

一、FATE整体架构
FATE是首个工业级的开源联邦学习框架,据中国信通院数据显示,55%的国内隐私计算产品是基于或参考了开源项目,其中以FATE开源项目为主。FATE实现了基于同态加密和安全多方计算的安全协议。FATE支持横纵向联邦学习场景,包含了多种联邦学习算法,包括逻辑回归、secure boost、深度学习等。FATE提供了联邦学习全流程的解决方案,具备开箱即用的特点。FATE整体架构和基本流程如下图1、2所示,本篇文章将主要介绍联邦学习任务调度的核心: FATE-Flow。
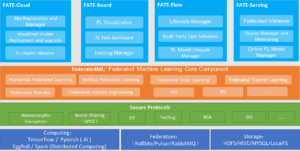
图1:FATE整体架构
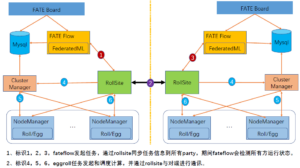
图2:FATE流程
二、FATE–Flow架构
FATE-Flow提供了端到端的联邦学习任务流水线管理模块,架构如图3所示。
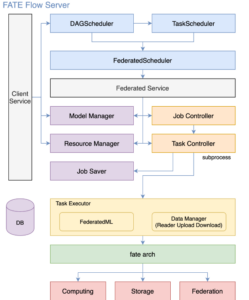
图3:FATE-Flow流程
在FATE-Flow中,由如下几个关键模块:
- DAG:定义了流水线,使用JSON格式的DSL来定义DAG。
- DSLParser:是调度的核心,通过 DSL parser 解析到上下游关系及依赖。
- Job Scheduler:一个DAG作为一个Job,而DAG中的节点称为Task,一个Job由若干Task组成。
- Task Controller:最小的调度单位,FATE-Flow将Task的执行独立为隔离的进程。
- DataManager:用作数据的上传、下载等。
- Resource Manager: 负责计算整个Job需要的资源的大小,返回资源申请状态等。只有多方资源申请成功,才会向各方发送startjob指令。
提交一个Job的流程如下:Job首先提交到Queue中,JobScheduler解析DAG加入到Task Queue中,调度 Executor执行,同时这个任务会分发到联邦学习的各个参与方。在任务执行中会收集参与方状态,进行下一步的调度。Task stat记录Task的状态信息,例如启动时间、运行状态、结束时间、超时时间等。如果Task运行时间超过默认超时时间、异常终止或者正常运行,则启动shutdown,结束进程,清理任务,同步到所有联邦参与方,保证任务的一致性。
三、源码分析
FATE-Flow后端使用的是Flask,Flask是一个轻量级的python web框架,FATE-Flow server的程序入口是在python/fate_flow/fate_flow_server.py。如图4所示,通过源码分析,我们发现启动了两个server:9380端口的http server 和9360端口的grpc server。http接口用作自身api的调用,而grpc 则用作参与方间函数调用。
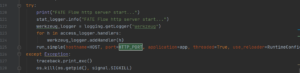
图4:Flask启动http server
熟悉Flask的朋友都知道,Flask使用蓝图来组装不同的组件,在Fate-Flow server中同样如此。在apps目录下构成了后端程序的基本组件,其中主要包含:
- checkpoint_app: 数据/模型更新
- py:获取组件详情,验证组件参数
- py:数据上传及下载
- py:获取mysql、fateboard、eggroll版本信息
- py:核心,提供job、task、查询等接口
- py:数据表的操作,通过mysql导入数据也是在这里完成的
- py:获取组件的状态,包括获得组件的输出也是在这里完成的
- py:显示FATE相关版本信息,其中docker-compose部署healthy检查就是通过此接口。
- py:负责log相关接口,解决了之前版本中fateboard无法获取部分log的bug
- py:权限控制相关接口
- py:模型下载、部署,用作在线推理
3.1 轮询检测与调度
如图5所示,Detector每5s执行一次,负责检测运行中、结束的Job、Task、资源等;而DAGScheduler每2s执行一次,依次调度waiting、running、ready、rerun状态的Job,更新结束 Job的状态。
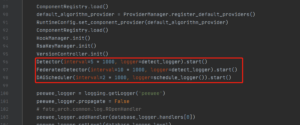
图5:两个轮询方法
- 从提交Job分析源码
job_app接收请求
用户通过flow client cli提交任务,其实是向FATE-Flow server的9380端口发送http请求,在job_app中接受请求后,调用DAGScheduler.submit。
DAGScheduler提交Job
如图6所示,DAGScheduler的submit方法生成Job id,进行Job相关配置,调用FederatedScheuler.create_job方法通知各方创建Job。这一步实际上是调用了federated_command 方法,通过grpc向各参与方发送rpc或http请求。initiator为每一方、每一个task初始化,并记录在数据库中(见t_tack表)。如果均未出错,则将Job的状态设置为WAITING。

图6:发送http或rpc请求各方创建Job
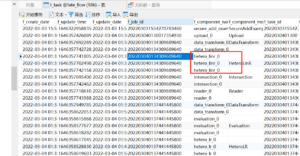
图7:initiator记录Task信息
DAGScheduler调度waiting的Job
在2.1 节中我们提到过,DAGScheduler每2s一次调度Job。对于waiting状态的Job,DAGScheduler首先检查Job的状态是否被取消,然后尝试在各方申请资源,如果资源申请成功则调用start_job开始Job,向各个参与方发送开始Job的请求。各个参与方在收到请求后,将Job状态改为RUNNING。
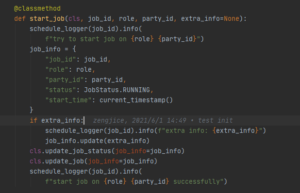
图8:各参与方开始Job
DAGScheduler调度running的Job
对于running状态的Job,实际调用的是TaskScheduler.schedule方法,在该方法中,获取所有Task,并将Task的状态同步。对于WAITTING状态的Task,调用start_task方法开启Task。initiator 向各方发送start task的rpc请求。

图9:向各方发送start_task请求
TaskController执行Task
在收到start_task的rpc请求后,各方调用TaskController的start_task方法,对于eggroll引擎来说,实际上是启动python子进程。
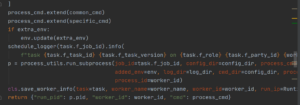
图10:启动python子进程
计算Task、Job状态
在完成Task后会计算各参与方的状态,如图11所示,分为以下几种情况:全部都是waiting状态、存在interrupt状态、存在running状态、waiting和success状态、全部都是end状态。
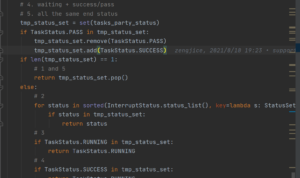
图11:状态计算
四、结语
如果说FederatedML是大脑,那么FATE-Flow就是骨架。FATE-Flow从整个任务生命周期的管理,到上层对外暴露API结构,在整个联邦学习中起着举足轻重的作用。无论是各个厂商在开发自家的隐私计算平台,还是个人用户使用命令行工具,其实都是在与FATE-Flow server打交道。在最新的1.9版本中,FATE-Flow也增加了新的功能:例如授权认证、负载均衡等。由于篇幅所限,本文仅从Job提交的角度来分析FATE-Flow的流程,感兴趣的同学也可阅读相关源码。
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。