1.6.2030年AI发展前景:
-
情景1:发展停滞
AI能力基本保持不变。近年来的快速发展陷入停滞。
情景描述:到2030年,AI能够快速完成一系列人类需要数小时才能完成的任务,但稳健性不足和幻觉问题影响了AI的可靠性。AI通常需要大量的人工支持才能完成任务,例如详细的提示、审核和上下文。AI缺少学习新技能或形成记忆、在较长的复杂任务中保持连贯性的能力,还缺少与动态现实世界或社会环境互动的稳健能力。
发展路径:2025年后,现有前沿AI模型的开发方法受到了根本性限制。导致AI发展放缓的原因可能有以下几点:更大规模的训练运行和更强大的推理系统带来的回报递减;获取计算资源或其他关键投入的限制;AI投资的大幅下降;缺乏重大的算法突破。
-
情景2:发展放缓
在现有AI训练方法框架内实现渐进式增长,发展持续但速度放缓。
情景描述:到2030年,AI相当于人类的得力助手。AI拥有深厚的知识库,擅长标准形式的结构化推理,能够有效地执行需要使用计算机、浏览网络或代表用户与他人或服务进行有限互动的任务。AI可以保留相关记忆、保持连贯的思维,通过纠错来完成更长或更复杂的任务。但AI缺乏学习新技能的稳健能力,只能在有限的受控环境中(如工厂或实验室)处理现实任务。
发展路径:2025年后,前沿AI模型研发人员的技术难以克服在持续学习、元认知与能动性、问题解决、创造力、现实任务和社会互动等方面的限制,现有训练范式无法提供完美的解决方案。预训练、推理和训练后处理的技术扩展,再加上算法创新,将继续推动发展,但发展速度将低于近年来的水平,且推理系统的泛化能力未能达到预期。由于投资者从持续投资中看到的回报降低,继续扩展的能力受到阻碍。硬件、基础设施、自然资源、数据供应和能源方面的瓶颈限制了算力和数据的快速扩展。
-
情景3:持续发展
发展持续快速推进。
情景描述:到2030年,AI可与专业人员协作。AI能够成功完成虚拟环境中人类需要一个月才能完成的许多专业任务。AI通常需要人类提供专业指导,但往往能够高度自主地朝着既定目标工作,包括自主与多个相关方交互。AI可以有效地形成和检索记忆,在一定程度上实现边做边学,能够成功处理受控环境之外的现实任务和实际的具体任务。
发展路径:2025年后,通过更大规模的训练运行、更强大的推理系统和新的算法创新,AI能力将继续快速发展。算力和数据投入将继续扩展,在2030年前不会遇到实质性限制,与当前对持续发展的范围估计一致。对现有技术的迭代和扩展,或新的算法创新,将使研发人员能够突破当前在持续学习等方面的限制。
-
情景4:加速发展
AI能力取得巨大突破,在大多数或所有能力上达到或超过人类水平。
情景描述:到2030年,AI相当于人类水平的远程工作者。AI的自主性和认知能力在认知任务上达到或超过人类。AI能够熟练且自主地朝着广泛的战略目标努力,能在环境变化时反思和调整目标,同时在必要时与人类合作。AI可以在部署过程中无缝学习新的信息和技能。AI机器人能够处理现实世界中许多行业和岗位上的复杂任务。但由于实际任务范围较广,AI在这些任务中的表现总体上仍落后于人类,除非是为特定任务专门开发。
发展路径:2025年后,通过持续或加速的预训练、训练后处理和推理技术扩展,现有范式内的AI能力水平将继续呈指数级增长。重大的算法突破以及AI编码助手对AI发展日益重要的贡献,将进一步促进能力的增长。
决策者面临的挑战
预测方面的挑战加剧了能力发展轨迹的不确定性,针对不同的发展轨迹,需要制定截然不同的政策措施。如果算法技术按照当前估计的上限继续发展,到2030年,AI可能只需1/10至1/100的算力就能实现同等能力。因此,监管机构需要考虑能够适应或稳健应对AI发展速度以及AI发展(尤其是所需资源方面)快速变化的框架。为了减少不确定性,决策者应监测具体指标,包括对现实世界任务的评估、算法创新速度以及AI能力的涌现。
2 风险
2.1.恶意利用风险
2.1.1.AI生成内容用于犯罪活动
决策者面临的挑战
2.1.2.网络攻击
- AI可贯穿网络攻击全阶段
大量研究表明,AI可以在网络攻击的多个阶段中为攻击者提供支持(见图2.1)。在典型的攻击中,攻击者首先识别目标和漏洞,开发和部署攻击能力,最后保持持续访问以达到数据窃取或系统破坏等目的。软件工程等相关AI能力的进步引发了人们的担忧,AI可能会同时增加网络攻击的频率和严重程度。
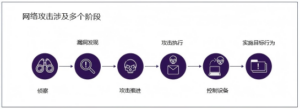
- 网络攻击的自动化程度
完全自动化的网络攻击将消除需要人类参与的限制,攻击者可能发起更大规模的攻击。AI现在可以自主完成越来越多的任务。2025年11月,AI研发人员报告称,攻击者利用他们的AI模型使入侵过程中80-90%的工作自动化,人类仅在关键决策点进行干预。研发人员还证明,AI可以在实验室环境中独立探查计算机网络的安全漏洞。但暂时没有AI在现实中实施端到端网络攻击的报告。
研究表明,自主攻击仍然受到限制,AI无法可靠地执行漫长的多阶段攻击过程。例如,AI表现出的异常包括执行无关命令、忘记操作状态以及在没有人类干预的情况下无法从简单错误中恢复。
由于这些限制,人机协作仍然是研究和实践中网络行动的主导模式。在这种模式下,人类提供战略指导,将复杂操作分解为可管理的子任务,在AI遇到错误或产生不安全输出时进行干预。同时,利用AI使代码生成或目标识别等技术子任务自动化。
- AI对攻击的影响尚不明确
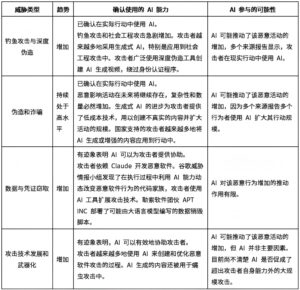
AI推动了攻击速度和规模的提升,但对攻击频率的影响尚不明确。威胁情报报告记录了AI参与的凭证窃取、自动化扫描和供应链攻击等多种类型的攻击(见表2.1)。迄今为止,AI能力主要体现在加速或扩展现有攻击方法的发展,而非提供新的攻击方式。但很难确定AI的助力与攻击的增加是否存在必然的因果关系。观察到的攻击频率增加可能反映了AI的辅助作用,但也可能是由于检测能力的提高。
许多用于网络攻击的AI技术也能增强防御能力,所以更难以判断AI对攻击者还是防御者更有利。例如,AI技术可以让攻击者快速发现漏洞,也可被防御者用于率先发现并修复漏洞。AI研发企业宣布推出AI安全智能体,主动识别和修复软件漏洞。研究人员还指出,AI可以帮助强化数字环境,通过重写大型代码库提高安全性。与此同时,改进的评估方法有助于评估攻击能力。在部署新的AI之前对其进行评估,及早发现并预警新出现的风险。有研发人员在网络安全和生物研究等敏感领域引入了新的控制措施,限制某些产品的访问权限,仅允许经过审查的组织访问。
AI在攻击和防御作用之间的平衡如何演变,部分取决于模型访问、研究经费和部署标准的选择。例如,由于缺乏AI工具的标准质量保证方法,防御者难以在需要可靠性的关键领域采用AI工具,而攻击者则不受此类限制。
自2025年以来,评估和竞赛结果表明,AI的能力有所提高,有证据表明,攻击者利用AI在现实世界中实施网络攻击的情况已经出现。例如,AI在漏洞发现方面的能力表现较强。AI开发人员也越来越多地报告,攻击者(包括国家支持的攻击者)正在使用AI实施网络攻击行动。