深度学习模型具备天生的安全隐患,近些年的研究表明对输入深度学习模型的数据样本进行特殊处理后,可以导致模型产生错误的输出。因此这样的对抗样本实现了攻击深度学习模型的效果。如果我们在神经网络模型的训练过程中,采取数据投毒的方式对模型植入后门,也可实现攻击模型的目的。
背景
人工智能是如今备受关注的领域,随着人工智能技术的快速发展,基于深度学习模型的应用已经进入了我们的生活。伴随着神经网络的发展和应用的普及,深度学习模型的安全问题也逐渐受到大家的关注。但是深度学习模型具备天生的安全隐患,近些年的研究表明对输入深度学习模型的数据样本进行特殊处理后,可以导致模型产生错误的输出。因此这样的对抗样本实现了攻击深度学习模型的效果。如果我们在神经网络模型的训练过程中,采取数据投毒的方式对模型植入后门,也可实现攻击模型的目的。从对抗样本到神经网络模型后门植入,攻击者的攻击手法变化越来越多,攻击成本越来越低,这对大量的深度学习模型和应用来说是很有威胁的。本文从后门攻击的角度浅谈神经网络中的安全问题以及有关的威胁检测方式。
对抗样本攻击
对抗样本是一种能够让模型产生错误判断的数据样本。针对不同的机器学习模型应用场景,对抗样本既可以是输入模型的图片,也可以是语音、文本等。例如下图,数据来源于CIFAR10数据集,左边是数据集的正常图片,右边是基于不同攻击方法生成的对抗样本,虽然肉眼看起来没有明显区别,但是模型对其分类结果却差别很大。

对抗样本往往是指输入机器学习模型的样本在经过模型判别之后产生的输出O与对应的正常样本输入到模型产生判别得到输出的结果O’是截然不同的。对抗样本与真实样本之间的差别在肉眼看来几乎是无法分辨的。我们可以在2D特征空间里看一下对抗样本的例子:
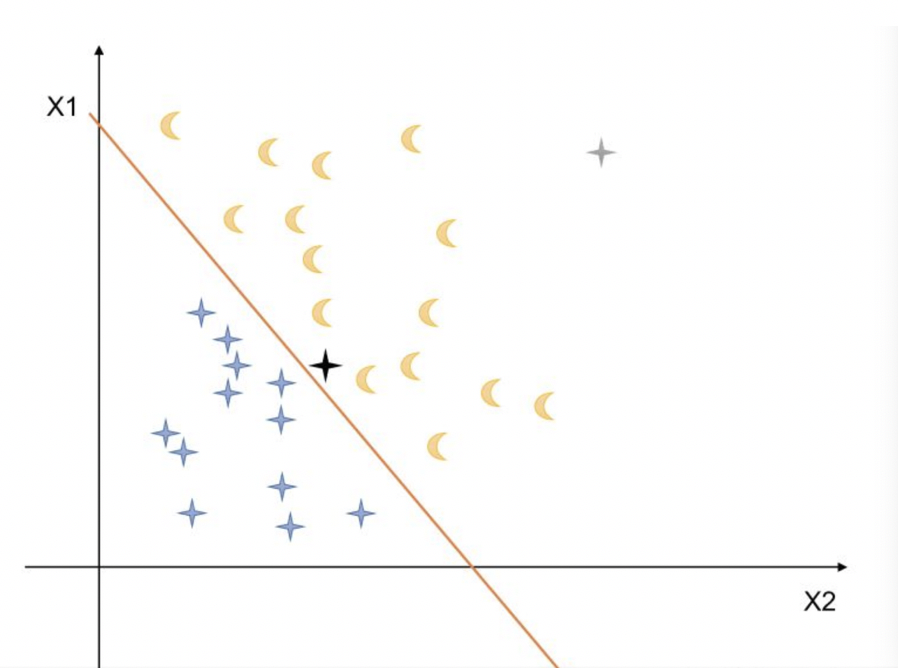
上图中有黄色和蓝色两类样本数据,基于样本的特征X1和X2(例如X1是长度,X2是高度)对数据进行建模,采用机器学习模型进行训练,得到的分类决策边界是橙色的直线,模型能够将黄色和蓝色的样本数据分开。如果此时利用PGD或者CW一类的对抗样本生成算法,基于蓝色样本生成了一个黑色样本,该样本属于黄色样本的空间区域,因此我们的模型在对其进行分类时会出现错误的判断,导致错误分类。此时攻击算法所需要做的实际上就是尽可能小的对X1,X2的值进行改变,同时让对抗样本刚好跨过模型决策边界。通过这个例子,我们只是对线性可分数据以及利用简单的线性模型进行分类。真实场景下我们处理的数据以及应用的模型会更加复杂,因此数据的特征空间分布很会变的复杂.而实际上生成对抗样本需要利用模型的局部线性来实现。当前对对抗样本的研究表明,基于优化的方法进行对抗样本生成主要是最大化模型输出,同时最小化样本特征的改变,采用的技术就通常是梯度下降法并进行优化;基于雅可比矩阵进行对抗样本的生成主要是找出对模型输出影响最大的输入进行改变,从而实现样本空间跨越模型分类边界。
神经网络后门攻击
对抗样本通过攻击算法在样本数据上进行改变实现攻击模型的目的,而Trojan Neural Network(TNN)通过改变模型参数同样可以使模型错误分类的攻击效果。从数据和模型两种角度都能在神经网络模型中植入后门。后门攻击只有当模型得到特定输入时才会被触发,然后导致神经网络产生错误输出,因此非常隐蔽不容易被发现。在大型数据集上进行机器学习模型的训练,通常需要多方基于梯度共同进行训练;在模型训练以及使用的整个过程中需要多次对梯度进行更新,因此在更新模型参数的过程中多方都可能会对机器学习模型进行攻击。
当前研究表明TNN攻击能够利用对训练数据投毒的方式进行攻击,也可以不通过训练数据进行攻击。如果选择不通过训练数据进行攻击,TNN攻击一般会选择一个触发样本,基于触发样本生成一组样本对模型进行训练。训练TNN的目标函数通常是最小化模型在正常样本中的误差,并且最大化模型在木马触发样本中的误差。与对抗样本攻击一样,TNN攻击也可以根据木马触发样本分为有目标攻击和无目标攻击。如果想要对TNN攻击进行防护,一种方式是重新建模,也就是对模型进行重新训练,另一种则是建立检测模型对TNN攻击进行检测。
检测方法
关于神经网络中后门攻击的检测在最新的研究中,2019年S&P上面已经提出了一些检测方法。例如,在下图中说明了该神经网络后门攻击检测方法的抽象概念。它表示了一个简化的一维分类问题,其中包含3个标签(label A for circles, B for triangles, and C for squares)。图中形象的显示了数据样本在输入空间中的位置,以及模型的决策边界。被攻击的模型有个恶意触发会导致分类结果为A。由于后门的存在触发在属于B和C的区域中产生另一个维度。任何包含触发的输入在触发维度中都有更高的值(被攻击模型中的灰色圈),因此会被分类为A,而不会导致分类为B或C。
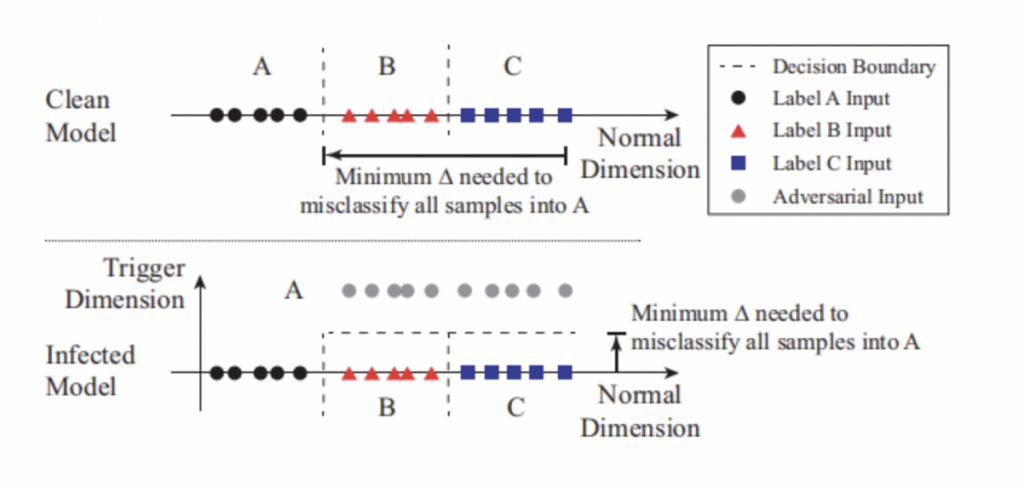
后门区域在一定程度上减少了将B和C样本错误分类到被攻击标签A所需的修改量。如果通过测量将来自任何区域的任何输入改变到被攻击目标区域所需的最小扰动量来检测是否为被攻击的类别,是一种检测手段。也就是计算将任何标签为B或C的输入转换为被攻击标签A的输入所需的最小扰动量的值,在具有触发的区域中,无论输入位于空间的任何位置,将输入分类为被攻击标签A所需的扰动量受恶意触发的限制。被攻击的模型具有一个“触发维度”的新维度,因此对标签B或C的输入进行一定的扰动,都可能被错误地分类为A。
检测神经网络后门的具体方法是在受攻击的模型中,与其他未受攻击的标签相比,对受攻击标签的错误分类所需的修改更小。因此,我们遍历模型的所有标签,并确定是否需要对任何标签进行极小的修改就能实现错误分类。检测过程概括为以下三个步骤。
步骤1:对于给定的标签,将其视为目标后门攻击的潜在目标标签。采用一种优化方案,以找到将所有样本从其他标签误分类到该目标标签所需的“最小的”触发。
步骤2:对模型中的每个输出标签重复步骤1。对于一个具有N个标签的模型,会对应产生N个潜在的“触发”。
步骤3:在计算完N个潜在触发后,用每个触发候选数值来度量每个触发的大小,即触发要进行多少扰动。采用异常点检测算法来检测是否有任何触发候选对象比其他的候选都要小。异常值也就是触发的后门,该触发的对应的目标标签也就是后门攻击的目标标签。
总结
人工智能现有的发展已经不仅限于算法的研究和优化理论的研究,人工智能安全研究同样值得期待。目前神经网络后门攻击作为新型AI安全威胁,同人工智能技术的其他安全性问题一样,已经成为了安全领域的研究热点。从对抗样本的生成到神经网络的后门植入,都是攻击者攻击手段多样化的标志, 这意味着对攻击场景的防御框架建设也应融入对AI的安全防护手段。在未来的人工智能发展中,市场上对AI模型算法安全性能的要求一定会推动检测模型漏洞技术的落地以及安全防御框架的发展,未来可期。
参考文献
[1] Q. Wang, W. Guo, K. Zhang, A. G. O. II, X. Xing, X. Liu, and C. L. Giles, “Adversary resistant deep neural networks with an application to malware detection,” in Proc. of KDD, 2017
[2] Y. Liu, S. Ma, Y. Aafer, W.-C. Lee, J. Zhai, W. Wang, and X. Zhang, “Trojaning attack on neural networks,” in Proc. of NDSS, 2018.
[3] Y. Sun, X. Wang, and X. Tang, “Deep learning face representation from predicting 10,000 classes,” in Proc. of CVPR, 2014
[4] B. Wang, Y. Yao, S. Shan, H. Li, B. Viswanath, H. Zheng, and B. Y. Zhao, “Neural cleanse: Identifying and mitigating backdoor attacks in neural networks,” in Proceedings of the 40th IEEE Symposium on Security and Privacy, 2019