一、前言:经典的词/句向量嵌入
在自然语言处理(NLP)领域,词/句向量嵌入方法的使用已有许多年的历史。能够捕捉到单词或句子的含义,并将其转换为具有固定长度的嵌入向量,非常好地解决了大多数机器学习模型不擅长应对可变长输入数据,而无法应用到NLP领域的问题。

图1:Word2Vec嵌入后的词向量可以进行加减计算,例如(king-man+woman≈queen)[1]
通过设置一个中间的训练目标,我们可以充分利用无标签的数据,极大增强模型解决最终目标问题的性能。
类似的方法能够使用在安全告警评估的过程中吗?
二、告警评估中的应用前景
大多数IDS、WAF等检测防护系统产生的告警都包含告警载荷,其内容通常是被怀疑为攻击行为的网络流量的片段。
它和自然语言一样,是由若干个具有明确含义的“单词”构成的不定长序列,而且各个“单词”之间存在一定的上下文关联关系。
通过观察人类专家对告警分诊的过程可见,告警载荷的内容对告警性质的研判具有至关重要的作用,将其认定为评估过程中最关键的字段也不为过。
在NLP领域适用的大多数分析方法,在告警评估中理应也能使用,目前比较受到瞩目的应用方向包括:
2.1 告警载荷特征提取
词/句向量嵌入方法能够从自然语言文本中取得固定长度的、能够用于表示文本含义的特征向量。
但目前为止,绝大多数告警评估方法都倾向于忽略告警信息中的非结构化字段,首当其冲被忽略的就是告警载荷的内容。
如果嵌入方法能够提取出告警载荷的有效信息,就可以为目前的各种告警评估方法补充新的有价值的特征,这或将大大提高告警评估的准确性。
2.2 告警载荷摘要
在NLP领域中,文本摘要的提取/生成已经是一个非常成熟的技术方向了,给定一篇新闻稿,全自动地为其写出一篇简短的摘要,早已不是什么难事。
类似地,对于安全运营人员来说,完整的告警载荷实在过于冗长,并充斥着大量和网络攻击没什么关系的字段内容。
如果能够将告警载荷中比较重要的部分提取出来,无疑能够大大提高告警研判的效率。
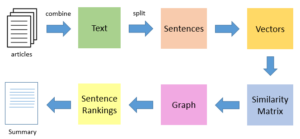
图2:TextRank文本摘要算法流程,通过句向量嵌入后,求相似度构图运行PageRank算法,选择出最具代表性的句子[8]
2.3 告警载荷基线和攻击检测
拼写纠错也是NLP技术的常见应用。给定一段文本,通过HMM、CRF或其它方法,模型可以标记出文本中可能存在拼写错误的位置,还能提供相对合理的候选文本。
初步实验表明,类似的方法对一些网络攻击的检测可能也是有效的。例如,SQL注入攻击可能会在长度数千字节的HTTP请求中添加一个单引号,这对于很多特征方法来说都是微不足道的变化,但却难以逃避拼写纠错的检测。
不过,目前尚无充分研究证明,这种基于词向量嵌入的序列异常检测方法在告警评估中表现更优。
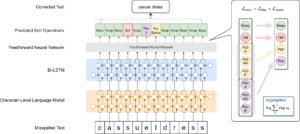
图3:用于短文本拼写错误纠正的分层字符标记器模型,预测目标为对文本中每个字符位置应进行的编辑(纠正)操作[9]
三、现有技术的难点
告警载荷毕竟不是自然语言,想要将NLP领域的方法原封不动地搬运到告警评估过程中,并没有看上去那么简单。
3.1 清洗和切词
不同于自然语言,告警载荷并不遵循统一的语法,而是各种各样的网络协议。
我们姑且可以利用一些成熟的函数库来解析常见的网络协议,但考虑到信息系统业务的复杂性,以及一些通过违背协议实现的攻击方式和其它业务故障产生的畸形流量,这种方法并不总是可靠。
例如,即使按照HTTP协议规范解析出各个URL参数,实际攻击中的单个参数值可能包含大段漏洞利用代码,将这样的参数值整体视为一个“单词”元素,显然是不合理的,会极大影响模型的泛化能力。
不仅如此,告警载荷中往往还包括很多与攻击和业务都没有什么关系的无用信息,甚至往往比有用的信息还要多得多。如果不能提前将它们剔除,也会极大增加模型训练的难度。
综上,对告警载荷进行清洗和切词无疑是一大难关。

图4:自然语言的切词也有很多难点,比如汉字中的多音字,如果不考虑上下文,对单个文本的切词可能同时存在多个解[10]
3.2 Tokenization和词表构建
不同于一般的自然语言处理,对告警载荷进行分析的首要目的是从中识别攻击行为。
我们可以在媒体网站上收集大量的新闻稿来训练语言模型。我们可以假设,新闻稿中包含的单词就是这种语言的全部单词。如果某个单词在所有新闻稿中从未出现,通常不外乎临时出现的专名、拼写错误等等,很多场景下甚至可以直接忽略。
类似的,我们也可以在业务环境中收集大量的告警载荷来训练模型。但此时不同的是,如果某个单词在历史告警中从未出现,显然不能直接认定它的意义不大,尤其需要担心它是不是来自某种新型攻击方式。
因此,在告警载荷分析的过程中,想要建立一个有限集合的词表是非常困难的。
3.3 预训练模型
BERT及其各种变种模型之所以效果强劲,一个非常重要的原因就是对预训练模型的迁移。所有人都可以轻松下载到那些投入海量数据和算力才得到的预训练模型,然后再稍加修改并应用到各自的下游任务中去。
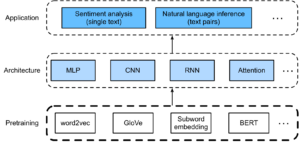
图5:NLP领域的预训练和迁移学习流程,同样的预训练模型可以迁移到不同的应用场景中[11]
然而众所周知,关键告警都是罕见的,大多数告警都是低价值的。这导致各种自监督的预训练方法在告警载荷处理中受到一定的局限,因为它们往往更多地学习到大多数样本的分布。
此外,不同网络环境中的告警分布也是天差地别。在一个普遍使用SSH的网络环境中,Telnet连接可能会被怀疑是后门或配置不当;而在一个普遍使用Telnet的网络环境中,SSH连接反而会被怀疑是加密代理。
结果,我们就需要准备大量的、带标注的、符合当前网络和业务环境的攻击和业务告警样本来训练模型——听起来倒是没什么难度,如果不考虑高昂的成本的话。
四、后记
综上所述,词/句向量嵌入方法在告警评估领域理应具有光明的前景,但还有一些基础性的问题需要解决。
更多前沿资讯,还请继续关注绿盟科技研究通讯。
如果您发现文中描述有不当之处,还请留言指出。在此致以真诚的感谢~
参考文献
[1] CHAMBERS N. SI425 Natural Language Processing [J/OL] 2020, https://www.usna.edu/Users/cs/nchamber/courses/nlp/f20/labs/lab5/index.html.
[2] FAITH. 从word2vec到Bert的演变 [J/OL] 2022, https://zhuanlan.zhihu.com/p/463766834.
[3] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. ICLR Workshop, 2013
[4] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean. Distributed Representations of Words and Phrases and their Compositionality. NIPS 2013
[5] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [J]. Advances in neural information processing systems, 2014, 27.
[6] DEVLIN J, CHANG M-W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding [J]. arXiv preprint arXiv:181004805, 2018.
[7] YANG Z, DAI Z, YANG Y, et al. Xlnet: Generalized autoregressive pretraining for language understanding [J]. Advances in neural information processing systems, 2019, 32.
[8] PYTHON语音识别-公众号. 使用TextRank算法进行文本摘要提取(python代码) [J/OL] 2018, https://blog.csdn.net/m0_37700507/article/details/84726463.
[9] GAO M, XU C, SHI P. Hierarchical Character Tagger for Short Text Spelling Error Correction; proceedings of the WNUT, F, 2021 [C].
[10] ZHANG N, LI F, XU G, et al. Chinese NER using Dynamic Meta-Embeddings [J]. IEEE Access, 2019, PP: 1-.
[11] ZHANG A, LIPTON Z C, LI M, et al. Natural Language Processing: Pretraining [J/OL] 2022, https://d2l.ai/chapter_natural-language-processing-pretraining/index.html.
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。