一、前言
随着物联网的普及和人工智能技术的发展,越来越多的物联网资产及服务暴露在互联网中,如何对海量的物联网资产进行监控是值得深入研究的。监控物联网资产既需要持续的运营积累,同时也需要对物联网资产具备敏锐的挖掘能力。在往期的物联网资产研究系列文章中 已经讨论过关于物联网资产特点梳理以及资产识别的内容,这些对于物联网资产的监控都提供了很大的支持。此外,由于物联网资产的数据量大以及人工成本高的现状,本文提出基于KDTree方法的物联网资产自动化监控方案来更高效快速的对物联网资产进行挖掘并找到新的资产。KDTree方法是对K维空间数据进行树形结构存储从而加快在数据中进行检索的速度,其主要优势在于计算开销小,适用于大规模的高维数据。
二、物联网资产监控
物联网资产监控的目标旨在完成对现有已知的物联网资产信息进行梳理之后,通过不断的对新采集的资产数据进行监控,挖掘未知的新型物联网资产设备,这对于开展物联网安全研究以及升级指纹库等方面都具有积极意义。
2.1 物联网资产监控方案现状
对于每日收集到的海量物联网资产服务信息,采用人工对比的方式进行监控是不现实的。为了实现自动化监控,一种方法是对采集到的数据和历史数据进行相似度匹配,一旦匹配到相似的历史数据则找到了物联网资产类型,否则采集到的数据是疑似的新型物联网资产。这种典型的监控数据的方案如下图所示。
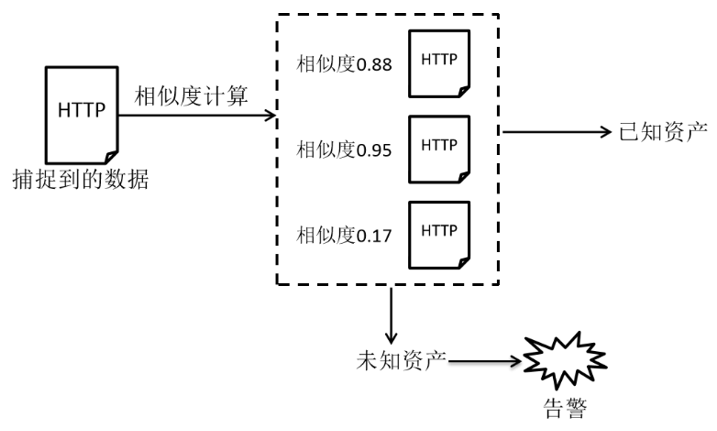
基于相似度计算的监控方案
基于相似度计算的监控方案优点是能够比较精确地对采集的新数据和历史数据进行对比,匹配相似度,但是缺点在于随着历史数据的逐渐增大,海量的历史数据叠加数据的长度不稳定(数据可能很长)会导致对比匹配速度越来越慢,在性能效果上表现不足。此外选择相似度计算的方式也会对最终的效果有一定影响。
为了能够更快更高效的在海量历史数据中匹配采集的新数据,可以将资产服务数据进行向量化抽象提取,这样既避免了资产服务数据长度不一致带来的数据无法对齐的问题,也解决了资产服务数据中可能存在特殊编码不可读的困难。
2.2 基于KDTree的物联网资产监控方案
本文研究采用的基于KDTree方法的物联网资产自动化监控方案。首先根据积累的历史数据以及人工标记过的物联网资产,可以发现相同资产的服务信息具备很高的相似性。例如下列两个物联网资产的都属于NETGEAR厂商设备服务。
HTTP/1.0 401 Unauthorized WWW-Authenticate: Basic realm="NETGEAR WGR614v10" Content-type: text/html <html> <head> <meta http-equiv='Content-Type' content='text/html; charset=utf-8'> <title>401未授权</title></head> <body><h1>401未授权</h1> <p>到本资源的访问被拒绝,您的客户端未提供正确的认证。</p></body> </html>
HTTP/1.0 401 Unauthorized WWW-Authenticate: Basic realm="NETGEAR XWN5001" Content-type: text/html <html> <head> <meta http-equiv='Content-Type' content='text/html; charset=utf-8'> <title>401未授权</title></head> <body><h1>401未授权</h1> <p>到本资源的访问被拒绝,您的客户端未提供正确的认证。</p></body> </html>
那么对两个资产数据通过向量化处理之后得到的资产向量表示,我们发现两个资产数据对应的资产向量也是非常相似的,具体如下。
| 资产 | 资产向量 |
| NETGEAR WGR614v10 | [0.32, 0.56, 0.75, …. 0.86, 0.72, 0.01… 0.12, … 0.49] |
| NETGEAR XWN5001 | [0.32, 0.56, 0.75, …. 0.29, 0.72, 0.55… 0.19, … 0.49] |
在往期文章中已经介绍过如何对资产数据进行向量化提取,提取过程如下图所示。

资产数据向量化提取
因此我们可以选择对历史数据以及采集的新数据分别进行向量化提取,得到每个资产数据的向量化表示。为了快速的对向量化资产数据进行对比,我们采用KDTree构建向量表示的树形结构,例如下图。
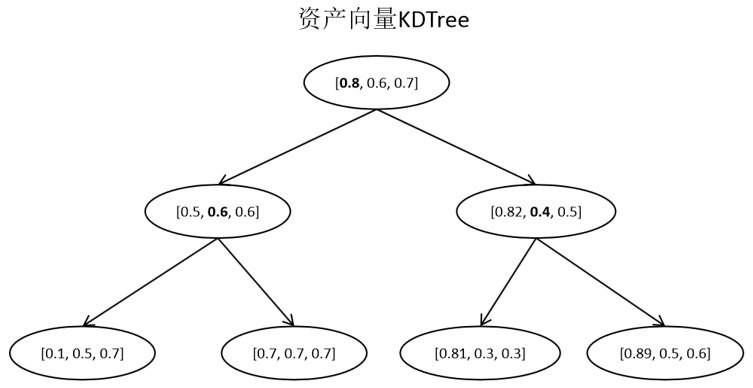
构建基于物联网资产的KDTree
我们在处理构建资产向量KDTree时选择如下步骤进行计算。
- 对每个资产数据向量处理成500维特征,每一维度特征都归一化到0至1的范围内
- 选择500维特征中方差最大的特征维度作为分割特征,例如上图第一维特征。
- 将该维度特征中的中位数作为特征的分割点,将数据中该维度特征小于分割点的数据划分为左子树,将数据中该维度特征大于分割点的数据划分为右子树。
- 递归上面的计算和划分过程,直到所有的数据都被建立成为KDTree的所有子节点为止。
实际上选择用KDTree方法作为资产向量匹配的方式和典型的KNN算法是如出一辙的,在我们对所有的物联网历史数据进行向量化并构建KDTree之后,我们每当捕捉到新的资产数据,都将新数据的向量在KDTree中进行查找,找到与之距离最近的向量并进行计算。当历史资产数据中存在和新数据相同或者相似的数据时,我们便更新KDTree。否则就进行告警,得到了一个未知的疑似新型物联网设备的资产信息,便于后续的研究和追踪。
三、资产监控自动化
为了将物联网资产监控过程做到自动化,主要是将监控期间的数据流以及服务搭建完善。这其中包括捕捉新数据自动入库,处理新数据并利用KDTree方法进行已知资产和未知新型资产判别,数据以及模型的自动更新,对监控到的新型物联网设备进行告警,定期统计告警问题并反馈优化。
四、总结
本文从物联网资产数据的监控出发,通过对比现有相似度匹配方案以及提出的基于KDTree的物联网资产监控方案,来应对现状方案中资产数据数量大以及检测效率低等问题。通过自动化监控资产的流程,将暴露在互联网上的新型物联网资产进行监控并告警。这对于物联网资产数据的长期运营以及安全研究来说,是一项有意义的工作。目前该监控方案已经应用于实际生产中,并在持续监控新型物联网资产信息。未来在物联网的安全研究中,我们会继续深入资产识别以及资产威胁挖掘等方向,落地更多的物联网安全研究工作。