文本分类是自然语言处理中一个很经典也很重要的问题,它的应用很广泛,在很多领域发挥着重要作用,例如垃圾邮件过滤、舆情分析以及新闻分类等。和其他的分类问题一样,文本分类的核心问题首先是从文本中提取出分类数据的特征,然后选择合适的分类算法和模型对特征进行建模,从而实现分类。当然文本分类问题有具有自身的特点,例如文本分类需要对文本进行分词等预处理,然后选择合适的方法对文本进行特征表示,然后构建分类器对其进行分类。本文希望通过实践的方式对文本分类中的一些重要分类模型进行总结和实践,尽可能将这些模型联系起来,利用通俗易懂的方式让大家对这些模型有所了解,方便大家在今后的工作学习中选择文本分类模型。
文本分类算法模型
传统文本分类方法
传统的文本分类方法最早可以追溯到上世纪50年代,当时主要通过专家规则(Pattern)的方式进行分类,后来发展为专家系统,但是这这些方法的准确率以及覆盖范围都很有限。
后来随着统计学习的发展以及90年代互联网文本数据的增长和机器学习研究的兴起,逐渐形成了一套解决大规模文本分类问题的经典方法,其特点是主要依靠人工特征工程从文本数据中抽取数据特征,然后利用浅层分类模型对数据进行训练。训练文本分类器的主要过程如下:
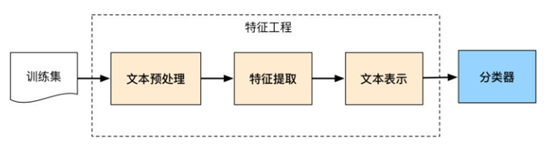
由此文本分类问题被拆分成特征工程以及分类器,其中特征工程有分成了文本预处理、特征提取以及文本表示三个步骤。在利用机器学习解决问题过程中,特征工程往往是最重要也是最费时的一个环节,实际上机器学习问题需要把数据转换成信息然后转换为知识。特征是数据的表征,对数据表征的好坏直接影响了结果,也就是说特征表征的好坏直接影响了结果的上限,而分类器是将信息转换为知识的手段,仅仅是逼近上限的一种方法。特征工程更特殊的地方在于需要结合特定的任务和理解进行特征构建,不同的业务场景下特征工程是不同的,不具备通用的方法。因为计算机能够直接理解和处理的是数字型变量,而文本想要转换成计算机理解的语言,同时具备足够强的表征能力。首先需要进行文本预处理,例如对文本进行分词,然后去停词。停用词是文本中对文本分类无意义的词,通常维护一个停用词表,特征提取过程中删除停用表中出现的词。特征选择的主要方法是根据某个评价指标独立的对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有文档频率、互信息、信息增益等。此外经典的TF-IDF方法用来评估一个字词对于文档集或者语料库的一份文章而言的重要程度,是一种计算特征权重的方法,其主要思想是字词的重要性与他在文档中出现的次数成正比,与他在语料库中出现的频率成反比。
文本表示是希望把文本预处理成计算机可理解的方式,文本表示的好坏影响了文本分类的结果。传统文本表示方法有词袋模型(BOW, Bag Of Words)或向量空间模型(Vector Space Model)。词袋模型的示例如下:
( 0, 0, 0, 0, …. , 1, … 0, 0, 0, 0)
我们对词采用one-hot编码,假设总共N个词,构建N维零向量,如果文本中的某些词出现了,就在该词位置标记为1,表示文本包含这个词。但是通常来说词库量
至少都是百万级别,因此词袋模型有个两个最大的问题:高维度、高稀疏性。在词袋模型的基础上出现了向量空间模型,向量空间模型是通过特征选择来降低向量的维度,并利用特征权重计算增加稠密性,缓解了词袋模型高维度高稀疏性的问题。
然而这两种模型都没有考虑文本的语义信息,也就是说文本中任意两个词都没有建立联系,通过向量无法表示词和词之间的关系,这实际上是不符合常理的。
深度学习文本分类方法
介绍了传统的文本分类做法发现主要问题在于文本表示是高维度高稀疏的,因此特征表达能力比较差;此外传统文本分类需要人工特征工程,这个过程比较耗时。应用深度学习解决文本分类问题最重要的是解决文本表示,利用CNN/RNN等网络结构自动获取特征表达能力,从而实现文本分类。为了解决文本表示,我们对文本做进一步的特征处理,因此引入了词嵌入的概念,在深度学习模型中一个词经常用一个低维且稠密的向量来表示,如下所示:
( 0.286, 0.792, -0.177, -0.107, …. , 0.109, … 0.349, 0.271, -0.642)
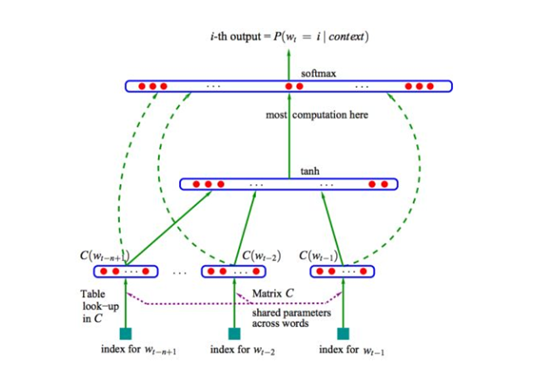
词嵌入也叫word embedding,属于文本的分布式表示。分布式表示(Distributed Representation)是Hinton 在1986年提出的,基本思想是将每个词表达成 n 维稠密连续的向量。相比one-hot编码,分布式表示最大的优点是特征表达能力更强。下图是2003年Bengio提出的 Neural Probabilistic Language Model的网络结构:
词嵌入解决了文本表示的问题,下面介绍基于深度学习网络的文本分类模型,主要包括CNN、RNN、LSTM、FastText、TextCNN、HAN。
1)CNN
卷积神经网络(CNN)是深度学习的入门网络,最早在图像领域取得重要突破。其主要思想是利用卷积操作,用filter在数据上进行滑动,通过多次卷积操作将数据特征进行提取,然后拼接池化层将数据进行降维,最后用全连接层把特征向量进行拼接并送入分类器进行分类。
2)RNN
循环神经网络(RNN)和CNN相比不同点在于,CNN学习空间中局部位置的特征表示,RNN学习的是时间顺序上的特征。因此RNN适合处理具有时间序列特点的数据,例如文本等。RNN网络的当前输出和前面的输出是相关的,也就是说网络会对前面的信息进行记忆并在当前输出的计算中利用前面的信息,其网络的隐藏层之间节点相互连接,隐藏层的输入不仅包括输入层输出而且包括前面隐藏层的输出。
3)LSTM
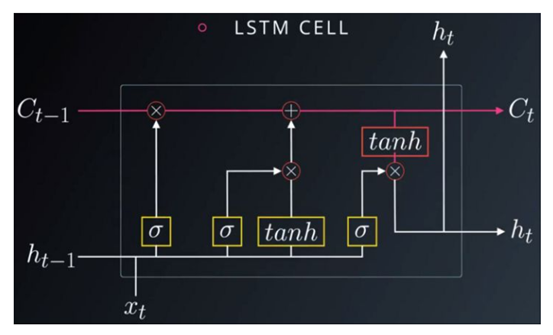
一般的RNN网络存在梯度消失或者梯度爆炸的问题。因为隐藏层不断的乘以权重,随着层数的增加,反向传播时梯度的计算变得困难,因此模型难以训练。为了解决这个问题,LSTM模型出现了,LSTM也叫做长短时记忆网络。其模型的关键在于利用单元状态和更新信息的控制门组成网络单元。其遗忘门用来决定从单元中丢弃什么信息,更新门用于确定在单元中存放什么信息,输出门用来确定输出什么样的值。
4)FastText
FastText是word2vec作者在2016年发表的论文Bag of Tricks for Efficient Text Classification中提出的模型。FastText 结构非常简单,在速度要求高的场景下比较适用,模型图见下:
其思想是把文章中所有词向量(可以加上N-gram向量)直接相加求平均,然后接一个单层神经网络来确定最后的分类。这样做的问题是丢失了太多信息,但是好处在于模型简单可以适用于速度要求高的任务。

5)TextCNN
TextCNN相比FastText的网络结构更加复杂,通过下图中TextCNN的网络结构可以看出,第一层输入是7*5的词向量矩阵,词向量维度是5,句子长度是7,第二层利用三组大小是2、3、4的卷积核,每种卷积核用两个。卷积核在句子上滑动得到激活值,然后接池化层为分类器提供feature map。这里利用max pooling来得到模型关注的关键词是否在整个文本中出现,以及相似的关键词和卷积核的相似度最大有多大。
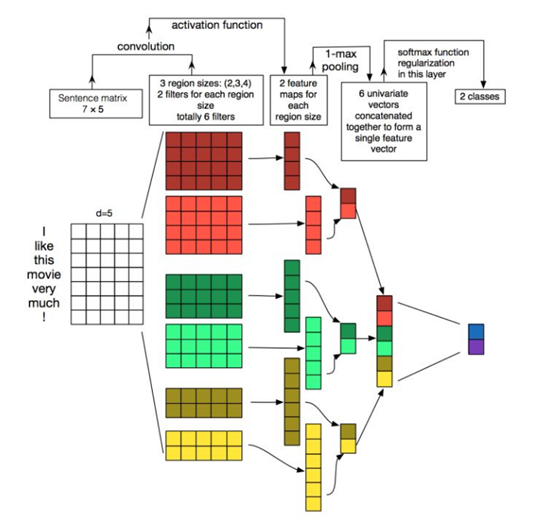
TextCNN相比FastText来说文本信息保留更好,特征表示更全面。但是其全局max pooling层会丢失结构信息,因此文本中更复杂的模式关系难以被发现,而且模型更加复杂对于速度要求更难满足。
6)HAN
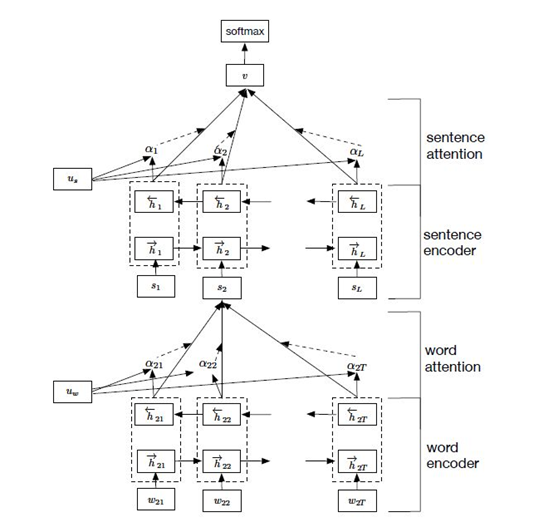
相比于TextCNN,HAN(Hierarchy Attention Network)网络引入了注意力机制,其特点在于完整保留文章的结构信息,同时基于attention结构具有更好的解释性。
HAN模型主要分为两部分,分别是句子建模和文档建模。词向量先经过双向LSTM网络进行编码,结合隐藏层的输出与attention机制,对句子进行特征表示,经过编码的印象量通过时间步点积得到attention权重,把隐向量做加权得到句子向量,最后句子再次通过双向LSTM网络加上attention得到文章的向量输出,最后通过分类器得到文本分类。引入attention机制最大的好处在于直观的解释了各个句子和词对分类类别的重要性。模型结构符合人的由词理解句子,进而理解整个文章的理解过程。
基于keras的文本分类实践
通过介绍文本分类的传统模型与深度学习模型之后,我们利用IMDB电影数据以及keras框架,对上面介绍的模型进行实践。数据集来自IMDB的电影评论,以情绪(正面/负面)进行标记。由于模型的输入是数值型数据,因此我们需要对文本数据进行编码,常见的编码包括one-hot和词嵌入。我们先对数据进行训练集和测试集划分,分别用于模型的训练以及测试。
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding, Dropout, Activation,Flatten, Conv1D, GlobalMaxPooling1D,Input, MaxPooling1D
from keras.layers import LSTM, CuDNNLSTM
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
max_features = 20000
maxlen = 200
batch_size = 32
print('load data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = max_features)
label_train,train_text=read_files("train")
label_test,test_text=read_files("test")
# 建立字典
token = Tokenizer(num_words=max_features)
# 读取训练集,按词频排序,构成字典
token.fit_on_texts(train_text)
print(token.document_count)
print(token.word_index)
x_train_seq = token.texts_to_sequences(train_text)
x_test_seq = token.texts_to_sequences(test_text)
x_train = sequence.pad_sequences(x_train_seq, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test_seq, maxlen=maxlen)
首先我们需要用keras框架搭建模型结构,keras是一个高层神经网络API,其基于Tensorflow、Theano以及CNTK后端,对很多细节进行了封装,便于快速实验。搭建好网络模型后,需要对模型进行编译,确定模型的损失函数以及优化器,定义模型评估指标。然后使用fit函数对模型进行训练,需要指定的参数有输入数据,批量大小,迭代轮数,验证数据集等。下面是对本文提到的模型分别进行训练。
MLP
def BuildMLP(): model = Sequential() model.add(Embedding(output_dim=32,input_dim=max_features,input_length=maxlen)) model.add(Dropout(0.5)) model.add(Flatten()) model.add(Dense(units=256,activation='relu' )) model.add(Dropout(0.5)) model.add(Dense(units=1,activation='sigmoid' )) return model
CNN
def BuildCNN():
# model parameters:
embedding_dims = 50
cnn_filters = 100
cnn_kernel_size = 5
dense_hidden_dims = 200
print('Build model...')
model = Sequential()
model.add(Embedding(nb_words,embedding_dims,input_length=maxlen))
model.add(Dropout(0.5))
model.add(Conv1D(cnn_filters, cnn_kernel_size,padding='valid', activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(dense_hidden_dims))
model.add(Dropout(0.5))
model.add(Activation('relu'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
RNN
def BuildRNN():
embedding_dims = 50
lstm_units = 32
print('Build model...')
model = Sequential()
model.add(Embedding(nb_words,embedding_dims,input_length=maxlen))
model.add(Dropout(0.2))
model.add(CuDNNLSTM(lstm_units, return_sequences=True))
model.add(CuDNNLSTM(lstm_units))
model.add(Dense(1, activation='sigmoid'))
return model
LSTM
def BuildLSTM():
print('build LSTM...')
model = Sequential()
model.add(Embedding(max_features, 128))
model.add(LSTM(128, dropout = 0.5, recurrent_dropout = 0.5))
model.add(Dense(1, activation = 'sigmoid'))
return model
TextCNN
def BuildTextCNN(maxlen=200, max_features=20000, embed_size=64):
comment_seq = Input(shape=[maxlen], name='x_seq')
emb_comment = Embedding(max_features, embed_size)(comment_seq)
convs = []
filter_sizes = [2, 3, 4, 5]
for fsz in filter_sizes:
l_conv = Conv1D(filters=100, kernel_size=fsz, activation='relu')(emb_comment)
l_pool = MaxPooling1D(maxlen - fsz + 1)(l_conv)
l_pool = Flatten()(l_pool)
convs.append(l_pool)
merge = concatenate(convs, axis=1)
out = Dropout(0.5)(merge)
output = Dense(32, activation='relu')(out)
output = Dense(units=1, activation='sigmoid')(output)
model = Model([comment_seq], output)
return model
FastText
def FastText():
model = Sequential()
model.add(Embedding(max_features,embedding_dims,input_length=maxlen))
model.add(GlobalAveragePooling1D())
model.add(Dense(1, activation='sigmoid'))
HAN
def HAN():
sentence_input = Input(shape=(max_features,), dtype='int32')
embedded_sequences = embedding_layer(sentence_input)
l_lstm = Bidirectional(LSTM(100, return_sequences=True))(embedded_sequences)
l_att = AttLayer(100)(l_lstm)
sentEncoder = Model(sentence_input, l_att)
review_input = Input(shape=(maxlen, max_features), dtype='int32')
review_encoder = TimeDistributed(sentEncoder)(review_input)
l_lstm_sent = Bidirectional(LSTM(100, return_sequences=True))(review_encoder)
l_att_sent = AttLayer(100)(l_lstm_sent)
preds = Dense(1, activation='softmax')(l_att_sent)
model = Model(review_input, preds)
总结
| 模型 | 准确率 |
| MLP | 0.85604 |
| CNN | 0.87644 |
| RNN | 0.86344 |
| LSTM | 0.86304 |
| FastText | 0.85805 |
| TextCNN | 0.86906 |
| HAN | 0.86052 |
通过实验结果可以看到每个模型的训练效果,CNN模型的准确率达到最高,而更加复杂的模型效果反而一般,而且在训练耗时方面,CNN以及MLP等模型的训练速度更快,TextCNN以及HAN等模型训练速度相对更慢。实际上在真实的落地场景中,理论和实践往往有差异,理解数据很多时候比模型更重要。通过本文我们将传统本文分类方法以及深度学习模型进行介绍和对比,并利用keras框架对其中的模型进行文本分类实践。今后想要在实际业务中将文本分类模型用好,除了扎实的理论分析之外,还要在大量的业务实践中总结经验,通过实践将模型在业务应用中进行不断优化,才能将把模型在实际场景中落地。