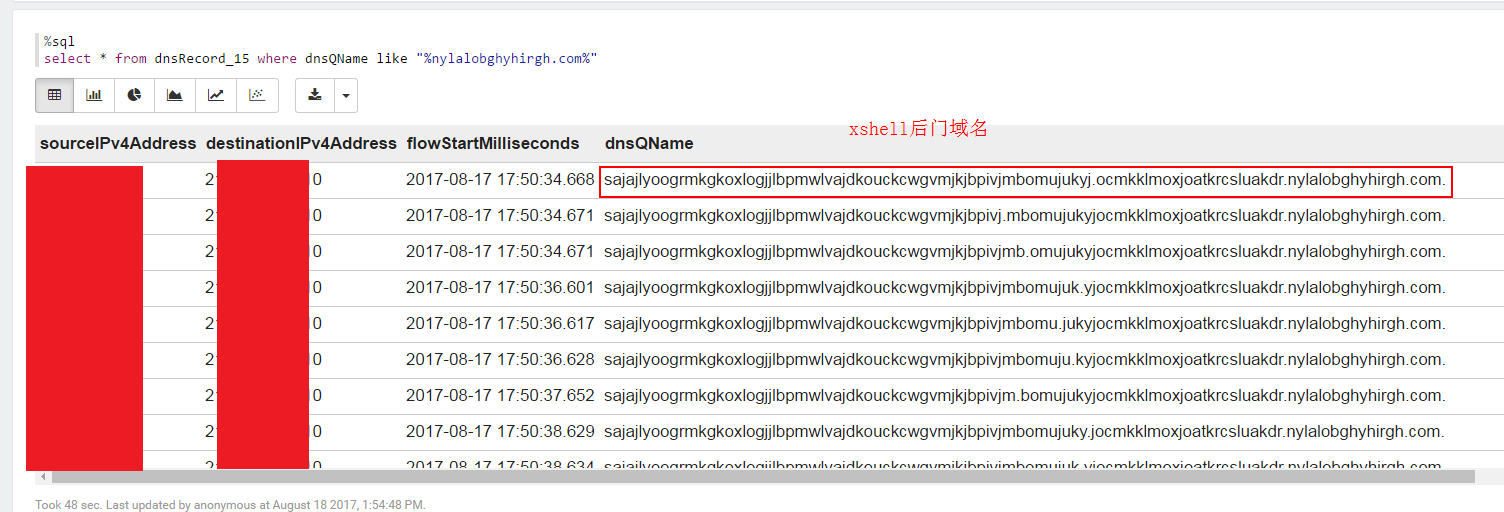
对于近期发生的xshell的DNS后门事件,我们可以借助DPI解析出来的DNS记录来定位内网中受影响的主机,示例如下:
总结
YAF配合super_mediator可以方便的将流量数据实时的转化为Spark可读的json数据。在规模环境下,只需将配置好YAF和super_mediator的流量采集节点机器部署到网络主要出口的交换机旁路上,然后接入交换机流量镜像,在通过flume将数据传给Spark,即可通过Spark对网络流量数据进行分析,做到较大规模网络环境下近乎实时的网络流量分析。
参考文献
[1]https://tools.netsa.cert.org/index.html
[2]http://tools.netsa.cert.org/yaf/libyaf/yaf_silk.html#install
[3]https://tools.netsa.cert.org/super_mediator/super_mediator.html
[4]http://flume.apache.org/documentation.html