本文主要阐述用python结合spark做数据分析和绘制有向图
工作需要,需要计算各个节点的出度,入度,最终表现为有向图的形式
首先数据量比较大,这块对于各个数据的抽取和出入度计算采用spark来计算
因为使用的语言是python,所以这里用的是pysark的graphframe;Pysark是spark为python开发者提供的API。
graphframe是将spark中的graph算法统一到DataFrame接口的Graph操作接口,支持多种语言,可以供python使用。
安装配置环境
安装python包:首先需要个python 的package这里我们直接下载https://github.com/graphframes/graphframes
grameframe的源码,然后把中间的python目录放到我们的python三方库路径就可以
spark依赖:spark解析需要一个包graphframes:0.2.0-spark1.6-s_2.10
网址在(http://spark-packages.org/package/graphframes/graphframes),要根据自己的spark版本去选择合适的包
使用的话在自己的python脚本里面提交spark任务时候加上:
os.environ["PYSPARK_SUBMIT_ARGS"] = (
"--packages graphframes:graphframes:0.2.0-spark1.6-s_2.10 pyspark-shell"
)
清楚自己可以调用那些接口
原来我有个毛病,就是啥问题都喜欢搜中文的,结果经常被坑,以后发现对于这种库要去了解,最有效的方式是1.直接看源码接口 2.硬着头皮看官方的英文文档
graphframe里面我们使用方式有:
1.先生成graph对象:
G = graphframe.GraphFrame(verice,edges)
这里有两个变量,一个是顶点dataframe,一个是边dataframe
顶点的格式是:【id,name】
边的格式是【src,dst,”action”】
需要先将数据抽取成上面的格式再传入
2.可以调用的方法接口:
outDegree()所有节点的出度
inDegree()所有节点的入度
bsf()宽度优先搜索,查找节点的最短路径
pageRank()按照其他节点指向它的数目来排序,指向一个节点的越多,这个节点就越重要
vertice打印出顶点
edges打印出边
具体使用
我们这里只需要计算出入度和出度
所以直接构造顶点和边的dataframe然后输入即可
g = dataframe.GraphFrame(vertices,edges)
g.inDegree()
g.outDegree()
画图
我们需要将自己的图用一个具体的有向带权图表示出来
这里选用的python的networkx
网上搜的说python里面这个画图不错,但是其实实用一下觉得这个很一般,也就是自己凑合着能看了
import networkx as nx
graph = nx.DiGraph()
graph.add_edges_from(weigth_lsit)(类似{“1”“2”,“权重”})
pos = nx.nx.spring_layout(graph, scale=2, center=(4,5)) # positions for all nodes
# 首先画出节点位置
# nodes
nx.draw_networkx_nodes(graph, pos, node_size=300,node_color='r')
edge_labels = nx.get_edge_attributes(graph,'weight')
# labels标签定义
nx.draw_networkx_labels(graph, pos, font_size=10, font_family='sans-serif', \
horizontalalignment="left")
nx.draw_networkx_edges(graph, pos,alpha=0.5)
nx.draw_networkx_edge_labels(graph,pos,edge_labels = edge_labels,label_pos=0.3)
#nx.graw(graph)
plt.axis('off')
plt.savefig("weighted_graph.png") # save as png
plt.show() # display
帖张最后的图,我这是网络链接图
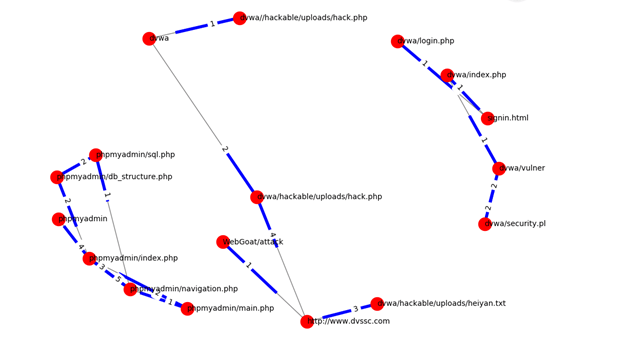
图中粗线就是箭头的意思,这个真的只能自己人看看,要高大上的还要另想办法
如果有更好的方法和建议欢迎联系我,多谢指导
点击查看更多spark内容!