现在主要进行PHP方面的开发. 开发过程中发现产品代码中, 很多xml文件的解析都是先创建DOM对象读取文件, 然后进行对象的遍历, 填充数组, 最后对数据进行操作。
来公司前做Java Web, 对PHP不是很了解, 所以想着有没有能省事点的方法, 不用每次都做那么多工作才能得到想要的数据. 问了下度娘后, 发现了XPath, 语法类似sql形式, 简单易懂, 上手难度不高, 下面直接上真相(多图) 。
XPath:我很强

- SimpleXML和DOM均支持XPath
- XPath可以返回SimpleXML对象的数组
- 返回结果可以不遍历直接使用
- XPath支持类似sql的写法
- 语法简单易上手……
- 编不下去了, 更多详情可参考w3school, 此处省略500字
通俗易懂好上手
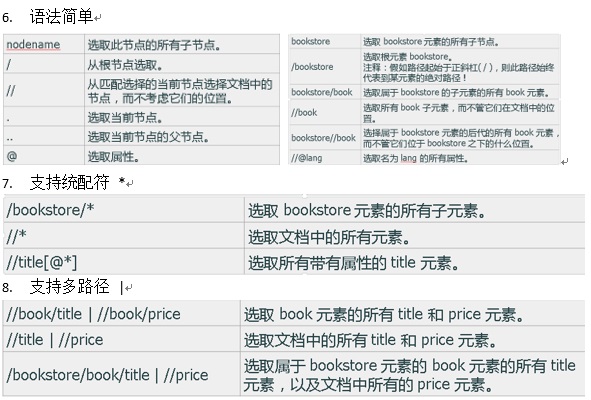
有图有真相
(路径里的eat不是重点…不要在意细节)

生产力
入职的产品任务实践是用公司的web框架(PHP), 做一套具备增删查改/分页/模糊查询/国际化功能的程序. 整套程序的关键点是分页, 因为设备现有的分页模块处理大数据量的xml文件时会比较慢, 参考在学校做JavaWeb的分页思路, 就重新做了一套分页.
利用XPath的谓词表达式和函数, 可以对数据量的选取进行限制, 实现每次只加载所需位置的数据元素. 同时, 对字符进行模糊匹配, 实现xml文件的全局查找.
实测新的分页方式在首次加载数据时, 大幅缩小了等待时间, 下面是真相.
- 原分页, 首次等待时间

- 新分页, 首次等待时间

笔者的测试环境性能比较低(atom 1.8G), 高性能设备的数据可能不一样, 但是从原理上讲肯定会有提升.
XPath还有很多好玩的函数, 在这就不一一列举了。
如果您需要了解更多内容,可以
加入QQ群:570982169、486207500
直接询问:010-68438880-8669