执行摘要
- AI能力提升迅速,但不稳定。
自2025年以来,在用于提升性能的初始训练新技术的推动下,通用AI的能力不断提高,研发人员持续训练性能更优、规模更大的模型。过去一年,研发人员通过“推理时扩展”技术进一步提升了AI的能力,模型可使用更多计算资源,在给出最终答案前生成中间步骤。该技术使AI在数学、软件工程和科学等更复杂的推理任务中呈现出了显著提升。但AI并不能稳定发挥其能力,先进系统处理某些复杂任务时表现出色,处理更简单的任务时反而不如人意。
到2030年之前,AI的发展轨迹尚不确定,但当前的趋势表明持续进步是必然的。研发人员认为算力依然是至关重要的因素,计划为数据中心投资数千亿美元。难以预测AI的能力能否持续快速提升。到2030年之前,有三种可能性:进步放缓或趋于平稳(如受数据或资源的限制)、保持当前的进步速度或进步显著加速(如AI推动AI研究本身)。
- 多层防护利于更稳健的风险管理。
除能力问题外,AI技术还存在多项风险问题,主要分为三类:恶意使用风险、功能异常风险和系统性风险。
技术和制度方面存在挑战,管理AI风险并非易事。在技术层面,新能力的出现难以预测,模型的内部工作原理仍未被充分理解,存在评估误差,无法保证部署前测试的性能完全覆盖实际应用中的性能或风险。在制度层面,研发人员倾向于对重要信息保密,可能导致他们优先考虑发展速度而非风险管理,同时也使组织难以建立管理能力。
风险管理实践包括通过威胁建模识别漏洞、通过能力评估预测潜在危险行为以及通过事件报告收集更多依据。2025年,12家公司发布或更新了前沿AI安全框架文件,对构建能力更优的模型时如何管控风险进行了说明。AI风险管理在很大程度上仍是各组织或企业的自愿行为,但已有少数监管制度开始将部分风险管理实践正式化为法律要求。
技术保障措施不断改进,但仍存在显著局限性。例如,为触发有害输出而实施的攻击会更加困难,但攻击者仍可通过重新描述请求或将请求分解为更小的步骤来获取有害输出。而多层防护(一种“纵深防御”方法)可以使AI更加稳健。
开源权重模型带来了特殊挑战。它们具有显著的研究和商业价值,特别是对资源较少的行为者而言。然而,这些模型一旦发布就无法召回,防护措施更容易被删除,而且攻击者可以在不受监控的环境中使用模型,促使恶意行为更难预防和追踪。
1 AI当前能力
1.1.AI当前能力的局限性
- AI的可靠性存在挑战。
AI能力虽然有所改进,但其可信度存在问题,AI容易在事实和逻辑方面出现基本错误。即使是擅长处理复杂任务的AI,也可能生成实际不存在的引文、传记或事实,这种现象被称为“幻觉”。AI的能力表现也可能不一致,例如,在数学问题的描述中插入无关信息,答案的准确性可能显著下降。多模态技术同样存在这种问题,模型在空间推理任务(如基本的场景物体计数)处理上的能力通常较低。
虽然专业人员的监督可以减轻部分此类风险,但相应地存在过度依赖的危险,即用户因为输出结果表达流畅且自信而信任该结果,但实际内容可能并不正确。如果在医疗和金融等高风险场景中使用AI,无法保证安全性,输出的错误结果可能带来严重后果,因此仍需要人类验证输出内容。
- AI难以处理长期任务和应对意外情况。
AI在需要长期规划、多个步骤中保持连贯策略以及适应意外情况的任务上也存在挑战。随着任务变长,AI往往会忘记进展,无法可靠地处理输入。例如,简单的网站弹窗广告可能影响整个任务的结果。大规模评估证实了这一模式,在软件开发中,最强大的系统在持续两个多小时的任务上的成功率仅为50%,如果要达到80%的成功率,需要将任务限制在25分钟内。目前,AI处理长期任务或复杂任务的可靠性仍存在挑战。
- 与现实世界的交互仍具有挑战性。
AI的能力难以转化为机器人技术,现实世界的复杂性给技术带来了挑战。最近的进展集中在视觉-语言-动作(VLA)模型上,目的是使机器人能够遵循自然语言指令、解释多模态传感数据并生成运动指令。当前,π0.5模型和双子座机器人(Gemini Robotics)等先进的模型可以解释简单的口头指令,如“打扫厨房”,并在可控的实际环境中执行多个步骤。但当前的VLA模型在处理不常见形状的物体和意外事件时,能力表现不佳。确保此类系统能够安全可靠地运行,以最大限度地减少人身伤害或财产损失的风险,并在各种环境中表现良好,仍需要进一步研究。
- 不同语言和文化场景中的表现能力不一致。
通用AI的能力在不同的语言和文化场景中存在差异。英语场景中的任务处理能力最强,说明大多数训练数据来自英语国家。例如,一项针对83种语言的AI模型评估发现,使用非拉丁字母的语言和数字资源有限的语言的能力表现明显较低。另一项研究中,AI正确回答了79%关于美国日常文化的问题,但仅正确回答了12%关于埃塞俄比亚文化的问题。还有一项研究发现,当前模型在高资源语言中“推理”更有效,可能会扩大语言之间的能力差距。除了语言和文化之外,地理和社会经济层面也存在此类问题。在推荐任务中,模型对于处于劣势的地点的推荐比例偏低,例如,要求推荐餐厅,AI可能不会推荐贫困地区的餐厅,并且在低收入国家相关的事实问题上,能力表现会下降。评估基准本身对于英语场景的严重偏向加剧了不平等,形成了低资源语言场景系统性研究不足和优化不足的生态系统。
1.2.最新进展
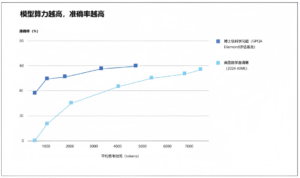
1.3.依据不足
- 基准测试无法准确预测现实场景中的能力。
基准测试的完整性日益受到关注,许多能力评估依赖于标准化的基准测试。然而,许多模型可能使用了相同的基准测试的数据进行训练,这一问题被称为“数据污染”,但大多数开发者目前并未追踪或披露这一情况。这可能导致能力分数虚高,不能反映模型的真实能力,反映的只是其记忆答案的能力。当前评估实践的另一个局限性是,AI依赖于受控实验室环境中的自动化测试,这往往高估了AI在动态的现实世界环境中的实际效用。例如,一项研究发现,虽然AI智能体能够生成功能代码,但代码仍然需要大量的人力来修复文档、格式和质量方面的问题,才能在实际项目中使用。为了应对局限性,专门的评估科学正在兴起,倡导采用严格的方法学,确保外部有效性并更好地预测AI在现实世界中的能力。例如,最近的基准测试开始衡量AI在具有经济价值的任务和现实世界远程工作中的能力。
- AI增强人类能力的方式尚不确定。
一致地衡量AI的实际效益具有挑战性,任务处理能否成功既取决于特定任务情况,也取决于用户利用AI完成任务的技能,这意味着实验室的测试结果往往无法预测AI在现实世界中的价值。例如,一项研究表明,模型的独立准确性并不是人类-AI团队能力的可靠预测指标。许多研究证实了使用AI带来的积极提升。然而,最近的一项研究发现,软件开发人员认为AI帮助他们提高了生产效率,但在复杂的编码任务中,经验丰富的程序员使用AI后的效率反而降低了19%。
1.4. 2030年AI能力预测
- 算力、算法、数据三个方面的投入将驱动AI的进步。
算力指用于AI开发和部署的计算资源,包括硬件、软件和基础设施。算力增加,就能在更大的数据集上训练更大的模型(见图1.2),从而在各种任务中表现出更强的能力。算力也可在部署期间使用,提高AI输出的质量。算法进步提高了计算资源转化为模型能力的效率,还能实现质的新能力。如果模型使用更少的训练或推理算力达到相同的能力,则该模型比另一个模型更高效。例如,GPT-5比GPT-4.5更高效,因为GPT-5的训练算力可能更少,但在一系列基准测试(如包含研究生水平科学问题的GPQA Diamond)中表现优于GPT-4.5。数据指用于训练模型的信息,包括来自网络的文本、图像和人工生成的合成数据。数据的数量和质量都会影响模型能力的进步。
近年来,算力、算法和数据都显著增强。对于算力最密集的模型,训练算力每年增长约5倍。如果该趋势持续到2030年,模型的训练算力可能会比现在大约多3000倍。根据2024年的一项研究,算法效率每年大约提高2-6倍,减少了获得同等能力所需的算力。训练数据集从数十亿个数据点扩展到数万亿个,年平均增长率约为2.5倍。新的推理时扩展方法进一步提高了模型训练后的能力,这与主要依赖更多训练算力和更大数据集的传统方法不同。
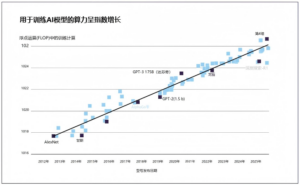
- 关键投入的指数级增长在技术上可行。
到2030年左右,AI关键投入(算力、算法和数据)的指数级增长在技术上是可行的。对生产能力、投资和技术进步等限制的分析表明,每个前沿模型的算力可以继续以当前速度增长,而不会遇到芯片制造或能源生产方面的瓶颈。为支持这种扩展,各企业对算力基础设施进行了大量投资。例如,Meta和OpenAI分别宣布计划投入650亿美元和5000亿美元。这些投资还支持推理算力的增加以及研发的计算资源,后者占AI公司算力支出的主要部分。
历史数据显示,算法效率的提升每年可额外带来2-6倍的能力提升。然而,专家们对这一提升的可持续性存在分歧,尤其是2030年以后。分歧集中在能源限制和高质量数据稀缺是否会迫使当前的开发方法发生根本性变化。
- 专家预测,AI的问题解决能力将提升。
AI在数学推理方面的能力取得了快速提升。专家预测,2027-2028年,推理类问题的解决能力将取得重大进展。在预测研究院(Forecasting Research Institute)的一项研究中,专家预测到2027年,AI在本科水平的数学基准测试FrontierMath问题上达到55%准确率的概率为50%,到2030年达到75%准确率的概率为50%。然而,专家对于AI是否能在数学和编程之外的领域达到相应的水平这一问题存在分歧。推理技术影响相关的大多数依据仍然局限于数学和编程等领域,需要研发人员评估AI在法律和科学等新领域中的推理能力,确定推理技术的可行范围。
AI在自主软件执行方面也取得了快速进展。2019年只能完成专业人员几秒钟完成的任务的AI,现在能够以80%的成功率完成专业人员30分钟才能完成的软件工程任务。在过去六年中,AI以80%的成功率完成任务的最大持续时间大约每七个月翻一番(见图1.3)。到2027-2028年,预计可以自主完成长达数小时的软件项目,到2030年预计可以完成长达数天的项目。但是,80%的成功率可能低于许多专业环境中部署所需的标准。而且基准测试任务与现实世界的软件工作存在系统性差异,AI能力的进步可能被夸大。例如,AI的测试环境不具备资源限制、信息不完整或多代理协调等混乱情况。
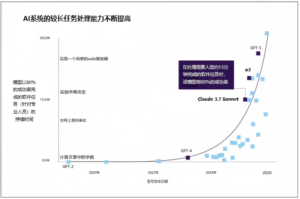
- 专家对AI在专业领域能力提升的程度和时机存在分歧。
预计到2028-2030年,AI的能力将在许多专业领域得到提升,但专家对提升的程度和时机问题存在分歧。AI在某些科学基准测试方面的表现已经超过了研究生水平,部分AI超过了博士水平的专家。按这种趋势推断,在未来几年内,AI可能在多个专业科学领域达到研究水平的表现。
AI的整体性能稳步提升的同时,可能意外出现特定能力。例如,AI在被提示逐步工作后,在大数加法方面的能力出现了显著提升,而并非是随着模型规模的扩大而逐步提升。研究人员将这种突然的跃升称为“涌现能力”。这使AI的发展规划更具挑战,很难预测AI何时会突然获得具有战略意义的认知能力。研究人员尚未确定新的预测方法是否会使涌现能力更可预测,对能力跃升的不可预测的程度存在分歧。
1.5.可能减缓AI能力提升的瓶颈
- 额外算力的经济回报可能递减。
进行更大规模的投资才能维持相同的能力提升速度,所以仅靠资源扩展可能导致经济回报递减,进而减缓AI的进步。当前的前沿AI训练运行仅计算资源一项就已花费约5亿美元,下一代模型预计需要10-100亿美元。与此同时,消费者对AI的平均信任度仍然较低,许多企业难以成功采用AI,数千亿美元的大规模投资将成为无确定回报的赌注。如果大规模投资未能产生收入(见图1.4),企业可能会大幅减少扩展投资。如果没有持续的投资,训练算力的增长将大幅放缓,这可能给能力提升设置了潜在的上限。在这种情况下,能力提升将更多地依赖于算法进步,而不仅仅是规模扩展。
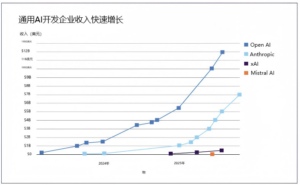
图 1.4:2023 年以来,AI 主要企业的预计年化收入。来源:Epoch AI,2025 年。
- AI辅助研究自动化对AI研发的加速作用尚不明确。
针对未来十年AI辅助研究自动化是否能显著加速AI的进步这一问题,各专家存在分歧。在一项试点研究中,研究人员询问预测专家,未来几年AI的进步是否有可能将六年(2018-2024年)的发展历程压缩至两年。AI预测专家给出的概率的中位数为20%,而专业的通用预测师估计仅为8%。AI在为期一个月的研究项目中表现优于研究人员,在此情景下,预测者估计的概率上升至18%。有人假设,在这种情景下,AI研究可能会更快实现完全自动化,从而极大地加速AI的进步。
目前关于AI辅助研究自动化的实证依据,既有正面的,也有负面的。在一项衡量AI研究工程能力的基准测试中,AI在两小时任务上的表现优于人类,但在八小时任务上的成功率较低。该测试具有启发意义,但并未考虑到AI研发中的现实瓶颈,例如,研究人员必须应对模糊的目标,需要很长时间才能确定某项算法改进是否真正提升了AI的性能。这种不确定性给政策制定者和机构的规划带来了极大的挑战,如果每一项加速AI研发进程的AI进步都能促进下一项研发的进步,那么数十年的发展成果可能在短短几年内实现。
- AI的商业部署往往无法跟上能力提升的速度。
当前的AI可在受控环境中展现出高级能力,但不同行业的采用速度不同。AI编码助手在发布后的1至4年内便在软件开发人员中得到了广泛采用。相比之下,许多行业在部署AI时面临着巨大障碍。例如,在研究环境中达到人类水平诊断准确率的医疗AI,通常需要额外3至5年的时间才能通过监管审批、完成临床整合和医生培训,进而实现广泛部署。
专家预测,到2030年,自动驾驶技术的部署仍将受到限制,障碍包括文化阻力、基础设施要求和监管阻力。中小企业雇佣了全球60%的劳动力,面临着特殊的挑战,技术专业知识有限、计算基础设施不足以及高昂的整合成本,这些都可能延缓企业对AI的采用。除此之外,先进半导体的出口管制以及不同司法管辖区之间存在差异的监管框架等地缘政治因素,可能也会造成阻碍,既影响AI能力的发展,也阻碍AI的部署。
然而,专家对于部署差距是否会迅速缩小或长期存在仍有分歧。一方面,某些行业对AI的快速采用表明,如果企业或组织能看到生产力提升和竞争优势,部署速度将会加快。而另一些研究人员则认为,无论技术进步如何,组织和监管层面的适应本质上都需要数年时间。这种分歧对政策制定的时机具有重要意义,为快速部署的AI能力而制定的政策可能为时过早,而假设采用缓慢部署的政策则可能不足以合理管理相关风险。