打破数据孤岛效应,促进数据流通,在数据流动中实现数据价值的最大化,是数据控制者/处理者的共同目标。数据蕴藏的巨大价值与隐私保护之间的矛盾日益突出,如何更好地实现两者的平衡是当今一个亟需解决的行业关键性问题,引起社会各界的强烈关注。
前言
在大数据时代,数据采集和存储变得越来越容易。在政府、互联网、运营商、医疗、银行和电力等各行各业的大数据中,或多或少与个人信息有关。比如手机APP收集用户的个人注册,网页浏览息,购物和GPS位置等信息;运营商收集用户注册、电话账单、GPS以及使用流量等信息;医院会记录患者个人基本信息,以及医疗原始数据和诊断等信息。
与此同时,Open Data成为全球的大数据发展的典型趋势。数据共享、发布、外包,甚至交易等场景需求变得越来越多。欧盟在2003年实施了《公共部门信息再利用指令》;美国在2009年颁布了《开放政府指令》。我国同样实施一系列的政策和措施,比如《促进大数据发展行动纲要》(2015)、《贵州省大数据发展应用促进条例》(2016),以及今年5月份实施的《中华人民共和国政府信息公开条例》。此外,我国《网络安全法》的第十八条指出“国家鼓励开发网络数据安全保护和利用技术,促进公共数据资源开放,推动技术创新和经济社会发展”。
打破数据孤岛效应,促进数据流通,在数据流动中实现数据价值的最大化,是数据控制者/处理者的共同目标。数据蕴藏的巨大价值与隐私保护之间的矛盾日益突出,如何更好地实现两者的平衡是当今一个亟需解决的行业关键性问题,引起社会各界的强烈关注。
此外,数据控制者/处理者在处理个人信息与敏感信息过程中,如果保护不力而造成用户信息泄露,将触犯法律面临刑事处罚。最近,最高人民法院、最高人民检察院联合发布《最高人民法院、最高人民检察院关于办理非法利用信息网络、帮助信息网络犯罪活动等刑事案件适用法律若干问题的解释》,对网络服务提供者不履行信息网络安全管理义务,致使用户信息泄露的造成“严重后果”进行了明确的定罪量刑:致使泄露行踪轨迹信息、通信内容、征信信息、财产信息500条以上的;致使泄露住宿信息、通信记录、健康生理信息、交易信息等其他可能影响人身、财产安全的用户信息5000条以上的;造成他人死亡、重伤、精神失常或者被绑架等严重后果的等八种情形。在企业内部正常的业务场景中,有使用个人信息和个人敏感信息需求,比如产品测试,数据分析,培训等。假设在某家住宿集团公司中,测试人员需用顾客信息进行软件测试,假设他可以访问住宿顾客的原始住宿记录,该测试人员铤而走险导出5000条记录卖给黑市。那么有法可依,有法必依,该集团“不履行信息网络安全管理义务,致使用户信息泄露的造成严重后果”的罪名成立。
匿名化作为一种解决“数据可用”和“隐私保护”两难困境的有效技术,在学术界首先引入深入广泛的研究,包括各类不同算法、模型以及基础理论的研究,如著名的K-匿名算法 (K-anonymity)。另一方面,由于匿名化 (Anonymization) 可实现“经过处理无法识别特定个人且不能复原”,这个概念逐步被各个国家的相关立法机构所接受、所采纳。所谓匿名化,从字面理解,是匿名的处理,而“匿名”可理解是将原始数据记录代表的“自然人”实现“身份匿名”。具体来说,通过各种技术手段,比如删除标识符、泛化和加噪等操作,切断自然人与数据记录的关联。从而不仅保留所需的数据价值,同时降低了隐私泄露的风险。
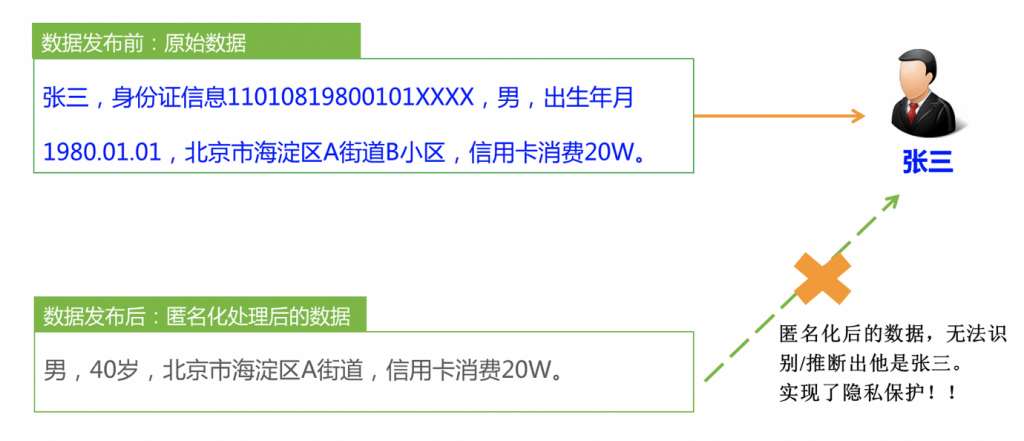
法规作为数据安全治理和建设的顶层指导,研究这些法规,一方面有助于更好地理解安全场景与需求,进而有利于将安全技术实际的落地与应用。近年来,全球掀起了“数据安全与隐私保护”的立法热潮,对个人信息的采集、使用和存储进行严格的法律的规范,对不合规企业进行相应等级的处罚。在其中一些法规中,匿名化处理后的数据或多或少存在一些法规的豁免权,例如可以进行共享、发布和交换。概念的定义是法规的重要基础。笔者作为技术研究人员,尝试阐述和解读欧盟、日本以及美国相关法规对匿名化概念的定义以及区别,最后笔者基于这些材料和解读发表几点不成熟的思考。国外法规和标准的翻译,笔者小心翼翼的翻译和修改,但难免存在小许的错误和偏差,欢迎各位专家指正。本文后面附上原始的英文表达。图2给出了一个简单示例,在上方的原始数据由于存在身份信息,那么一定可以唯一地识别这个人;而下方处理后的数据仅保留性别,并对出生年月日进行仅保留年份(即年龄)且四舍五入处理,地址进行了泛化仅保留到街道地址。假设符合这样的情况,人数有100人,那么无法推断敏感信息(信用卡消费20W)一定属于张三本人,因为这条信息可能属于李四,王五等等自然人。
1 国内外的匿名化相关概念定义
匿名化 (Anonymization) 相关概念 (如匿名信息 (Anonymous information)、 匿名处理信息(Anonymously processed information)) 在欧盟和日本有相对成熟的法律定义,我国近年来的法规和标准也在逐步采纳匿名化这个概念。值得关注的是,美国的相关法规中多采用一个相近的概念——去标识化 (De-identification,亦翻译为去身份化) 相关概念 (如去标识的信息,Deidentified information)。下面对相关法规进行简单的解读和分析。
1.1 欧盟
《通用数据保护条例》(General Data Protection Regulation,简称GDPR):前言第 26 段,匿名信息 (Anonymous information) 是指与已经识别 (identified) 或可能识别 (identifiable) 的自然人不相关的信息,或者以数据主体不可或不再可识别的方式提供的信息。该段前文对“可能识别”(identifiable) 进行了解释:为了确定自然人是否可识别,应考虑合理且可能地(reasonably likely)穷举所有手段,例如由控制者或另一人单独挑选 (singling out),以直接或间接地识别自然人。
解读:在GDPR的第四条第1款定义:“个人数据 (Personal data) 是关于一个已识别或者可能识别的自然人(即数据主体)的任何信息…”。显然,匿名信息和个人数据均建立在数据主体的识别基础。个人数据的“识别”实际包含两个层面的含义:① 已经识别 (identified); ② 可能识别 (identifiable)。已经识别(identified) 表示这个身份信息已经确定,比如张三,11010819800101XXXX,男,出生年月1980.01.01,北京市海淀区A街道B小区,信用卡消费20W(假设该地区只有一人叫张三);可能识别 (identified),一般来说,一般在没有额外背景或额外身份数据库等信息的情况下定位到这个人。比如另一个处理的信息:男,出生年月1980.01.01,住在北京市海淀区A街道B小区的人,信用卡消费20W。但这不排除存在某种可能性,张三的朋友正好十分了解他的出生年月,推断出这条信息属于“张三”,进而获得了他的隐私信息。由此可见,可能识别 (identifiable)比已经识别 (identified)的判定更加苛刻,不具有已经识别的数据但仍然可能存在“可能识别”的属性。

如GDPR所述,匿名信息正好相反,是一种建立消除个人数据的 “已经识别” (identified)和“可能识别”(identifiable) 得到的处理结果。GDPR在该段中进行了详细解释:“为了确定自然人是否可识别,应考虑合理且可能地(reasonably likely)穷举所有手段,例如由控制者或另一人单独挑选 (singling out),以直接或间接地识别自然人。为了确定是识别自然人的手段是否是合理且可能,应考虑所有客观因素,例如识别的成本和所需的时间,同时考虑到识别时的可用技术,技术水平和技术发展”。 说明GDPR对匿名信息的判定与否,特别是对可能存在“可能识别”的一类数据,它评估和判定的手段是“合理且可能的”,而这个“合理且可能的”手段并不是几种固定的方法集合,可选的识别手段与当前“识别的成本和所需的时间,“识别时的可用技术,技术水平和技术发展”完全相关。一般来说,未来的攻击者比现在的攻击者获得的数据资源、关联技术将更多更强,这种评估是动态的。GDPR立法层面希望尽可能通过一部法律覆盖所有的个人数据安全问题,力求“大而全”。但该判定标准的描述仍然十分抽象,不够明确,为GDPR法规的实施执行留下了相应的解释空间。具体来说有以下几个问题:何为“合理地”(reasonably)?何为“可能地”(likely)?谁来做最终的判定?在下面的一个文件的观点可以找到一部分的答案。
《关于匿名化技术的意见书》:匿名处理结果的3个判断标准:(i) 是否仍有可能挑出一个人?(ii) 是否仍有可能将一个人记录关联起来?(iii) 是否可以推断有关个人的其他信息?Art.29WP 在该文件上提到:当一项提案不符合其中任意一项标准时,应对剩余的重识别风险进行彻底的评估。如果国家法律要求管理局对匿名处理程序进行评估或授权,则应向当局提供这一评估。
解读:该意见由欧盟29 条工作组 (Article 29 data protection working party,简称Art.29WP)在2014年发布。Art.29WP由每一个欧盟成员国的数据保护管理局、欧洲数据保护监督员和欧洲委员会的代表组成,代表了欧盟官方机构对数据隐私保护的权威意见。该意见书从这三个问题维度进行判断,相比GDPR的定义的“合理且可能”的限定更加严格,有追求完美的嫌疑。该意见书对假名化(Pseudonymisation)、加噪(Noise addition)、K-匿名化(K-anonymity)等多种技术进行分析,结论是这些方法处理后的数据均不符合这三个标准,多少都存在一定程度的剩余风险。例如,在K-匿名化中,每一个等价组中有K()个实体,它不能被唯一挑选出来;但它仍然存在链接的可能性,链接成功的概率为 ;由于K-匿名化并没有考虑到敏感属性的分布,因此对于敏感属性相同的组,不能抵抗推断攻击。总之,它仅满足(i),不满足(ii)和(iii)。Art.29WP并没有否定各种各样的匿名化技术实现技术,在文中评估了各种技术的优势和缺陷,指出匿名化技术在不同的场景中仍然是降低识别风险重要的措施。同时地,也明确地提出重识别风险的评估重要性。
1.2 日本
《个人信息保护法》:第二条第9款,本法中的“匿名处理信息”(Anonymously processed information) 是指通过处理个人信息而产生的相关信息,它既不能根据采取以下规定的处理措施来识别到特定个人,也无法还原成个人信息。(i) 删除个人信息包含的个人描述部分等 (包括将描述部分替换为其他描述部分,或者使用具有不可恢复的方法等); (ii) 删除所述个人信息中所包含的全部标识符 (包括将标识符替换为其他描述部分,或者使用具有不可恢复的方法等)。
解读:在官网上有一个更为通俗的定义:“匿名处理信息是指,为了不能够识别特定的个人,对个人信息进行加工,并且不能复原个人信息的信息”。这个定义同样采用了“不能识别”和“不能复原”的类似描述,但和欧盟的差别在于没有强调“识别手段”的限制条件是“合理且可能地(reasonably likely)”。那么的匿名处理才能达到“不能识别”和“不能复原”?具体怎么进行匿名处理操作呢?下面这份文件似乎提供了答案。
《个人资料保护委员会秘书处的报告:匿名处理信息》:关于匿名处理信息的处理和适当处理,由第三方组织(即个人信息保护委员会)提供最低标准,而经认可的组织等应制定个人信息保护政策和其他特定的自愿性规则,以及促进相关业务运营商遵守此类规则。期望通过这种措施来确保正确地使用个人数据,从而确保公众的安全感。
解读:该文件明确指出由个人信息保护委员会提供最低标准,同时也给出了具体的一些实践案例与指导。这与欧盟做法不同,欧盟需要自身进行评估,提交报告给相关的管理局;而日本的匿名化处理标准可直接由个人信息保护委员会提供,有一个更为统一和具体的实施标准,匿名处理信息的边界范围更加清晰,实践和操作性更强。
1.3 美国
《加州消费者隐私法案》 (《California Consumer Privacy Act》, 简称《CCPA》):
“去标识” (Deidentified) 指的是信息不能合理地 (reasonably) 识别,关联,描述,被联系在一起,或者说被链接,直接地或间接地,到特定消费者。提供商业使用的去标识的信息(满足)
(1) 已经实现了技术保护措施,并且禁止重识别 (reidentification) 的消费者有关的信息;
(2) 已经实现了明确地禁止信息重识别的业务流程;
(3) 已实施业务流程,以防止因疏忽而发布(reidentification)的信息;
(4) (确保) 未尝试重识别信息;
解读:美国的法规多数没有采用匿名化 (Anonymization) 概念,进而取代使用“去标识化” (Deidentification) 相关概念,如医疗隐私相关法案HIPAA。对于CCPA去标识处理后的结果——去标识信息,与GDPR的匿名信息十分相近,但从以上定义看,存在区别:CCPA强调的“去标识信息”的识别评估手段应该是“合理的”,但没有强调是“可能的”,弱化了某些低概率的识别手段(即低概率发生的识别手段或技术)。因此,可知美国CCPA语境下的“去标识信息”更GDPR的“匿名信息”门槛更低,但这意味着前者存在的“重识别剩余风险”更高。从上述的定义看,CCPA已经将这一类信息的使用方法和范围进行严格限定,一是通过法规限制重识别,另一个是通过技术的措施防止重识别。GDPR和CCPA给出两种完全不同的解决思路:前者处理数据门槛更高,后面的使用范围更宽;后者门槛低,后面的使用范围相对窄一些。这两者具有各自的优势所在。
1.4 中国
《网络安全法》:第四十二条 网络运营者不得泄露、篡改、毁损其收集的个人信息;未经被收集者同意,不得向他人提供个人信息。但是,经过处理无法识别特定个人且不能复原的除外。
解读:上述《网络安全法》的“经过处理无法识别特定个人且不能复原的”描述和“匿名化”(Anonymization)、“去标识化”(De-identification) 的描述,但并未明确对应两者中的哪一个。这些问题尚不明确。在我国的标准,《个人信息安全规范》中给出两者的区别:① 匿名化是通过对个人信息的技术处理,使得个人信息主体无法被识别,且处理后的信息不能被复原的过程;②去标识化 (De-identification) 通过对个人信息的技术处理,使其在不借助额外信息的情况下,无法识别个人信息主体的过程。由此可见,匿名化门槛更高一些。我国在标准中采用了两个概念,但后续法规是使用哪个概念呢?在《数据安全管理办法(征求意见稿)》,两次提出“匿名化”一词,这说明我国法规界对“匿名化”概念的在逐步接受到采纳的过程,但征求意见稿是否保留此概念,值得后续期待。何为“无法被识别”或“不能被复原”?谁来判定匿名化处理后数据的“无法被识别”或“不能被复原”?笔者也希望后续的颁发相关法规和标准能进一步解决两个基础性问题。
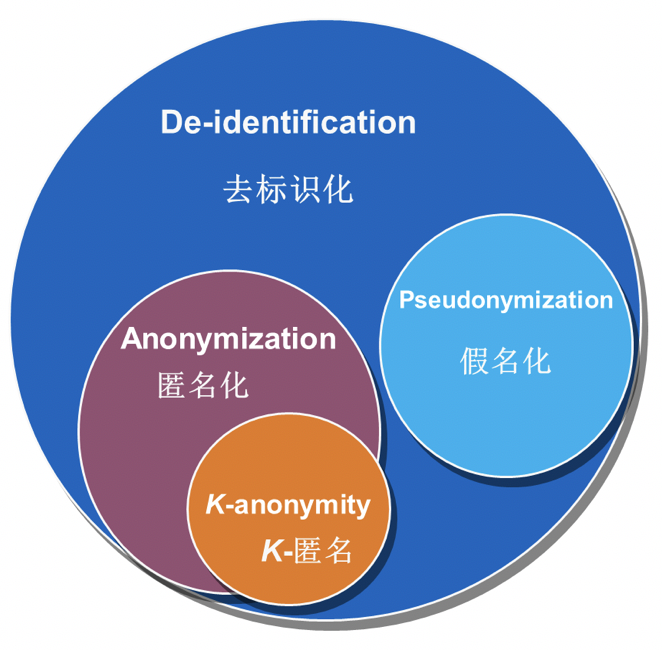
2 匿名化相近概念及辨析
在国内外的数据安全技术标准中,除了匿名化 (Anonymization) 和去标识化(De-identification) 概念外,我们可以看到其他两个较为相近的概念,假名化 (Pseudonymization) 和K -匿名(K-anonymity)。需要说明的是,技术标准强调是技术范畴,是处理过程,实施手段;而法规概念多数强调的处理后得到的结果或者达到的目的,如匿名信息 (Anonymous information)、去标识信息 (Deidentified information)。下面基于国内外标准的几个相关技术概念的定义进行对比和辨析。
2.1 国内标准
《个人信息安全规范》:
匿名化 (Anonymization):通过对个人信息的技术处理,使得个人信息主体无法被识别,且处理后的信息不能被复原的过程。
去标识化 (De-identification) : 通过对个人信息的技术处理,使其在不借助额外信息的情况下,无法识别个人信息主体的过程。
解读:根据这个标准的两个定义:可看出匿名化的门槛(即处理结果的识别评估标准)比去标识化门槛更高。同时,若一个技术属于匿名化技术,那么它一定满足去标识化技术,因此去标识化包括匿名化。
《个人信息去标识化指南》
假名化 (Pseudonymization):假名化技术是一种使用假名替换直接标识(或其它敏感标识符)的去标识化技术。
K –匿名(K-anonymity):K-匿名模型要求发布的数据中,指定标识符(直接标识符或准标识符)属性值相同的每一等价类至少包含K个记录,使攻击者不能判别出个人信息所属的具体个体,从而保护了个人信息安全。
解读:由上看出,假名化和K -匿名一般指的是两种具体的实施技术,它们一定属于去标识化技术的范畴。而K -匿名(K-anonymity)的模型通过K个记录相同,使得攻击者无法识别该记录的“个人信息主体”,可看作实现匿名化的一种理想的手段。K -匿名一定属于匿名化技术吗?笔者认为未必,比如K -匿名中,敏感属性值相同,相当于攻击者实现了“重识别攻击”,因此不满足匿名化的目标。仅代表笔者的观点,欢迎探讨。
2.2 国外标准
《De-Identification of Personal Information》(NISTIR 8053) :
去标识化(De-identification):表示移除一组标识数据和数据主体之间的关联的任何过程的一个通用术语。
解读: NIST定义的“去标识化(De-identification)”目标是“减少信息能够与数据主体关联的程度”而 “无法重识别”“不可复原”(匿名化目标)。在该标准中解释到:使用“去标识化 (De-identification)”一词,是指有时可以实现重识别,有时则不能”。总之,可得出结论:中国和美国的标准中,去标识化的门槛比匿名化的更低,因此范围更广,它们存在包含关系。
《Privacy enhancing data de-identification terminology and classification of techniques》( ISO/IEC 20889) :
假名化 (Pseudonymization) 是去识别化技术的一种,它将数据主体的标识符(或一组标识符)替换为假名,以隐藏该数据主体的身份。
解读:假名化是实现去标识化的一种方法。其将数据主体的标识符(或一组标识符)替换为假名,假名可由随机的替换表、哈希函数、加密算法实现获取。
《Privacy enhancing data de-identification terminology and classification of techniques》( ISO/IEC 20889) :K-匿名 (K-anonymity) 是指一种隐私度量模型,它确保数据集中的每个标识符都有一个对应的等价类,且等价类中至少包含K条记录。
解读:K-匿名同样是实现去标识化的一种方法。它对准标识化进行泛化和处理,使得攻击者无法从准标识进行链接攻击,唯一识别到某个数据主体相关的记录,从而保护了敏感属性。一定程度地说,K-匿名通过数学模型的限制,能相比其他去标识化方法(假名化、加噪)等更能逼近法律的匿名化目标,但它也只是实现匿名化的一个技术手段。
2.3 范畴关系
通过以上的概念比较,笔者认为它们之间的关系可用下图表示。需要进一步解释的是,由于K-匿名模型,比如在某个等价组中敏感属性完全相同,仍然存在隐私属性泄露风险,即可看作实现了“重识别攻击”。因此笔者认为,它不一定满足法规和标准中对匿名化概念的定义。抛砖引玉,欢迎探讨。
3 小结
通过对国外法规标准的研究,可得到以下一些重要结论:
- 欧盟 (GDPR) 和日本 (《个人信息保护法》)在法规中多采用匿名化 (Anonymization) 相关概念;
- 美国的法规(如HIPAA,CCPA)采用去标识化 (De-identification) 的相关概念;
- 美国的CCPA对去标识信息 (de-identified information)定义比欧盟的GDPR对匿名信息 (Anonymous information) 的定义门槛更低,但CCPA对此类数据做了更多的限制,通过法规和技术措施防止重识别;GDPR语境下的匿名信息不是个人信息,不受GDPR的重重管制;
- 欧盟的GDPR的对匿名信息的判定“合理且可能”的识别手段,《关于匿名化技术的意见书》可看出需要企业向相关的管理局提供评估报告。日本的做法与欧盟不同,在《个人信息保护法》及标准明确指出由个人信息保护委员会提供最低标准,标准更加统一且具体。
进一步地,作为一个技术出身的数据安全从业者,十分关注国内的数据安全的法规环境、以及技术动态。通过对比研究,从三个层面发表几点不成熟的意见,抛转引玉,欢迎各位专家探讨:
- 在立法层面:我国在《网络安全法》中并没有明确提出匿名化和去标识化概念,在《数据安全管理办法(征求意见稿)》首次引入“匿名化”概念;但没有给出法规的定义。希望后续的法规《个人信息保护法》、《数据安全法》等能明确匿名化或去标识化概念的具体定义。此外,结合我国大数据以及数据安全的发展现状,借鉴和吸收欧盟和美国对匿名/去标识数据的两种管理方式,在数据利用和数据安全进行平衡,完善匿名化相关制度的设计。
- 在技术层面:两种基础技术。① 开展隐私风险评估技术研究。目前国外已有一些数据集的重识别风险评估研究,我国目前几乎处于空白。目前有多种技术手段,包括数据脱敏、匿名化、假名化和差分隐私等等,去实现法规中的“匿名化”或“去标识化”。然而,那种方法降低的隐私风险更低呢?目前业界缺乏一个统一的评判标准;② 实用可控的匿名化技术研究。目前的技术手段并不能很好应付各种各样的数据开放、共享和发布场景。比如高维数据集,关联关系,效率问题,自适应场景问题,最优平衡等等,均是推动实用化进程中亟需解决的关键性问题。
- 在应用层面:匿名数据/去标识数据的处理和使用,不仅要通过技术防护,也要加强管理措施。如 ① 企业内部的数据共享:个人隐私信息使用假名化技术处理,保留了数据更多的特性,同时对用户的身份信息数据库进行严格访问权限管理,同时严格使用者的使用频次和时间,从各个因素上控制和降低隐私泄露风险;② 企业间的数据共享:数据控制方将包含个人信息的数据外包给第三方,根据需求对数据进行严格的匿名处理手段,同时通过双方签订使用协议,限制通过使用高级技术的实现对个人信息的重识别;③ 数据完全对开放:数据控制方将数据对外发布,由于潜在的风险很大,因此需加强对匿名化处理数据,加强评估力度,通过算法评估指标以及专家抽查等方式反复进行评估,确保风险在控制范围内。
参考文献
[1]《中华人民共和国网络安全法》http://xxzx.mca.gov.cn/article/wlaqf2017/wjjd/201705/20170500891068.shtml
[2]《数据安全管理办法》(征求意见稿)http://www.moj.gov.cn/news/content/2019-05/28/zlk_235861.html
[3]《General Data Protection Regulation》, https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=uriserv: OJ.L_.2016.119.01.0001.01.ENG&toc=OJ:L:2016:119:TOC
[4] Article 29 Data Protection Working Party: Opinion 05/2014 on Anonymisation Techniques
[5] 《個人情報保護法》https://www.ppc.go.jp/files/pdf/290530_personal_law.pdf
[6] 匿名加工情報制度について https://www.ppc.go.jp/personalinfo/tokumeikakouInfo/
[7] 個人情報保護委員会事務局レポート:匿名加工情報,2017,2
[8]《California Consumer Privacy Act》, https://cal-privacy.com/
[9] 王融. 数据匿名化的法律规制[J]. 信息通信技术, 2016, 10(4): 38-44.
[10] 韩旭至. 大数据时代下匿名信息的法律规制[J]. 大连理工大学学报: 社会科学版, 2018, 39(4): 64-75.
[11] 《最高人民法院、最高人民检察院关于办理非法利用信息网络、帮助信息网络犯罪活动等刑事案件适用法律若干问题的解释》http://www.court.gov.cn/fabu-xiangqing-193711.html
附录—原始定义
欧盟GDPR前言26段对匿名化的相关描述:
“The principles of data protection should apply to any information concerning an identified or identifiable natural person. Personal data which have undergone pseudonymisation, which could be attributed to a natural person by the use of additional information should be considered to be information on an identifiable natural person. To determine whether a natural person is identifiable, account should be taken of all the means reasonably likely to be used, such as singling out, either by the controller or by another person to identify the natural person directly or indirectly. To ascertain whether means are reasonably likely to be used to identify the natural person, account should be taken of all objective factors, such as the costs of and the amount of time required for identification, taking into consideration the available technology at the time of the processing and technological developments. The principles of data protection should therefore not apply to anonymous information, namely information which does not relate to an identified or identifiable natural person or to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable. This Regulation does not therefore concern the processing of such anonymous information, including for statistical or research purposes”.
日本匿名报告的英文版 Report by the Personal Information Protection Commission Secretariat: Anonymously Processed Information
https://www.ppc.go.jp/files/pdf/The_PPC_Secretariat_Report_on_Anonymously_Processed_Information.pdf Article 2 (9)对匿名信息的定义:
“Anonymously processed information” in this Act means information relating to an individual that can be produced from processing personal information so as neither to be able to identify a specific individual by taking action prescribed in each following item in accordance with the divisions of personal information set forth in each said item nor to be able to restore the personal information.
(i) personal information falling under paragraph (1), item (i); Deleting a part of descriptions etc. contained in the said personal information (including replacing the said part of descriptions etc. with other descriptions etc. using a method with no regularity that can restore the said part of descriptions etc.)
(ii) personal information falling under paragraph (1), item (ii); Deleting all individual identification codes contained in the said personal information (including replacing the said individual identification codes with other descriptions etc. using a method with no regularity that can restore the said personal identification codes)
美国CCPA对去标识信息的定义
“Deidentified” means information that cannot reasonably identify, relate to, describe, be capable of being associated with, or be linked, directly or indirectly, to a particular consumer, provided that a business that uses deidentified information:
(1) Has implemented technical safeguards that prohibit reidentification of the consumer to whom the information may pertain.
(2) Has implemented business processes that specifically prohibit reidentification of the information.
(3) Has implemented business processes to prevent inadvertent release of deidentified information.
(4) Makes no attempt to reidentify the information.