使用机器学习方法检测SQL注入,往小方面说是能够识别出SQL注入流量,往大方面说是检测WEB异常流量,能够检测SQL注入、XSS、恶意POC等异常流量,完成WAF的功能。
一、背景
使用机器学习方法检测SQL注入,往小方面说是能够识别出SQL注入流量,往大方面说是检测WEB异常流量,能够检测SQL注入、XSS、恶意POC等异常流量,完成WAF的功能。
传统web入侵检测技术通过维护规则集对入侵访问进行拦截。一方面,硬规则在灵活的黑客面前,很容易被绕过,且基于以往知识的规则集难以应对0day攻击,规则写的太宽泛易误杀,写的太细易绕过。
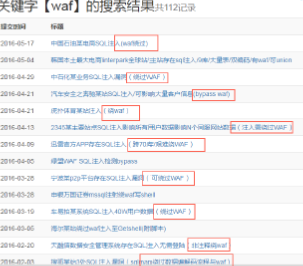
图1 黑产高价收购WAF绕过方式,完全绕过的价格可达到一万+
另一方面,攻防对抗水涨船高,防守方规则的构造和维护门槛高、成本大。规则库维护困难,人员交接工作,甚至时间一长,原作者都很难理解当初写的规则,一旦有误报发生,上线修改都很困难。
基于机器学习技术的新一代web入侵检测技术有望弥补传统规则集方法的不足,为web对抗的防守端带来新的发展和突破。机器学习方法能够基于大量数据进行自动化学习和训练,已经在图像、语音、自然语言处理等方面广泛应用。
然而,机器学习应用于web入侵检测也存在挑战,其中最大的困难就是标签数据的缺乏。尽管有大量的正常访问流量数据,但web入侵样本稀少,且变化多样,对模型的学习和训练造成困难。


目前大多数web入侵检测都是基于无监督的方法,针对大量正常日志建立模型,而与正常流量不符的则被识别为异常。这个思路与拦截规则的构造恰恰相反。拦截规则意在识别入侵行为,因而需要在对抗中“随机应变”;而基于模型的方法旨在建模正常流量,在对抗中“以不变应万变”,且更难被绕过。
二、技术思路
机器学习模型较为重要的是收集数据和特征工程,“特征工程”是机器模型中最重要的一部分,往往依赖于专家的“直觉”和专业领域经验,机器学习有句话经常被提起,“特征工程决定了现有数据的预测能力上限,好的模型能逼近这个上限”,所以机器学习的价值体现在提炼出传统行业的数据特征,并用最合适的算法优化提升目前的水平。
目前建立模型主要有以下几种思路:
1.基于数据统计的模型
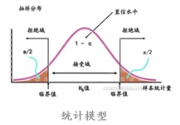
基于统计学习的web异常检测,通常需要对正常流量进行数值化的特征提取和分析。特征例如,URL参数个数、参数值长度的均值和方差、参数字符分布、URL的访问频率等等。接着,通过对大量样本进行特征分布统计,建立数学模型,进而通过统计学方法进行异常检测。
2.基于文本分析的机器学习模型
可以借鉴NLP中的一些方法思路,进行文本分析建模。
1)基于隐马尔科夫模型(HMM)的参数值异常检测。
2)基于TF-IDF的异常检测

本文使用此思路
- 先取得URL里的关键词列表
- 用 scikit learn的 TfidfVectorizer函数把每个URL里的关键词做TF-IDF得到向量化的特征
- 用 LogisticRegression 模型训练并进行评价。
3)基于词法分析和语法分析
在BlackHat2012会议中提出的libinjection使用了词法分析,这种方法应用的代表是长亭科技的SQLChop,现在已经整合到雷池Web应用防火墙
4)基于色谱样熵分析(Chromatography-Like Entropy Analysis)
比较另辟蹊径的方法,通过信息论中的熵值,提取文本特征
3.基于单分类模型
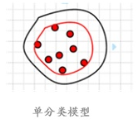
由于web入侵黑样本稀少,传统监督学习方法难以训练。基于白样本的异常检测,可以通过非监督或单分类模型进行样本学习,构造能够充分表达白样本的最小模型作为Profile,实现异常检测。
4.基于聚类模型

通常正常流量是大量重复性存在的,而入侵行为则极为稀少。因此,通过web访问的聚类分析,可以识别大量正常行为之外,小搓的异常行为,进行入侵发现。
三、建模与测试
首先对数据进行预处理
import numpy as np
import urllib
# 数据预处理
def getQueryFromFile(filename='badqueries.txt'):
directory = "C:\\fwaf"
filepath = directory + "\\" + filename
data = open(filepath,'r').readlines()
data = list(set(data))
queries = set()
for d in data:
d = d.strip()
try:
d = str(urllib.unquote(d).decode('utf8')) #converting url encoded data to simple string
queries.add(d)
except:
print 'decode ' + d + ' error'
return list(queries)
badQueries = getQueryFromFile('badqueries.txt')
tempvalidQueries = getQueryFromFile('goodqueries.txt')
tempAllQueries = badQueries + tempvalidQueries
ybad = np.ones(len(badQueries))
ygood = np.zeros(len(tempvalidQueries))
y = np.hstack((ybad, ygood))
queries = tempAllQueries
构造3-gram特征,使用TF-IDF提取URL文本特征,并进行文本向量化
#tokenizer function, this will make 3 grams of each query
#构造3-gram特征
def getNGrams(query):
tempQuery = str(query)
ngrams = []
for i in range(0,len(tempQuery)-3):
ngrams.append(tempQuery[i:i+3])
return ngrams
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cross_validation import train_test_split
#converting data to vectors
#TF-IDF
vectorizer = TfidfVectorizer(tokenizer=getNGrams)
X = vectorizer.fit_transform(queries)
将这个数据集分成训练数据集和测试数据集两部分,然后用逻辑回归算法来训练。但此处先进行TD-IDF处理后再进行数据集分割训练,会导致数据泄露问题,使分数虚高,丢失了许多数据原有的信息,而且使用原有的训练集作为测试集,也会导致分数虚高。所以此算法的缺点在于缺乏泛化能力,对没有训练过的SQL注入语句或者web异常语句检测能力较低,一种解决方法是扩大训练集的样本数,尽可能多的覆盖常用注入手法。或者使用其他算法提取特征,比如在BlackHat2012会议中提出的libinjection使用了词法分析。此处得到的score是0.997874451441。
#splitting data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) from sklearn.linear_model import LogisticRegression lgs = LogisticRegression() lgs.fit(X_train, y_train) #training our model print(lgs.score(X_test, y_test)) #checking the accuracy
最后测试一些例子
X_predict = [
'AND 1=1',
'ORDER BY 1-- ',
'<script>alert(xss)</script>/',
'and (select substring(@@version,1,1))=\'X\'',
'www.baidu.com',
'<?php @eval($_POST[\'c\']);?>'
]
X_vecpredict = vectorizer.transform(X_predict)
y_Predict = lgs.predict(X_vecpredict)
#printing predicted values
mapvalues={1:'Bad ',
0:'Good'}
for i in range(len(X_predict)):
print mapvalues[y_Predict[i]]+':'+X_predict[i]
Bad :AND 1=1结果是
Bad :ORDER BY 1-- Bad :<script>alert(xss)</script>/ Bad :and (select substring(@@version,1,1))='X' Good:www.baidu.com Bad :<?php @eval($_POST['c']);?>
四、总结与展望
本文介绍了机器学习用于web异常检测的几个思路,并使用文本分析方法3-gram 和TD-IDF提取特征,然后使用LogisticRegression算法训练。
web流量异常检测只是web入侵检测中的一环,用于从海量日志中捞出少量的“可疑”行为,但是这个“少量”还是存在大量误报,只能用于检测,还远远不能用于WAF直接拦截。一个完备的web入侵检测系统,还需要在此基础上进行入侵行为识别,以及降低误报等环节。
在网络安全中,机器学习还可以用来:
1.C&C随机域名检测
2.恶意URL检测(可以参考新加坡大学的一个团队综述https://arxiv.org/abs/1701.07179)
3.UGC违规图片与评论 机器学习在安全领域的广泛应用还有很长的路要走。
参考链接:
[1]https://zhuanlan.zhihu.com/p/25139556
[2]https://github.com/faizann24/Fwaf-Machine-Learning-driven-Web-Application-Firewall